[DeepLearning.AI] Course3.추가 Structuring Machine Learning Projects
Structuring Machine Learning Projects (Course 3 of the Deep Learning Specialization)
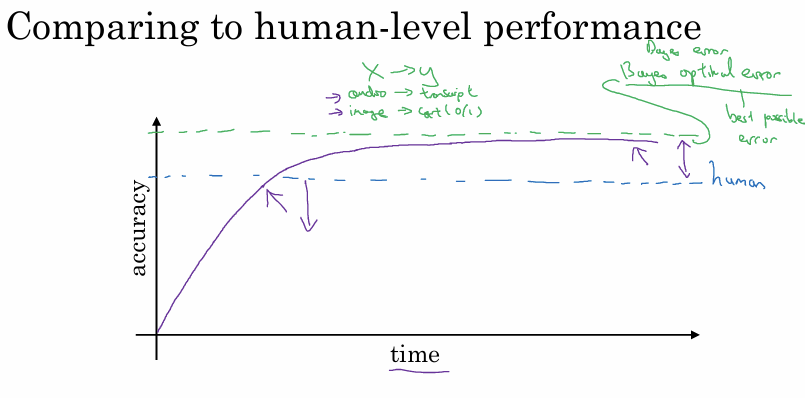
머신러닝 모델의 성능은 사람 수준에 근접할 때까지는 빠르게 향상되지만 사람을 뛰어넘은 이후에는 그 속도가 느려진다.
사람 수준을 넘어서면 발전이 느려지는 이유:
한계 근접:
이미지 인식이나 음성 인식 등 사람이 잘하는 태스크의 경우 사람의 성능이 이미 베이지안 최적 오차에 매우 근접해 있어 더 개선할 여지가 적다.
도구의 부재:
알고리즘이 사람보다 성능이 낮을 때는 성능을 높일 수 있는 명확한 방법들이 존재하지만 사람을 넘어서면 이러한 방법들을 적용하기 어려워진다.
사람보다 성능이 낮을 때 활용 가능한 전략
라벨링
오차 분석:
알고리즘이 틀린 예시를 사람이 직접 확인하여 왜 틀렸는지 분석한다.
편향/분산 분석:
사람의 성능을 기준으로 삼아 편향과 분산을 얼마나 줄여야 하는지 더 파악한다.

Bayes Optimal Error:
데이터 자체의 노이즈 등으로 인해 도달할 수 있는 이론적 최소 오차. 숙련된 전문가 팀의 성능
Avoidable Bias:
학습 오차와 베이지안 오차 간의 차이.
Variance:
학습 오차와 개발 오차 간의 차이.
분석이 어려운 경우:
만약 학습 오차가 0.3% 개발 오차가 0.4%로 사람의 오차(0.5%)보다 더 낮아졌다면 문제가 복잡. 이때는 Overfitting이 발생한 것인지 아니면 베이지안 오차가 실제로 매우 낮은 것인지 판단할 정보가 부족해진다.
인간의 최고 성능(0.5%)을 넘어선 뒤 베이즈 오차를 찾는 방법
진짜 베이즈 오차의 위치를 알 수 없게 되면서 Avoidable Bias을 계산할 수 없고 성능 개선 편향, 분산 기준을 모른다.
정확한 Bayes 오차를 아는 건 사실상 불가능하고 근사를 사용한다.
1. 전문가 합의 기반 노이즈 분석
입력 x가 너무 애매해서 사람조차도 확신을 갖고 항상 같은 라벨을 줄 수 없는 구간이 데이터 안에 존재한다.
센서 노이즈: 카메라가 흔들림, 저조도, 저해상도 등으로 깨진 이미지
저화질, 손상: 압축 artifact, 잘린 이미지 등으로 정보가 부족함
본질적으로 애매한 경계: 약간만 병이 시작된 의료 영상처럼 전문가들 사이에서도 의견이 갈리는 구간
사람도 못맞추는 구간을 하한으로 본다
전문가 여러 명이 본 뒤에도 0.3% 정도는 끝까지 합의가 안 된다면 베이즈 오차는 최소한 그 이상일 가능성이 크다고 본다.
2. SOTA 모델 군집 수렴
서로 다른 구조(CNN, 트리 기반, ViT, 앙상블 등)의 SOTA 모델들을 충분히 튜닝했을 때 에러가 비슷한 값으로 수렴하면 그 공통 에러 수준을 실질적 베이즈 오차 근사로 쓴다.
베이즈 에러로 수렴인지 아니면 딥러닝 최적화의 공통 한계인지?
여러 모델의 에러는 알고리즘 문제가 아니라 데이터 자체의 한계일 가능성이 높다.
추가로
검증할 수 있는 방법으로 Fano’s Inequality 가 있다. Fano 부등식은 베이즈 에러로 수렴인지 아닌지를 추정한다.
Fano 부등식은 Bayes Error에 대한 lower bound
\[P_e \ge \frac{H(Y|X) - 1}{\log |Y|}\]입력 데이터 $X$에 대해 정답 $Y$가 가지는 본질적인 불확실성이 존재한다면 어떤 최적화 알고리즘을 사용하더라도 그 오차 아래로 내려갈 수 없다
만약 추정 가능한 상호정보량 하한을 통해 계산한 Bayes Error 하한이 관측된 에러율과 매우 근접하다면 Bayes Error
반대로 하한이 관측 에러보다 현저히 낮다면 Bayes Error에 도달했다고 말할 수 없다. 모델 설계나 학습 과정의 개선의 여지가 남아있다.
느슨한 경우가 많아 결정적 판별은 불가