[논문정리] InstantID: Zero-shotIdentity-Preserving Generation in Seconds
InstantID: Zero-shotIdentity-Preserving Generation in Seconds(2024).Qixun Wang, Xu Bai12, Haofan Wang, Zekui Qin12, Anthony Chen, Huaxia Li, Xu Tang, and Yao Hu.arXiv
InstantID는 한 장의 얼굴 이미지만으로도 동일 인물을 다양한 스타일로 생성하는 기술이다.

- 이미지 생성 기술 발전
- Diffusion 모델 등장
- 개인화 생성 수요 증가
최근 diffusion 기반 이미지 생성 모델이 급격히 발전했다. 특히 개인화된 이미지 생성, 즉 특정 인물을 유지하면서 이미지를 생성하는 기술이 중요해졌다.
하지만 얼굴 정체성을 유지하는 것이 매우 어렵다. 텍스트만으로는 얼굴 특징을 정확히 표현하기 어렵습니다.
기존에는 DreamBooth나 LoRA 같은 fine-tuning 기반 방법이 사용되었다.
이들은 높은 성능을 보이지만 학습이 필요하다.
시간도 오래 걸리고, 여러 장의 이미지가 필요하다. 실시간 사용에는 적합하지 않습니다.
두번째 방법으로 fine-tuning 없이 사용하는 방법도 등장했다. 대표적으로 IP-Adapter가 있다.
하지만 이 방법은 얼굴 유사도가 낮다는 문제가 있다. 같은 사람처럼 보이지 않는 경우가 많다.
이를 해결하기 위해 InstantID가 제안되었다. 핵심은 한 장의 이미지로 높은 정체성 유지하는 것이다.
Plug & Play, Zero-shot 으로 이 모델은 추가 학습 없이 바로 사용할 수 있다.
기존 diffusion 모델에 쉽게 붙일 수 있다.
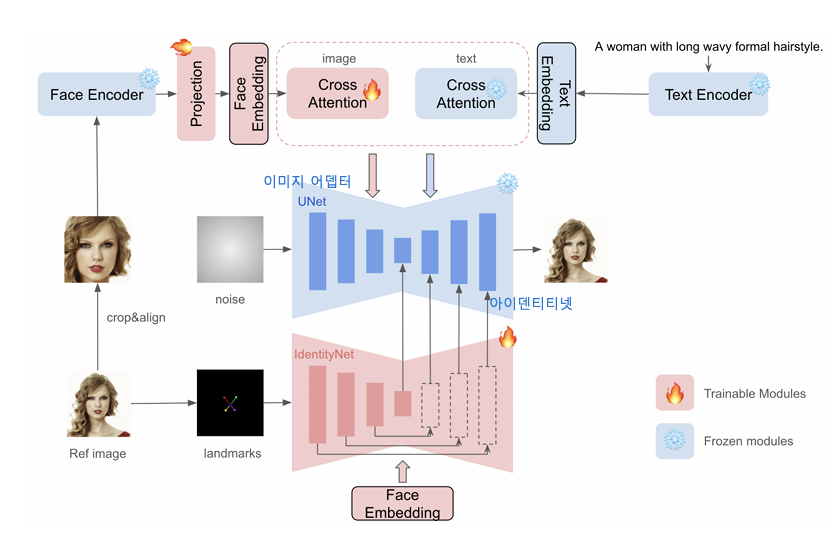
오른쪽 위에 텍스트 조건과 왼쪽 얼굴 정보를 어떻게 분리, 결합해 UNet 기반 확산 생성과정에 주입하는지 시각화한다.
사전 학습된 확산 모델에 소형 학습 가능한 어뎁터와 face-id 임베딩을 추가해 1장 참조 이미지로 튜닝 없이도 제로샷으로 빠르게 높은 신원 충실도의 이미지를 생성하도록 설계된 플러그앤플레이 방법이다
ArcFace 기반의 강력한 특징 추출과 IdentityNet을 통한 구조적 제약을 결합하여 실시간 서비스에 적용 가능한 수준의 압도적인 효율성과 정교함을 동시에 달성했다
전체 구조는 세 가지 핵심 모듈로 구성된다. 각각 역할이 다르다.
Face Encoder
- 얼굴 특징 추출, 강력한 의미론적 추출
먼저 얼굴 인코더는 사람의 얼굴 특징을 벡터로 변환한다. 이 정보가 정체성을 결정한다.
기존의 CLIP 이미지 인코더는 스타일이나 색상 등 모호한 정보를 캡처하는 한계가 있습니다.InstantID는 안면 인식에 특화된 ArcFace 모델을 사용하여 얼굴의 고유한 특징을 매우 정교하게 추출합니다.
Image Adapter
- cross-attention, 시각적 프롬프트 주입
Image Adapter는 이 정보를 diffusion 모델에 전달한다. cross-attention 구조를 사용한다.
추출된 얼굴 임베딩을 Decoupled Cross-Attention 메커니즘을 통해 확산 모델(UNet)에 주입합니다.이 모듈은 텍스트 프롬프트와 이미지 힌트가 서로 방해받지 않고 조화롭게 작용하도록 돕습니다.
Q는 쿼리 행렬(query matrix), $K_t, V_t$ 는 텍스트 교차-어텐션을 위한 키(key)와 값(value) 행렬, $K_i, V_i$ 는 이미지 교차-어텐션을 위한 키와 값 행렬이다. $Q = ZW_q, K_i = c_i W_k^i, V_i = c_i W_v^i$ 이며, Z는 쿼리 특징, $c_i$는 이미지 특징(여기서는 ID 임베딩)을 나타낸다. $W_k^i$와 $W_v^i$만이 훈련 가능한 가중치입니다. 이 어댑터는 얼굴 디테일 복원을 강화하는 역할을 한다.
IdentityNet
- 디테일 유지, 세밀한 구조적 제어
IdentityNet은 얼굴 디테일을 유지하는 핵심 모듈이다. 실제 사람처럼 보이게 만든다.
ControlNet의 구조를 변형한 핵심 모듈로, 5개의 얼굴 랜드마크(눈, 코, 입 위치)를 공간적 조건으로 사용합니다.특히 IdentityNet 내의 Cross-attention에서는 텍스트 정보를 배제하고 오직 ID 임베딩만을 조건으로 사용하여, 모델이 얼굴의 신원 정보에만 집중하도록 강제합니다.
훈련 과정에서는 사전 학습된 diffusion 모델의 파라미터를 고정하고 Image Adapter와 IdentityNet의 파라미터만 최적화한다. 훈련 목표는 Stable Diffusion과 유사한 Denoising objective를 따른다.
\[\mathcal{L} = \mathbb{E}_{z_t,t,C,C_i,\epsilon \sim N(0,1)}[||\epsilon - \epsilon_\theta(z_t, t, C, C_i)||^2_2]\]$C_i$는 IdentityNet의 작업별 이미지 조건입니다. Image Adapter와 IdentityNet의 분리 설계는 이미지 조건들의 가중치를 독립적으로 유연하게 조절할 수 있게 한다.
텍스트 프롬프트를 완전히 제거하고 ID 임베딩만 사용하는 설계는 아키텍처 중 ‘IdentityNet’ 모듈에만 해당되는 전략
Spatial Control에 대해서 보자.
얼굴의 위치 정보는 5개의 keypoint로 제한한다. 너무 강한 제약을 피하기 위한 선택이다.
학습 전략은 기존 모델 freeze이다.
기존 diffusion 모델은 학습하지 않는다. 새로운 모듈만 학습한다.
추론 과정으로 one-step inference이다.
추론은 매우 빠르다. 한 번의 forward로 결과를 생성한다.

실험 결과, 얼굴 유사도가 매우 높게 유지된다. 단일 참조 얼굴 이미지만으로 다양한 스타일, 포즈, 공간 제어 조건에서 신원(ID)을 얼마나 잘 보존하는지(robustness), 텍스트로 스타일을 바꿀 때의 편집성(editability), 그리고 기존 ControlNet 등과의 호환성(compatibility)을 보여준다. 전반적으로 한 장의 참조만으로도 높은 얼굴 충실도와 스타일 융합을 유지한다.
“empty prompt”: 텍스트 프롬프트 없이 오직 이미지 조건만으로 생성한 결과(완전 이미지 기반).
“style 1/2/3/4…” 등: 같은 참조 ID를 다양한 텍스트 스타일(예: “movie, coat”, “female, dress red hat” 등)로 편집한 결과들을 보여줌 — 편집성 평가.
“canny control”, “depth control” 등: 사전학습된 공간 제어(ControlNet 종류)를 추가했을 때 결과(호환성 평가).
맨 오른쪽 컬럼들은 비현실적/예술적 스타일(만화, 화려한 색채) 등에서의 결과를 포함해, 스타일 융합 성능을 평가함.

InstantID와 기존의 주요 개인화 생성 모델인 IP-Adapter(IPA) 계열 모델들의 성능을 비교한 결과.
InstantID가 단 한 장의 참조 이미지만으로도 추가 학습 없이 높은 수준의 개인화 성능을 보여준다는 것을 보인다.


InstantID는 사전학습된 character LoRA들과 비교해 학습 없이도 경쟁력 있는 결과를 보였다
LoRA와 비교를 해보면 학습 없이 성능 확보가 가능하다
LoRA처럼 학습이 필요한 방법과 비교해도 경쟁력 있는 결과를 보입니다.
속도와 정확도를 동시에 만족하는 장점이 있다.
다만 얼굴 속성 분리가 어렵고 bias 문제가 존재할 수 있다.
ID 임베딩이 신원 뿐만 아니라 나이, 성별, 표정, 조명 등 여러 attribute가 함께 섞여 있기에 특정 속성만 골라 바꾸거나 제어하기 어렵고 사용된 얼굴 모델, 학습 데이터의 편향으로 특정 그룹에서 성능이 떨어지거나 편향된 결과가 나올 수 있다.
InstantID는 효율성과 성능을 동시에 달성한 모델이다.
정리
InstantID가 이미지 퍼스널라이제이션을 구현하는 핵심은 추가 학습(Fine-tuning) 없이 단 한 장의 이미지로 신원을 보존하는 제로샷(Zero-shot) 아키텍처에 있다. 기존 방식들이 수십 장의 사진과 긴 학습 시간을 필요로 했던 것과 달리 InstantID는 신원 정보의 정밀한 추출과 공간적 제어를 분리하여 이를 달성했다
ArcFace 기반 Face Encoder
기존 모델들이 이미지의 전반적인 분위기를 잡는 CLIP 인코더를 썼다면 InstantID는 안면 인식에 최적화된 ArcFace를 활용한다.
강력한 시맨틱 정보: CLIP이 스타일이나 색상 같은 모호한 정보를 담는 것과 달리 ArcFace는 인물의 얼굴 구조와 정체성에 직결된 고차원 벡터(ID Embedding)를 추출한다.
단일 이미지 효율성: 이 강력한 인코더 덕분에 단 한 장의 참조 이미지로도 인물의 고유한 특징을 잡아낼 수 있다.
IdentityNet (강한 시맨틱 + 약한 공간 제어)
퍼스널라이제이션의 가장 큰 숙제인 “똑같이 닮게 그리기”를 위해 IdentityNet이라는 특수 모듈을 설계했다.
텍스트 프롬프트 제거: 이 모듈 내부의 교차 어텐션에서는 의도적으로 텍스트 입력을 차단하고 ID 임베딩만 사용한다. 이는 모델이 배경 설명에 한눈팔지 않고 오직 ‘이 사람의 얼굴’에만 집중하게 만든다.
5개의 랜드마크: 눈, 코, 입 위치만 표시한 5점 랜드마크를 입력으로 주어 얼굴의 큰 구도는 지키되, 너무 세밀한 제약(얼굴형 등)은 풀어주어 다양한 스타일로의 변환이 가능하게 한다.
Decoupled Cross-Attention Image Adapter
신원을 고정하는 것만큼 중요한 것이 사용자가 원하는 스타일로 변환하는 능력
병렬 처리: Decoupled Cross-Attention을 통해 텍스트 프롬프트 정보와 ID 이미지 정보를 별도의 채널로 처리한다.
편집 가능성 유지: 이 구조 덕분에 인물의 신원은 유지하면서도 텍스트를 통해 옷차림, 배경, 화풍 등을 자유롭게 바꿀 수 있는 Editability를 확보했다.