[논문정리] Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time(2025).Kunhao Liu1∗ Wenbo Hu2† Jiale Xu2 Ying Shan2 Shijian Lu1†
‘Rolling Forcing: Autoregressive Long Video Diffusion in Real Time’. 이 논문은 최근 비디오 생성 분야에서 가장 큰 화두인 실시간성(Real-time)과 장기적 일관성(Long-term coherence)을 동시에 해결하려는 시도를 담고 있습니다. 특히 기존 자기회귀 모델들이 가졌던 고질적인 문제인 오차 누적을 어떻게 혁신적으로 억제했는지에 초점을 맞췄습니다.
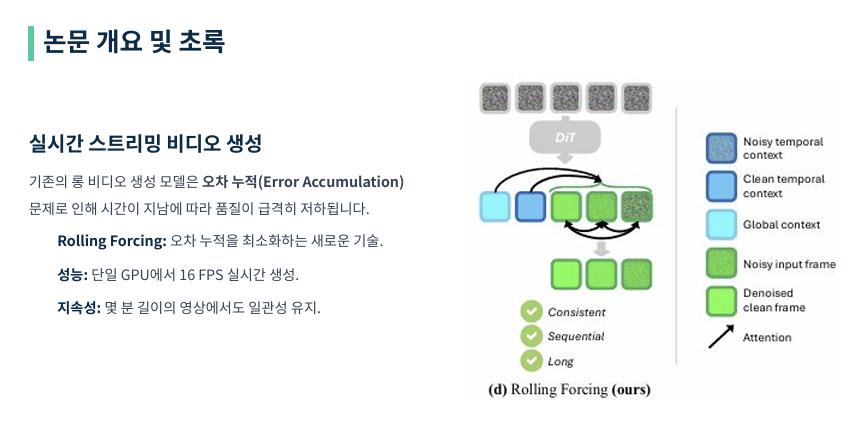
본 논문의 핵심을 요약하자면, 단일 GPU에서 16 FPS라는 놀라운 속도로 고품질의 롱 비디오를 생성할 수 있는 프레임워크를 제안했다는 점입니다. 기존 모델들이 10초 내외의 짧은 영상에서도 품질 저하를 겪었던 것과 달리, Rolling Forcing은 몇 분 단위의 스트리밍에서도 시각적 드리프트 없이 일관된 퀄리티를 유지합니다. 이는 향후 인터랙티브 월드 모델이나 실시간 시뮬레이션 분야에 매우 중요한 이정표가 될 것입니다.

비디오 생성 기술은 단순히 정해진 길이의 영상을 만드는 단계를 넘어, 사용자의 입력에 실시간으로 반응하는 ‘인터랙티브 엔진’으로 진화하고 있습니다. 예를 들어, 신경망 기반의 게임 엔진이나 XR 환경에서는 고정된 영상이 아니라 무한히 확장 가능한 비디오 스트림이 필요합니다. 하지만 기존의 오프라인 모델들은 전체 프레임을 한 번에 연산해야 하므로 이러한 실시간 응답성을 확보하기가 매우 어려웠습니다.

실시간 생성을 위해 가장 많이 쓰이는 방식은 이전 프레임을 조건으로 다음 프레임을 만드는 자기회귀(Autoregressive) 방식입니다. 하지만 여기서 ‘노출 편향(Exposure Bias)’ 문제가 발생합니다. 훈련 시에는 정답(Ground-truth) 데이터를 보지만, 추론 시에는 자신이 생성한 오차가 포함된 프레임을 다시 입력으로 사용하기 때문입니다.
이 미세한 오차들이 수백 프레임에 걸쳐 누적되면 결국 영상의 형체가 붕괴되거나 색상이 변하는 ‘드리프트’ 현상이 나타나게 됩니다.
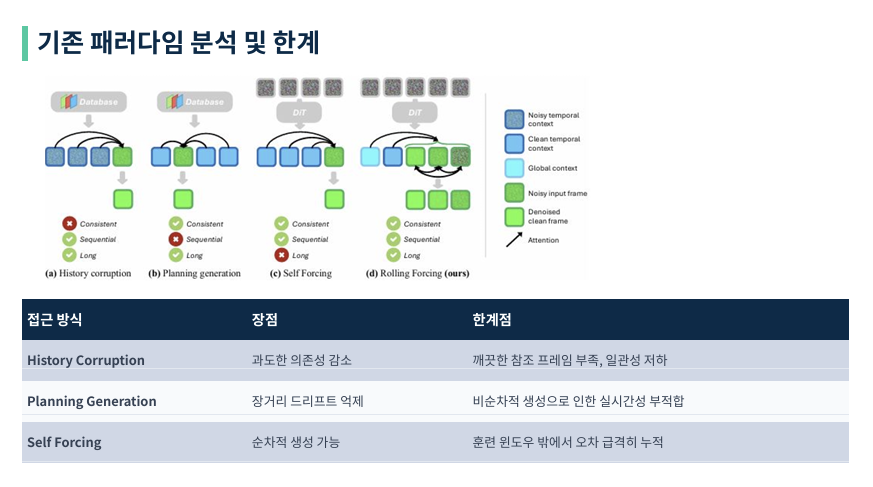
이를 해결하기 위해 여러 시도가 있었습니다.
‘History Corruption’은 과거 프레임에 노이즈를 섞어 의존도를 낮췄지만 일관성이 깨졌고,
‘Planning Generation’은 먼 미래의 키프레임을 먼저 만들어 오차를 잡으려 했으나 순차적 생성이 필수인 실시간 환경에는 적합하지 않았습니다.
최근의 ‘Self Forcing’ 방식 또한 훈련 윈도우를 벗어나면 결국 오차가 누적되는 한계를 보였습니다.
(a) History Corruption (과거 정보 오염시키기) 특징: 과거 프레임에 일부러 노이즈(그림 속 점박이 파란색)를 섞어서 모델이 과거에 너무 집착하지 않게 만듭니다.
성적표: 오차 누적은 좀 줄지만, 깨끗한 참조 데이터가 없으니 화면이 지지직거리거나 연결이 어색해지는 일관성(Consistent) 문제가 생겨 빨간색 X가 쳐져 있습니다.
(b) Planning Generation (미리 계획 세우기) 특징: 먼 미래의 중요한 장면(키 프레임)을 먼저 그려놓고 그 사이를 채우는 방식입니다. 성적표: 품질은 좋지만, 순서대로(1초, 2초, 3초…) 만드는 게 아니라 앞뒤를 왔다 갔다 하며 만들기 때문에 실시간으로 화면을 내보내야 하는 순차적 생성(Sequential)이 불가능합니다.
(c) Self Forcing (자기 강화) 특징: 자기가 만든 프레임을 다시 다음 프레임의 재료로 쓰며 순서대로 쭉 나아갑니다. 성적표: 실시간으로 만들기에 딱 좋지만, 앞 프레임의 아주 작은 실수가 다음 프레임에서 눈덩이처럼 불어나 결국 영상이 망가지는 장기 유지(Long) 문제가 심각합니다.
(d) Rolling Forcing (이 논문의 정답!) 특징: 그림 맨 오른쪽을 보면 하늘색 상자(글로벌 컨텍스트)와 초록색 상자들 사이의 양방향 화살표가 보이시죠?
하늘색 상자: 영상 맨 처음의 정보를 끝까지 기억하는 ‘닻(Anchor)’ 역할을 합니다. 초록색 화살표: 윈도우 안에서 프레임들이 서로 “야, 너 그 부분 좀 이상해” 하며 오차를 실시간으로 고쳐줍니다(상호 정제).
성적표: 덕분에 일관성도 지키고, 순서대로 만들면서도, 몇 분 동안 영상이 깨지지 않는 세 가지 토끼를 다 잡았다는 뜻입니다.
sequential x 문제인가?
실시간 스트리밍·인터랙티브 목적인 경우: Planning generation은 기본 모드로 쓰기 어렵다. Rolling Forcing 같은 윈도우 기반 또는 하이브리드 전략이 더 현실적. 오프라인·버퍼 허용 환경: Planning은 장기 드리프트를 효과적으로 줄이는 강력한 옵션.

Rolling Forcing은 크게 세 가지 기술적 기여를 합니다.
첫째, 여러 프레임을 동시에 정제하는 ‘Rolling Window’,
둘째, 초기 정보를 잃지 않게 해주는 ‘Attention Sink’,
셋째, 이를 효율적으로 학습시키는 ‘few-step distillation’ 전략입니다.
품질 저하를 최소화하면서도 연산량을 획기적으로 줄여 단일 GPU에서 16 FPS라는 실시간 속도를 달성할 수 있었습니다. 특히 이 기술은 Rolling Window와 결합되어, 윈도우가 한 칸 이동할 때마다 정해진 소수의 단계(T 스텝)만 계산하고도 즉시 깨끗한 프레임을 배출하게 만드는 최적화 엔진 역할을 합니다.

첫 번째 핵심인 ‘Rolling Window’입니다. 기존에는 한 번에 한 프레임씩만 디노이징을 끝내고 다음으로 넘어갔습니다.
하지만 본 논문은 윈도우 내의 여러 프레임을 서로 다른 노이즈 레벨로 유지하며 동시에 처리합니다. 윈도우 안에서는 양방향 어텐션이 작동하여, 뒤쪽 프레임의 정보가 앞쪽 프레임의 오차를 수정하는 ‘상호 정제(Mutual Refinement)’가 일어납니다. 이를 통해 매 스텝마다 가장 앞쪽의 깨끗한 프레임 하나를 안정적으로 배출할 수 있습니다.

수식으로 보면 더 명확합니다. 비디오 시퀀스의 확률 분포를 체인 룰로 분해했을 때, 각 단계는 이전까지 생성된 모든 프레임을 조건으로 합니다. Rolling Forcing은 이 조건부 확률을 계산할 때 단순히 과거만 보는 것이 아니라, 현재 디노이징 중인 윈도우 내 프레임들 간의 결합 분포를 최적화함으로써 훨씬 견고한 전이 확률을 학습하게 됩니다. 이는 수치적으로 노출 편향을 직접 타격하는 구조입니다.
이 수식은 기존의 일반적인 자기회귀(Autoregressive) 방식을 설명합니다.
\[p(x^{1:N}) = \prod_{i=1}^{N} p(x^{i} | x^{<i})\]의미: 비디오 전체($x^{1:N}$)가 만들어질 확률은, “이전까지의 모든 프레임($x^{<i}$)이 주어졌을 때, 현재 프레임($x^i$)이 나올 확률”을 모두 곱한 것과 같다는 뜻입니다.
문제점: 이 방식은 프레임을 하나씩(Strictly Causal) 순서대로 만듭니다. 따라서 $x^1$에서 아주 작은 실수가 생기면 $x^2$는 그 실수를 이어받고, $x^3$는 더 큰 실수를 이어받게 됩니다. 이것이 바로 영상이 점점 뭉개지는 오차 누적(Error Accumulation) 의 원인입니다.
- Rolling Forcing의 윈도우 디노이징 분포
이 수식은 이 논문이 제안한 새로운 생성 방식입니다.
\[p_{\theta} (x^{i:i+T-1}_{t_{0:T-1}} | x^{i:i+T-1}_{t_{1:T}}, x^{<i}_{0})\]이 수식은 “우리는 프레임 하나만 보지 않고, $T$개의 프레임을 묶은 윈도우를 한꺼번에 처리하겠다”는 의지를 담고 있습니다. 기호의 의미는 다음과 같습니다:
$x^{i:i+T-1}$: 현재 생성 중인 $i$번째부터 $i+T-1$번째까지의 프레임 묶음(윈도우)입니다.
$x^{<i}_{0}$: 이전에 이미 완벽하게 만들어진 깨끗한(Clean) 과거 프레임들입니다. 이들이 조건으로 주어집니다.
$t_{1:T}$ vs $t_{0:T-1}$: 윈도우 안의 프레임들이 가진 노이즈 레벨입니다.
- 입력($t_{1:T}$)은 노이즈가 더 많은 상태이고, 출력($t_{0:T-1}$)은 노이즈가 한 단계씩 줄어든 상태를 의미합니다.
핵심 차이점: 이전 프레임들($x^{<i}$)만 참고하는 게 아니라, 윈도우 내의 $T$개 프레임이 서로를 양방향(Bidirectional)으로 참조하며 동시에 노이즈를 제거합니다.
$x^{i:i+T-1}{t{0:T-1}}$: 우리가 얻고 싶은 ‘한 단계 더 깨끗해진 프레임들’ 입니다.
$x^{i:i+T-1}{t{1:T}}$: 현재 윈도우 안에 들어있는 ‘노이즈가 섞인 입력 프레임들’ 입니다 $x^{<i}_{0}$: 이전에 이미 완성된 ‘깨끗한 과거 프레임들’ 입니다
첫 번째 수식: “과거만 보고 미래를 하나씩 예측한다.” → 오차가 쌓이기 쉬움.
두 번째 수식: “과거를 보되, 미래의 프레임 여러 개를 동시에 다듬으며 서로의 오류를 고쳐준다.” → 오차 누적을 획기적으로 방지(Mutual Refinement).

두 번째는 ‘Attention Sink’입니다. 영상이 길어질수록 초기 설정(예: 배경의 색감, 캐릭터의 외형)을 잊어버리기 쉽습니다. 이를 방지하기 위해 생성된 첫 번째 프레임들의 KV(Key-Value) 캐시를 메모리에 박아두고, 이후 모든 프레임이 이를 참조하게 만듭니다. 이를 통해 수천 프레임 뒤에서도 영상의 근본적인 톤앤매너가 유지되는 ‘글로벌 앵커’ 역할을 수행하게 됩니다.

긴 영상을 생성할 때 발생하는 또 다른 문제는 위치 인코딩(RoPE)의 범위 초과입니다. 프레임 번호가 계속 커지면 훈련 때 보지 못한 먼 거리의 인덱스가 들어와 모델이 오작동하게 됩니다. 본 논문은 이를 해결하기 위해 참조하는 프레임들의 상대적 거리를 일정 범위 내로 고정하는 ‘Dynamic RoPE’를 제안했습니다. 이를 통해 화면이 갑자기 튀거나(Jumping) 깜빡이는 현상을 획기적으로 줄였습니다.

Rolling Forcing은 DMD(Distribution Matching Distillation) 기법을 사용해 고성능의 양방향 교사 모델을 실시간 스트리밍 모델로 증류합니다.
특히 ‘비중첩 윈도우(Non-overlapping Window)’ 전략을 사용하여 메모리 효율을 극대화했습니다.
덕분에 기존 방식 대비 메모리 점유율을 대폭 낮추면서도 전체 영상 구간에 대한 충분한 학습 데이터를 확보할 수 있었습니다.

우리가 제안한 Rolling Forcing(RF) 방식만으로 모델을 훈련할 경우 한 가지 부작용이 나타날 수 있습니다. 윈도우 내부의 프레임들이 서로 다른 노이즈 레벨을 가지고 있다 보니, 학습 과정에서 비디오의 움직임이나 카메라의 이동이 다소 부자연스럽게 변할 수 있다는 점입니다.
이를 보완하기 위해 우리는 두 가지 학습 방식을 결합한 정적-동적 균형 전략을 사용했습니다.
• 첫째, Self Forcing(SF) 학습입니다. 이 방식은 프레임을 하나씩 순차적으로 학습하며 모델이 자연스러운 카메라 이동 규칙과 부드러운 움직임을 익히도록 돕는 일종의 정규화(Regularizer) 역할을 합니다.
• 둘째, Rolling Forcing(RF) 학습입니다. 이는 앞서 설명해 드린 대로 여러 프레임을 동시에 다루며 장기적인 오차 누적, 즉 드리프트 현상을 강력하게 억제하는 법을 모델에게 가르칩니다.
결론적으로, 이 두 가지 목적이 다른 학습법을 50:50의 동일한 비율로 교차 훈련함으로써, Rolling Forcing은 자연스러운 영상미를 유지하면서도 몇 분 동안 품질이 깨지지 않는 압도적인 안정성을 동시에 확보할 수 있었습니다.
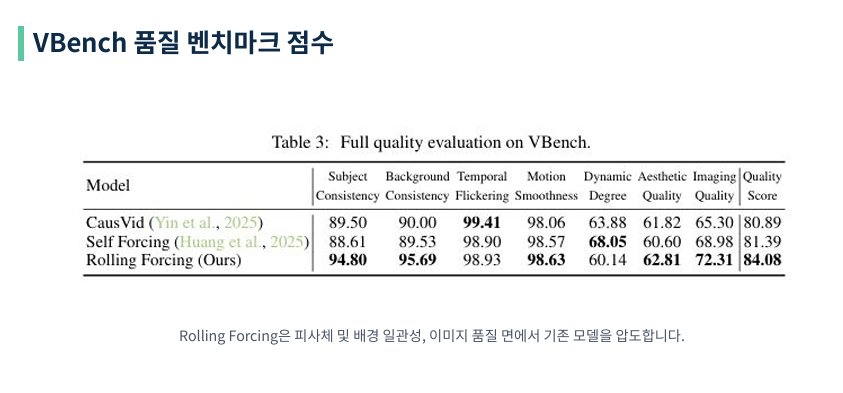
비디오 생성 품질을 측정하는 VBench 지표에서 Rolling Forcing은 84.08점을 기록하며 기존의 Self Forcing이나 CausVid 모델들을 유의미한 차이로 제쳤습니다. 특히 피사체의 일관성(Subject Consistency)과 배경의 안정성에서 높은 점수를 받았는데, 이는 앞서 설명한 Attention Sink와 Rolling Window의 시너지 효과라고 볼 수 있습니다.
Dynamic Degree(동적 수준) 점수가 상대적으로 낮은 이유는 일관성(Consistency)과 움직임(Motion) 사이의 트레이드오프(Trade-off) 관계 때문입니다. VBench에서 Dynamic Degree 는 단순히 ‘화면 내 움직임이 얼마나 많은가’를 측정합니다. 움직임이 크더라도 형태가 뭉개지면 품질 점수(Quality Score)는 떨어지는데, Rolling Forcing은 전체 품질(Quality Score, 84.08) 에서 가장 높으므로 “적게 움직이지만 가장 고품질인 영상”을 만든다고 해석할 수 있습니다.
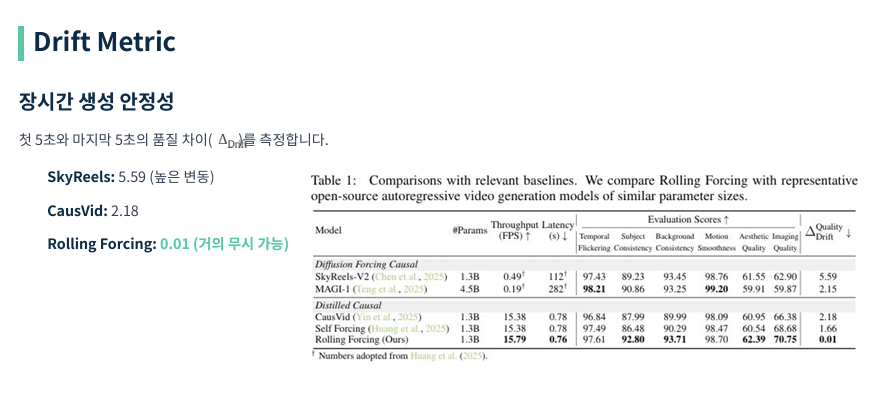
이 논문의 가장 강력한 증거는 ‘Drift Metric’입니다. 영상의 시작 부분과 끝 부분의 품질 차이를 측정했을 때, 기존 모델들은 2.0 이상의 큰 폭의 품질 저하를 보인 반면, Rolling Forcing은 0.01이라는 거의 완벽에 가까운 안정성을 보여주었습니다. 이는 이론적으로 무한한 길이의 영상 생성이 가능함을 시사합니다.
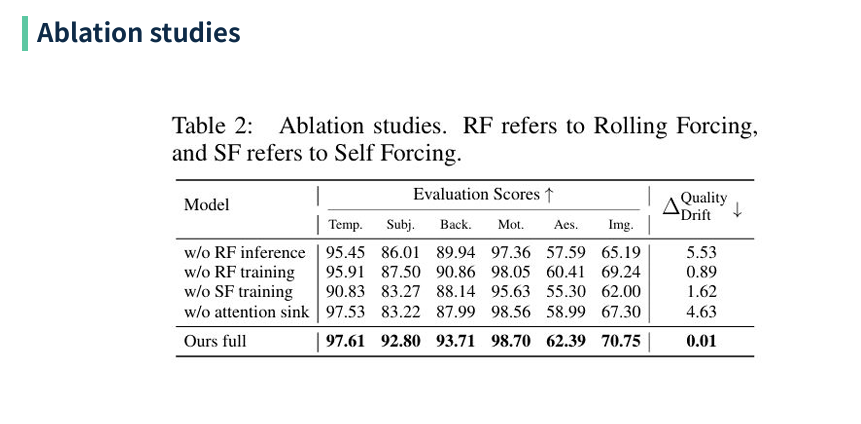
w/o RF inference: 추론에서 롤링 윈도우를 빼면 인접 프레임 간 상호 보정이 사라져 오류가 빠르게 누적된다.
w/o RF training: 훈련 시 롤링을 사용하지 않으면 모델이 윈도우 기반 상호보정 능력을 학습하지 못해 장기 안정성이 약해진다.
w/o SF training: Self Forcing 성분을 제거하면 자기 생성 이력에 적응하는 능력과 자연스러운 카메라/모션 흐름이 저하된다.
w/o attention sink: 초기 프레임의 전역 KV를 유지하지 않으면 색감·노출 등 장기 전역 속성이 점진적으로 드리프트한다.
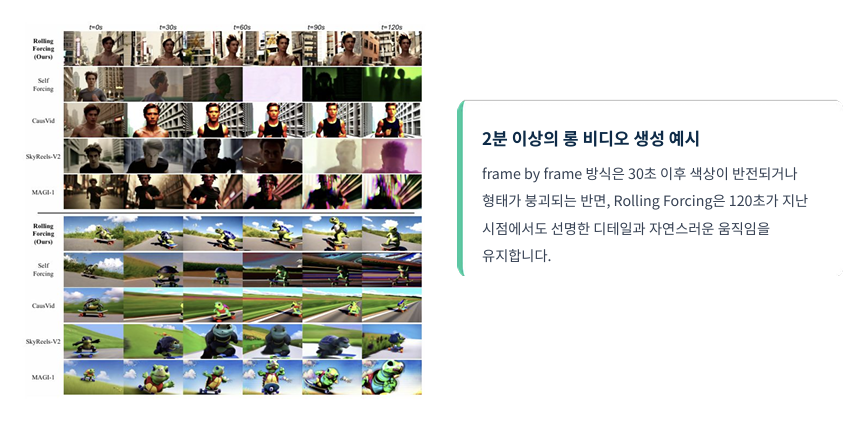
실제 생성된 영상을 보면 차이가 더 극명합니다. 120초(약 2000프레임)가 지난 시점에서 다른 모델들은 색상이 반전되거나 배경이 녹아내리는 현상이 발생하지만, 본 모델은 첫 프레임과 동일한 디테일과 색감을 유지합니다. 이는 실시간 스트리밍 모델 중에서는 독보적인 수준의 장기 유지력입니다.

결론적으로 Rolling Forcing은 롤링 윈도우와 어텐션 싱크라는 창의적인 접근을 통해 실시간 스트리밍 비디오 생성의 고질병인 오차 누적 문제를 해결했습니다. 물론 아직 GPU 메모리 효율화나 더 복잡한 시퀀스 제어라는 숙제가 남아있지만, 실시간 월드 모델을 구축하는 데 있어 매우 강력한 기반 기술이 될 것입니다.