[논문정리] 3D GAN
Convolutional Neural Networks (Course 4 of the Deep Learning Specialization)
Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T. Freeman, Joshua B. Tenenbaum (2016). Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling . NIPS 2016.
Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling
1. Introduction
3D GAN?
기존 2차원 이미지를 생성하던 GAN을 3차원 공간으로 확장하여 입체적인 형상을 생성하는 모델이다.
목표
- 높은 다양성과 현실성을 갖춘 3D 객체를 합성할 수 있어야한다.
- 기존 방식의 한계:
기존 방식들은 미리 정의된 저장소에서 부품을 재조합하는데 그쳐 새로운 모양을 생성하지 못하거나 생성된 객체에 구멍같은 artifacts가 남는 경우가 있다.artifacts: 알고리즘의 실수로 생기는 원치 않는 시각적 흔적. 노이즈
3D GAN
제안
volumetric convolutional networks과 GAN을 활용하여 3D 객체를 생성하는 새로운 프레임워크를 제안한다
volumetric convolutional networks: 3D 데이터를 처리하기 위해 볼륨 데이터를 사용하는 합성곱 신경망
이점
고품질 객체 합성:
전통적인 수학적 규칙 대신 desciminator을 사용하여 객체 구조를 스스로 이해하고 고품질 3D 객체를 합성한다.확률적 잠재 공간:
probabilistic latent space에서 3D 객체를 샘플링하여 새로운 객체를 생성할 수 있다
Probabilistic Latent Space: 생성된 객체들이 분포로부터 샘플링될 수 있는 저차원 확률 공간
- 강력한 특징 추출기:
적대적 판별자가 비지도 학습으로 학습되어 3D 객체 인식에 유용한 강력한 3D 모양 descriptor를 제공한다.
판별자가 가짜를 찾아내는 과정에서 정답 라벨 없이도 3차원 물체의 핵심적인 형태적 특징을 스스로 학습하게 된다. 이렇게 추출된 수치 데이터(Descriptor)는 새로운 3D 객체를 식별하거나 분류할 때 매우 강력한 지표로 활용된다.
descriptor: 대상 물체의 고유한 형태나 구조적 특징을 압축하여 숫자로 나타낸 데이터.
기존 방식과 차별점
생성 및 인식을 위해 단일 특징 표현을 학습하는 대신 3D-GAN은 비지도 방식으로 분리된 생성 및 판별 표현을 학습하여 각각 생성 및 인식 작업에 적용한다.
생성과 판별을 동시에 배우는게 아니라 각자의 역할에 최적화된 서로 다른 지식 체계를 독립적으로 쌓는다.
3. Models
3D GAN 구조
기본 구조
생성자와 판별자로 구성된다
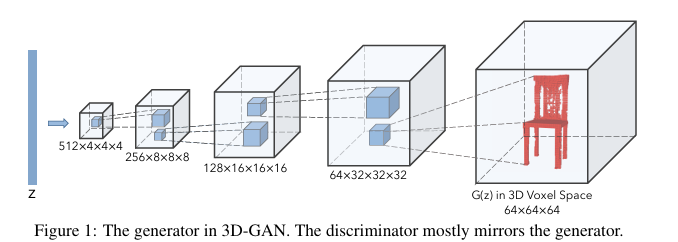
잠재 벡터(z) 가 여러 단계의 3D Transposed Convolution 과정을 거쳐 구체적인 3D 객체(의자) 로 형상화되는 과정
입력층 (z): 가장 왼쪽에 위치한 파란색 막대. 모델이 새로운 3D 형태를 생성하기 위한 씨앗 역할을 하는 1차원 벡터 데이터이다.
1단계 (512x4x4x4): 잠재 벡터가 처음으로 3차원 부피를 가진 특징 지도로 변환된 상태이다. 해상도는 4x4x4로 낮지만 512개의 많은 채널을 통해 복잡한 특징 정보를 담고 있다.
확장 과정 (점선): 각 상자 사이를 잇는 점선은 3D 전치 합성곱 연산을 의미한다. 이 과정을 지날 때마다 공간 해상도(가로x세로x높이)는 2배씩 커지고 특징 채널의 수는 절반으로 줄어든다.
중간 단계들 (256x8^3 ~ 64x32^3): 데이터가 점점 더 세밀해지는 과정이다. 상자의 크기가 물리적으로 커지는 것은 3D 공간에서의 해상도가 높아짐을 시각적으로 나타낸다.
최종 출력층 (G(z) in 3D Voxel Space): 가장 오른쪽에 있는 64x64x64 크기의 상자입니다. 모든 연산이 끝난 후, 모델이 최종적으로 생성한 3D 의자 형태가 Voxel 단위로 구현된 결과물이다.
3D Transposed Convolution?
입력된 3차원 데이터의 공간 해상도를 높여 더 큰 부피의 출력을 생성하는 연산이다.
일반 합성곱은 특징 추출 및 차원 축소를 하는 반면 전치 합성곱은 데이터 복원 및 차원을 확장한다.
생성자(G):
200차원 잠재 벡터 $z$ (확률적 잠재 공간에서 샘플링)를 $64 \times 64 \times 64$ 체적(voxel) 3D 객체로 매핑한다
체적(voxel): 2D 이미지 최소 단위가 픽셀인것처럼 3D 입체공간을 구성하는 최소 단우의 작은 정육면체다. volume+pixel
복셀: 입체 공간 안의 작은 정육면체 점
3D 객체(cube): 복셀들이 가로 64개, 세로 64개, 높이 64개씩 쌓여 만들어진 전체 3D 격자 공간.
생성자가 200차원 벡터에서 64x64x64 입체를 만드는 방법
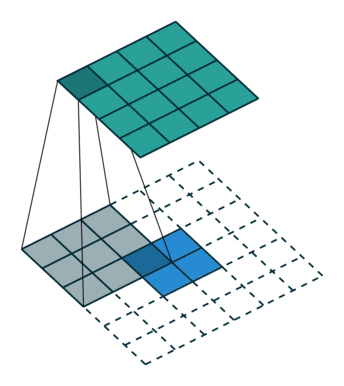
Upsamping
작은 input 데이터를 convolution을 통해서 더 큰 data로 바꾼다.
파란색이 입력 데이터, 하얀 색이 패딩, 초록색이 출력 데이터이다.
판별자(D):
입력돈 3D 객체 $x$가 실제인지 생성된 것인지에 대한 점수를 출력한다
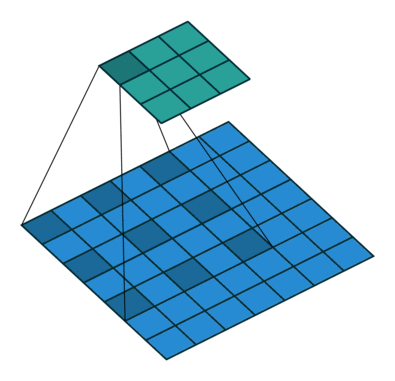
Downsampling
upsampling과 반대로 이미지나 입체의 크기를 줄여가며 그 안에 숨겨진 특징을 찾아내고 최종적으로 진짜인지 판단하는 과정이다.
손실함수
binary cross-entropy 를 분류 손실로 사용하여 전체 적대적 손실 함수는
\[L = \log D(x) + \log(1 - D(G(z))) \quad\]Network structure
합성곱 신경망을 사용한다.
생성자:
3개의 체적 완전 합성곱 레이어(커널 크기 $4 \times 4 \times 4$, 스트라이드 2)로 구성되며 batch normalization 및 ReLU 레이어가 추가되고 Sigmoid 레이어로 끝난다
판별자:
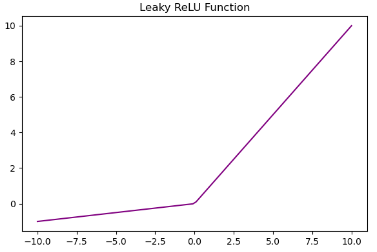
생성자와 구조가 유사하나 ReLU 대신 LeakyReLU를 사용하며 풀링 또는 선형 레이어는 없다
LeakyReLU: ReLU의 변형으로 음수 입력에 대해 아주 작은 기울기를 부여한다. ReLU의 장점을 유지하면서 죽은 뉴런을 다시 활성화 시킬 수 있다.
Training Details
판별자가 생성자보다 훨씬 빠르게 학습되는 문제를 해결하기 위해 적응형 훈련 전략을 사용한다
3D 보셀 공간에서 객체를 생성하는 것이 실제 객체와 합성 객체를 구별하는 것보다 더 어렵기 때문일 수 있다
판별자는 이전 배치에서 정확도가 80%를 초과하지 않을 경우에만 업데이트된다.
판별기가 이전 배치에서 80% 이상의 정확도를 보였다면 이미 충분히 똑똑한 상태이므로 잠시 학습을 멈추고 생성기가 판별기를 속이기 위한 새로운 전략을 학습할 시간을 주는 것이다.
그럼 80%를 계속 못넘는거 아닌가?
판별기가 학습을 통해 실력이 좋아져 정확도가 80%를 넘긴다.
정확도가 80%를 넘는 순간 판별기는 업데이트를 멈추고 제자리에 서 있습니다.
생성기는 멈춰 있는 판별기를 속이기 위해 성능을 높인다.
생성기가 판별기를 잘 속이게 되면 가만히 있던 판별기의 정확도는 자연스럽게 80% 아래로 떨어진다.
정확도가 80% 밑으로 내려가면 판별기가 다시 학습을 시작하여 기준을 더 높인다
+최종목표는 50%이다
Learning Rate:
생성기(G)는 0.0025로 비교적 빠르게 판별기(D)는 10^-5로 매우 천천히 학습하도록 설정한다.
최적화 알고리즘:
ADAM 최적화 도구를 사용하며 모멘텀을 조절하는 $\beta$ 값은 0.5로 설정하여 안정성을 높인다.
배치 크기:
매 학습 단계마다 100개의 데이터 묶음을 사용하여 계산 효율을 확보한다.
3D-VAE-GAN
3D-GAN에 이미지 인코더(E)를 추가하여 2D 이미지에서 3D 객체로의 매핑을 학습한다
기본 구조
이미지 인코더(E), 디코더(G, 3D-GAN의 생성자), 판별자(D)로 구성된다
인코더 구조:
5개의 공간 합성곱 레이어로 구성되며 입력 2D 이미지를 200차원 잠재 벡터 $z$로 출력한다
손실 함수
\(L = L_{3D-GAN} + \alpha_1 L_{KL} + \alpha_2 L_{recon} \quad\)
$L_{KL}$ (KL 발산):
\(L_{KL} = D_{KL}(q(z|y) || p(z))\)
인코더 출력의 변분 분포 $q(z|y)$를 사전 분포 $p(z)$ (평균 0, 단위 분산의 다변수 가우시안 분포)에 가깝게 제한한다.
인코더가 2D 이미지를 보고 숫자로 압축할 때 그 숫자 값 $z$ 들이 무작위가 아니라 일정한 규칙(평균 0, 분산 1인 가우시안 분포)를 따르도록 강제하는 장치이다
$L_{recon}$ (재구성 손실):
인코더가 입력 이미지 $y$에 해당하는 3D 모양 $x$를 재구성하도록 한다.
생성한 3D 가 원래 입력돈 2D 이미지와 똑같이 생겼는지 확인하는 점수
$L_{3D-GAN}$ (적대적 손실):
위의 두 점수가 좋아도 결과물이 흐릿할 수 있다. 이때 GAN으 판별자가 선명하게 다듬는 역할을 한다.
훈련 데이터:
3D-VAE-GAN 훈련에는 2D 이미지와 해당 3D 모델이 모두 필요하며 SUN 데이터베이스의 16,913개 실내 이미지와 렌더링된 3D 모양을 사용한다
4. Evaluation
5. Analyzing Learned Representaions
latent space 이해를 위한 세 가지 방법
인공지능이 숫자로 기억하고 있는 3D 물체의 핵심 특징들을 사람이 이해할 수 있는 물리적 변화로 확인하는 과정이다
visualizing the object vector

벡터의 특징 차원 값을 점진적으로 증가시키며 생성된 3D 객체의 변화를 관찰한다
200 차원 잠재 벡터를 구성하는 개별 숫자의 값을 하나씩 조절해보면서 물체의 외형이 어떻게 바뀌는지 관찰한다.
인공지능이 학습한 추상적인 숫자와 실제 3D 형태 사이의 연결고리를 찾는다
Interpolation(보간)

두 객체 벡터 간의 보간은 객체 카테고리 내외에서 부드러운 전환을 제공한다
두개의 서로 다른 객체 벡터 사이의 중간값들을 계산하여 그 변화 과정을 생성한다.
Arithmetic(산술 연산)
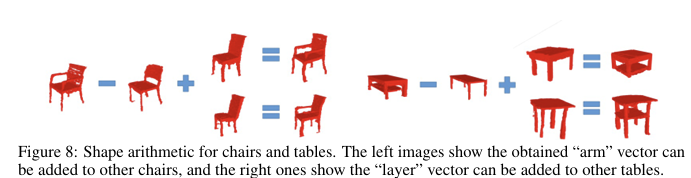
잠재 공간에서 산술 연산을 적용하여 arm 벡터를 다른 의자에 더하거나 layer 벡터를 다른 레이블에 더하는 조작이 가능하다
팔걸이 있는 의자 벡터- 팔걸이 없는 의자 벡터를 계산하면 팔걸이 정보만 담긴 벡터를 얻을 수 있다
Discriminative Representation
visualize the neurons in discriminator
판별자의 특정 뉴런이 가장 강하게 활성화되는 객체를 분석한다.

- 단일 뉴런은 전체 객체 모양에 대해 선택적이다. 가장 강하게 활성화되는 객체들이 매우 유사하다.
전체 모양의 선택
뽑한 5개 물체의 실루엣이 비슷하다.
뉴런 하나를 골라서 가장 민감하게 반응한 물체 5개를 뽑아보니 전체적인 실루엣이 서로 닮아 있다
특정 뉴런 하나가 특정 스타일의 물체를 전담해서 식별하는 탐지기 역할을 한다. - 뉴런을 활성화시키는 부분(빨간색으로 표시)은 해당 뉴런을 가장 강하게 활성화시키는 객체들 사이에서 일관적이다. 이는 뉴런이 객체 부분에 대한 의미론적 지식도 학습하고 있음을 보여준다.
부위별 의미
물체마다 빨간 부위가 비슷하다.
빨간색 지점은 뉴런이 물체의 어느 곳을 보고 반응했는지 보여준다.
뉴런이 물체의 이름을 외운게 아니라 팔걸이나 다리 같은 세부 부품의 구조를 이해하고 있다는 의미이다
다음에 3D-aware GAN 에 대해서도 알아보고자 한다.
3D VAE GAN의 한계:
- 해상도 한계:
복셀 방식은 해상도를 2배 키우면 연산량이 8배 늘어나기 때문에 고해상도 구현이 어렵다. - 데이터의 한계:
3D-VAE-GAN은 사진(2D)과 실제 모델(3D)이 쌍으로 묶인 데이터가 필수적인데 이를 대량으로 구하기는 현실적으로 매우 어렵다.
이러한 한계로 최근에는 3D 모델 없이 2D 사진만으로 3D를 이해하는 3D aware GAN이 주류가 되었다고한다.
3D GAN은 3차원 입체물 자체를 만드는 것이 목적이고 3D-aware GAN은 3차원 구조를 이해한 상태에서 정교한 2차원 이미지를 생성하는 것이 목적이다.
참고: