[논문정리] Visual Effects Using Human Pose Recognition and Style Transform by Kinect
Youngrock Lo, Hasil Park, & Joonki Paik (2021). Visual Effects Using Human Pose Recognition and Style Transform by Kinect. TECHART: Journal of Arts and Imaging Science, 8(2), 12-14. 10.15323/techart.2021.5.8.2.12
CV와 관련되면서 지금 관심있는 인터랙티브 미디어아트 학술 저널을 읽어보기로 했다.
Abstract
인간의 포즈 인식과 스타일 전이를 이용하는 인터랙티브 미디어 아트를 제시한다. 여기서는 kniect를 이용해 시각화한다.
- 키넥트의 depth 이미지 정보를 이용해 인간 관절을 검출한다.
- 입력 카메라 depth 이미지에서 손 영역을 관심 영역으로 선택한다.
- 검출된 손 관절 좌표와 거리를 계산하여 제안하여 구현한다. 딥러닝 기반 실시간 스타일 전이 네트워크를 사용해 스타일을 변환한다. 손 동작과 스타일 전이를 통해 상호작용한다.
Framework
Proposed artwork process
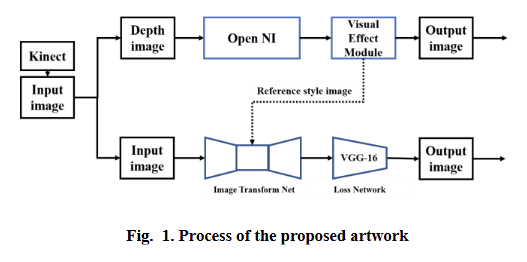
- Kinect 입력: 시작은 Kinect 센서에서 얻는 이미지 데이터이다. Kinect는 관객의 움직임과 심도 정보를 감지하며, 여기서 ‘Depth image’와 ‘Input image’ 두 가지 유형의 데이터를 얻는다.
- 깊이 이미지 처리 (인체 자세 인식 및 시각 효과):
- Depth image: Kinect에서 얻은 깊이 이미지는 사람과 배경의 거리를 포함힌다.
- Open NI: Open NI (Natural Interaction)는 Kinect에서 받은 깊이 이미지를 분석하여 사람의 관절 위치, 움직임 등의 정보를 추출하는 미들웨어이다. 여기서 미들웨어는 서로 다른 애플리케이션이 서로 통신하는 데 사용되는 소프트웨어다. 이 단계에서 관객의 몸짓을 인식하기 위한 핵심 데이터가 생성된다.
- Visual Effect Module: Open NI에서 얻은 인체 움직임 정보를 바탕으로 작품의 시각적 효과를 생성한다. 논문에서는 손의 위치나 박수 같은 동작에 따라 나무가 자라거나 잎이 떨어지는 효과를 구현했다. 이 모듈은 최종 ‘Output image’ 경로로 시각 효과 이미지를 전달한다. 또한 스타일 변환을 위한 ‘Reference style image’를 제공한다.
- 입력 이미지 처리 (스타일 변환):
- Input image: Kinect에서 얻은 일반적인 카메라 입력 이미지이다. 이 이미지는 스타일 변환의 대상이다.
- Image Transform Net: 이 부분은 딥러닝 기반의 실시간 스타일 변환 네트워크다. ‘Input image’에 ‘Visual Effect Module’에서 제공된 ‘Reference style image’의 스타일을 적용하여 이미지를 변환한다. 논문에서는 인코더-디코더 구조에 5개의 잔여 블록을 사용한 네트워크를 활용했다.
- Loss Network (VGG 16): 스타일 변환 네트워크를 학습시키기 위해 사용되는 ‘Loss Network’다. 이미지 분류를 위해 사전 학습된 VGG 16 네트워크를 활용하여 지각 손실 함수(perceptual loss function)를 정의하고 이를 통해 스타일 변환의 품질을 향상시킨다. Perceptual losses for real-time style transfer and super-resolution 논문에서 제안된 방식을 따른다.
여기서 VGG모델은 CNN모델이다. 이미지 분류, 스타일 transfer, 특성 추출에 잘 쓰인다. 간단한 구조로도 갚인 신경망이 뛰어난 성능을 낸다.
- Output image: 상단의 ‘Visual Effect Module’에서 생성된 시각 효과 이미지와 하단의 ‘Image Transform Net’을 통해 스타일이 변환된 ‘Input image’가 결합되어 최종 결과 이미지를 생성한다.
Kinect 센서는 관객의 움직임을 감지하고 이 움직임 정보는 Open NI를 거쳐 시각 효과 모듈에서 작품의 내용을 변화시키는 데 사용된다. 동시에 Kinect의 입력 이미지는 시각 효과 모듈이 제공하는 스타일 이미지와 함께 스타일 변환 네트워크를 거쳐 예술적인 스타일이 적용된다. 이 두 결과가 합쳐져 최종적인 인터랙티브 미디어 아트 작품 이미지가 완성된다.
Proposed Artwork
Kinect의 depth image 정보를 사용하여 인간의 관절이 감지된다. OpenNI 라이브러리를 통해 Kinect 센서에서 얻은 깊이 정보를 기반으로 관객의 위치와 움직임 정보가 파악된다. Kinect와 OpenNI는 머리, 어깨, 손 등 인간 관절을 감지하며, 이 중 오른손 및 왼손 관절 영역이 특히 감지된다.
Experimental Results and Discussion
감지된 손 관절의 좌표와 거리를 계산하여 손 제스처를 인식하고, 이를 기반으로 아트워크의 visual effects를 제어한다. 왼손을 올리면 계절이 변경되고 오른손을 올리면 나무가 자라기 시작한다. 나무가 자란 후 박수를 치면 나뭇잎이 떨어지는 효과가 발생한다. 나뭇잎 색상은 계절 배경에 맞춰 다르게 표현된다.
세 번째로 실시간 스타일 변환이다. visual effect images를 reference style images로 사용해 딥러닝 기반의 실시간 스타일 변환 네트워크를 통해 스타일을 변환한다. 이 스타일 변환 네트워크는 Gatys 등의 방법보다 계산 효율성을 높이기 위해 image transform network와 loss network로 구성된다. 손실 네트워크는 이미지 분류를 위해 사전 학습된 네트워크를 사용하여 perceptual loss 함수를 정의한다. 이미지 변환 네트워크는 입력 이미지를 출력 이미지로 변환하도록 학습되며, encoder-decoder 구조에 다섯 개의 residual blocks을 포함한다. 실시간으로 스타일 변환된 이미지를 볼 수 있다.

Discussion
다시한번 인터랙티브 미디어 아트와 CV는 연결되어있구나를 느낄 수 있었다. kinect랑 openNI로 실시간 추적이 가능하고 관절 위치 좌표를 이용해 인터랙션 설계할 수 있다는 부분이 인상적이었다
또 vGG모델이 구조가 간단하고 일관되기 때문에 구현이 쉽고 스타일 전이 학습 성능이 좋다고 한다. 스타일 변환 부분에서는 VGG 모델이 인코더로 사용되는 이유를 이해할 수 있었다. VGG는 구조가 간단하고 일관되어 구현이 쉬울 뿐만 아니라 style transfer 학습에도 성능이 안정적이라는 장점이 있다. 특히 이 논문에서 사용된 방식은 Gatys 등의 초기 방식보다 계산 효율성이 높았고 이미지 변환 네트워크와 손실 네트워크를 분리해 실시간 스타일 변환을 가능하다. 이 자료는 2021년 자료이기 때문에 현재 스타일 전이에서 SOTA가 뭔지 추가로 찾아보고자 한다다.
Kinect와 OpenNI를 활용한 실시간 관절 추적 기술을 통해 제스처 기반 인터랙션이 어떻게 구현되는지 이해할 수 있었다.