[논문정리] ViCo: Plug-and-play Visual Condition for Personalized Text-to-image Generation
ViCo: Plug-and-play Visual Condition for Personalized Text-to-image Generation(2023).Shaozhe Hao, Kai Han, Shihao Zhao, Kwan-Yee K. Wong

ViCo는 기존 개인화 이미지 생성 방식의 문제점인 언어 지식 상실과 표현력 부족을 Frozen U-Net, 이미지 크로스 어텐션, 그리고 자체 객체 마스크 메커니즘을 통해 해결한 혁신적인 경량화 플러그 앤 플레이 모듈입니다.
Personalized Generation?
단 몇 장의 이미지(4~7장)로 묘사된 새로운 개념을 학습하여, 텍스트 프롬프트에 따라 사진처럼 현실적인 이미지를 생성하는 작업입니다.
고유한 특징 보존: 나만의 장난감, 특정 강아지 등
높은 유연성: 다양한 배경과 구도에서 재생성
정밀한 시각적 디테일: 텍스트만으로는 표현 불가능한 세부 묘사
개인화된 생성은 단 4장에서 7장의 페어링되지 않은 이미지만으로 새로운 개념을 학습하여 텍스트 프롬프트에 맞춰 실사 이미지를 만드는 작업입니다. 이 기술의 핵심은 고유한 특징을 보존하면서도 다양한 배경과 구도에서 유연하게 재생성하고, 텍스트만으로 불가능한 미세한 디테일을 살리는 것입니다.
 기존 연구의 한계점
기존 연구의 한계점
드림부스 같은 미세조정 방식은 U-Net 전체를 튜닝하므로 기존 언어 지식을 잃어버리는 언어 표류 현상과 모델 전체를 저장해야 하는 용량 오버헤드가 있습니다. 반면 텍스트 임베딩만 최적화하는 텍스트 인버전은 표현력이 부족하여 디테일을 담지 못하고 특정 학습 샘플에 오버피팅되는 한계가 존재합니다.
ViCo는 세 가지 차별점을 가집니다. 첫째, 원본 U-Net을 완전히 고정하여 사전 학습된 원래의 언어 지식을 완벽히 유지합니다. 둘째, U-Net의 단 6%에 해당하는 파라미터만 학습하므로 6분 내외로 매우 가볍고 빠릅니다. 셋째, 모듈식 설계로 다양한 모델에 유연하게 적용할 수 있는 플러그 앤 플레이 방식입니다.
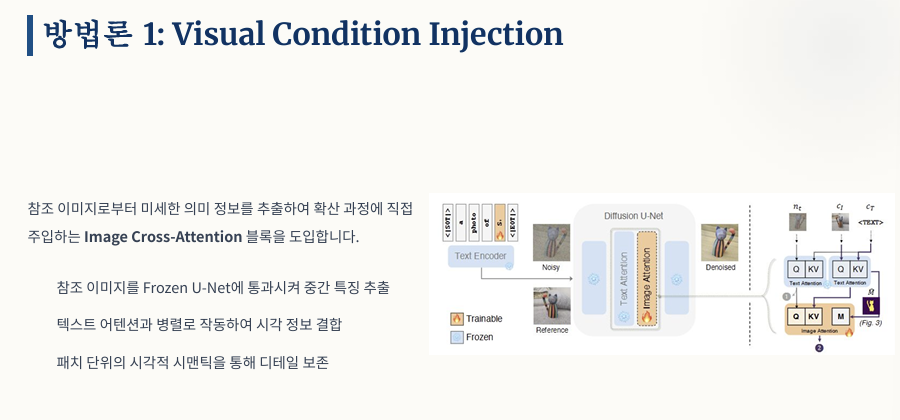
첫 번째 핵심 방법론은 참조 이미지에서 세부 의미 정보를 추출해 확산 과정에 직접 주입하는 이미지 크로스 어텐션 블록의 도입입니다. 참조 이미지를 고정된 U-Net에 통과시켜 중간 특징을 추출하고, 이를 텍스트 어텐션과 병렬로 작동시켜 패치 단위로 시각 디테일을 결합합니다.
기존 Diffusion 백본과 텍스트 인코더는 완전히 Frozen하여 언어 지식을 보존.
고유 사물 토큰 S* 임베딩과 추가된 이미지 어텐션 블록만 가볍게 학습(전체 대비 약 6% 파라미터)하여 경량화.
1단계(텍스트 맥락 결합): 노이즈 이미지(n_t)와 참조 이미지 (c_I)가 각각 입력된 텍스트 조건(c_T)과 결합하여 1차 어텐션을 통과.
2단계(시각 디테일 주입): 1차 결합된 노이즈 정보가 Query가 되고, 참조 이미지 정보가 Key/Value가 되어 이미지 어텐션을 통해 시각 디테일을 주입.
이 과정은 구체적으로 2단계로 진행됩니다. 1단계에서는 노이즈 이미지와 참조 이미지가 입력된 텍스트 조건과 각각 결합하여 1차 텍스트 맥락 결합 어텐션을 통과합니다. 2단계에서는 이 1차 결합된 노이즈 정보가 쿼리가 되고 참조 이미지 정보가 키와 밸류가 되어, 이미지 어텐션을 통해 시각 디테일을 노이즈 공간에 주입하게 됩니다.

두 번째 강점은 추가 비용 없이 전경 객체를 격리하는 메커니즘입니다. 크로스 어텐션 맵에서 자연스럽게 발생하는 객체 마스크를 활용해 배경의 간섭을 차단합니다. 오츠 임계값 알고리즘을 사용한 이진화 처리를 거쳐 라텐트 공간 내에서 배경 노이즈를 자동으로 억제합니다.
이 마스크 과정은 총 3단계로 분류됩니다. 먼저 참조 이미지가 텍스트 어텐션을 통과할 때 고유 사물 토큰인 S* 열을 분석해 사물 구역의 유사도 반응 분포를 계산합니다. 다음으로 오츠 알고리즘을 적용해 사물 영역은 1, 배경은 0인 이진 마스크를 생성합니다. 마지막으로 이 마스크를 이미지 어텐션 맵과 아마다르 곱 연산으로 필터링하여 배경을 소거하고 순수한 사물 디테일만 주입합니다.
사전 마스크 라벨링 없이 학습 과정에서 객체를 검출하며 참조 이미지의 배경 노이즈가 합성 공간을 오염시키는 것을 차단.
1.어텐션 기반 유사도 추출 (Text Attention)
참조 이미지가 기존 텍스트 어텐션을 통과할 때, 각 단어 토큰이 이미지의 어느 패치와 반응하는지 분포 계산. 새로 학습하려는 사물의 S*에 해당하는 열을 보면 사물이 위치한 구역에 유사도 반응 분포.
2.오츠 알고리즘 이진화 (Binarization)
오츠 임계값 알고리즘을 적용하여 이진화 처리. 사물이 존재하는 영역은 1, 무관한 배경 영역은 0으로 분리된 객체 마스크(M)가 생성. 3.아마다르 곱을 통한 배경 소거 (Hadamard Product) 생성된 이진 마스크(M)를 Image Attention 맵과 요소별 곱셈인 아마다르 곱 연산으로 필터링. 마스크의 배경 영역(0)과 곱해진 이미지 패치들은 소거되어 객체의 순수한 시각 디테일만 노이즈 공간에 주입
과적합을 방지하기 위해 학습 시 텍스트-이미지 어텐션 정규화 항을 표준 디노이징 손실 함수에 추가하여 학습 목표를 구성합니다. 스테이블 디퓨전을 백본으로 삼아 디코더 어텐션 레이어에 모듈을 삽입하며, 400 스텝의 짧은 학습과 낮은 학습률로 안정적인 최적화를 이뤄냅니다.
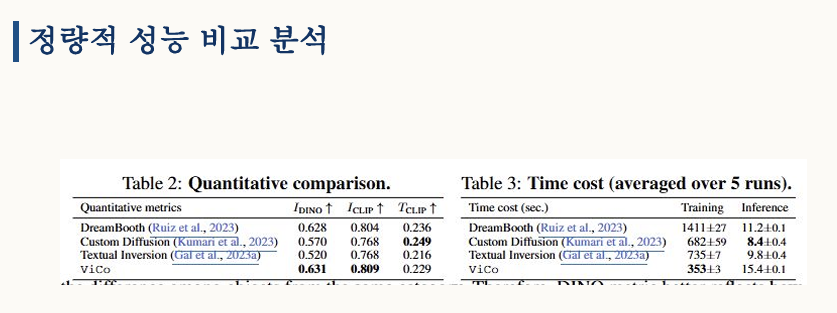
정량 지표를 보시면 ViCo는 모델을 고정한 상태를 유지하면서도, U-Net을 미세 조정하는 드림부스보다 우수하거나 대등한 객체 보존 및 클립 지표 성능을 보여줍니다. 또한 타 연구들이 수백 초에서 천 초 이상의 학습 시간을 소요하는 것과 비교해 보면, ViCo는 6분 내외라는 압도적으로 효율적인 시간 비용을 달성했습니다.

정성적인 시각 자료 비교에서도 ViCo는 동일한 소수 샷과 프롬프트 조건 아래 대상 사물의 세부 시각 특징과 텍스트 지시사항을 트레이드오프 없이 가장 균형 있게 보존하는 경향을 증명하고 있습니다.

기존 텍스트 인버전 방식은 새로 정의하려는 S*의 초기화 단어 단서에 크게 의존하여 잘못 초기화될 경우 표현 능력이 급격히 떨어졌습니다. 이와 달리 ViCo는 부족할 수 있는 텍스트 임베딩의 정보를 강력한 시각적 조건 주입이 보완하므로 초기화 단어 설정에 대한 민감도가 낮고 안정적입니다.
결론적으로 ViCo는 단일 GPU 기준으로 단 6분 만에 초고속 학습이 가능하며 원본 U-Net 파라미터 대비 약 6%의 가벼운 볼륨만 학습하므로 연산량과 비용을 극적으로 절감한 높은 모델 효율성을 자랑합니다.