[논문모델] ViCo: Plug-and-play Visual Condition for Personalized Text-to-image Generation
ViCo: Plug-and-play Visual Condition for Personalized Text-to-image Generation(2023).Shaozhe Hao, Kai Han, Shihao Zhao, Kwan-Yee K. Wong
저번에 읽은 ViCo 모델의 마스크 성능이 얼마나 되는지 궁금하여 모델을 돌려보고자 했다.
그 과정을 논문에 나온 흐름을 다시 보자면
사전 마스크 라벨링 없이 학습 과정에서 객체를 검출하며 참조 이미지의 배경 노이즈가 합성 공간을 오염시키는 것을 차단.
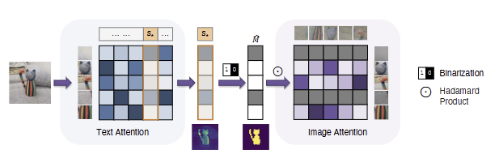
- 어텐션 기반 유사도 추출 (Text Attention)
- 오츠 알고리즘 이진화 (Binarization)
- 아마다르 곱을 통한 배경 소거 (Hadamard Product)
이러한 흐름으로 진행된다.
내가 실행한 모델의 흐름은
참조 이미지
→ 학습 ( token S★)
→ Inference (DDIM sampling)
→ Attention map 추출
→ Otsu 이진화
→ 배경 제거
이렇게 진행했다.
주요 코드는
Step 1. * 토큰 위치 찾기
1
placeholder_idx = torch.where(text_tokens == ph_tok)
Step 2. Attention weight 추출 (Patch 방식)
1
2
x_out, attn = orig_forward(x, return_attn=True)
attn_store[name] = attn # softmax weight 저장
Step 3. * 토큰 attention → Otsu → 마스크
1
2
3
a = attn[:, star_col_idx] # * 토큰만
thresh = threshold_otsu(avg_map) # 자동 이진화
mask = (avg_map > thresh) # foreground


segmentation 전문 모델이 아니라 attention map 기반이라 경계가 완벽하지 않다.
cross‑attention으로부터 유도한 유사도 맵을 Otsu로 이진화한 결과를 사용하므로 경계가 완벽하지 않다
얼굴: attention 높음 → threshold 넘음 → foreground
몸통 하단: attention 약함 → threshold 못 넘음 → background로 분류

학습데이터가 아닌 인터넷 데이터로 시도.
This post is licensed under CC BY 4.0 by the author.