[머신러닝] 6-1. 군집 알고리즘
흑백 사진을 분륳기 위해 여러 가지 아이디어를 내면서 비지도 학습과 군집 알고리즘에 대해 이해하자
오옹 제가 좋아하는 부분이네요. 잘 소화해보도록 하겠습니다
타깃을 모르는 비지도 학습
사진을 종류별로 분류하고 싶다. 하지만 이게 뭔지는 알지 못한다! 이때 우리는 비지도 학습을 쓸 수 있다.
과일 사진 데이터 준비하기
코랩으로 다운로드
https://www.kaggle.com/coltean/fruits {: .prompt-tip }
1
!wget https://bit.ly/fruits_300 -0 fruits_300.npy
1
2
3
#넘파이와 맷플롯립 패키지 임포트
import numpy as np
import matplotlib.pypot as plt
load()로 npy 파일 로드하기
1
fruits=np.load('fruits_300.npy')
1
2
3
#배열 크기 확인하기
print(fruits.shape)
#(300,100,100)
첫번째 300이 샘플의 개수, 두번째가 이미지 높이, 세번째가 이미지 너비! 각 픽셀은 넘파이 배열의 원소 하나에 대응한다. 배열의 크기가 100x100인 것을 알 수 있다.
첫번째 이미지의 첫번째 행을 확인해보자
1
print(fruits[0, 0, :])
요 넘파이 배열은 흑백 사진을 담고 있어서 0에서 255까지의 정숫값을 가진다.
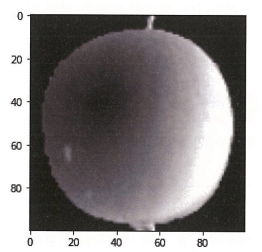
우선 그림으로 확인해보자
맷플롯립의 inshow() 함수를 사용해서 넘파이 배열로 저장된 이미지를 그려보자. 흑백이니까 cmap=’gray’
1
2
plt.inshow(fruits[0], smap='gray')
plt.show()
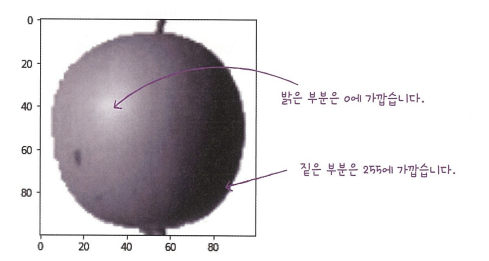
0에 가까우면 어둡게 수가 크면 밝게 포함된다.
우리가 보는 이 그림은 흑백 반전되어 있다. 이미지를 넘파이 배열로 바꿀 때 반전된 것이다.
왜???
왜냐면! 우리는 사과에 집중해야해! 우리 눈에는 흰 색이 별로 집중되지 않겠ㅈ만 컴퓨터는 255와 가까운 큰 수를 가진 흰 색에 집중할 것이기 때문이지!!
그래도.. 별로 안예쁘잖아! 다 방법이 있지 cmap=’gray_r’하면 된다고!
1
2
plt.imshow(fruits[0], cmap='gray_r')
plt.show()
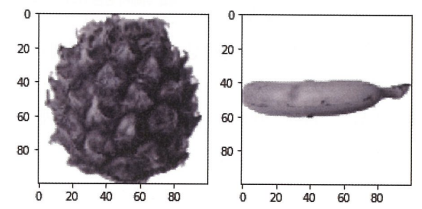
파인애플이랑 바나나도 확인해봐야지
1
2
3
4
fig, axs=plt.subplots(1,2)
axs[0].imshow(fruits[100], cmap='gray_r')
axs[1].imshow(fruits[200], cmap='gray_r')
plt.show()
subplots()는 여러개의 그래프를 배열처럼 쌓을 수 있도록 한다.
subplot(1,2): 하나의 행과 2개의 열
픽셀값 분석하기
100 100 이미지를 배열 계산의 편리함을 위해서 길이가 10000인 1차원 배열로 만들도록 하겠다
슬라이싱을 이용해서 순서대로 100개씩 선택하고 reshape로 두 번째 차원과 세 번째 차원을 합친다. 여기서 첫번째 차원을 -1로 하면 자동으로 할당된다
1
2
3
apple=fruits[0:100].reshape(-1, 100*100)
pineapple=fruits[100:200].reshape(-1, 100*100)
banana=fruits[200:300].reshape(-1, 100*100)
1
2
3
#배열 크기 확인하기
print(apple.shape)
#(100, 10000)
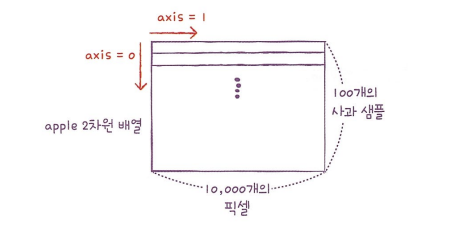
axis=1: 열 방향
axis=0: 행 방향
1
2
#사과 샘플 100개의 픽셀 평균값 계산
print(apple.mean(axis=1))
히스토그램을 그려서 평균값 분포를 확인하자. 값이 발생한 빈도를 그래프로 표현한다. x축은 구간(계급), y축은 발생 빈도(도수)이다.
hist로 히스토그램 그리기
alpha로 투명도 조절하기
legend로 어떤 과일 히스토그램인지 범례
1
2
3
4
5
plt.hist(np.mean(apple, axis=1), alpha=0.8)
plt.hist(np.mean(pineapple, axis=1), alpha=0.8)
plt.hist(np.mean(banana, axis=1), alpha=0.8)
plt.legend(['apple','pineapple','banana'])
plt.show()
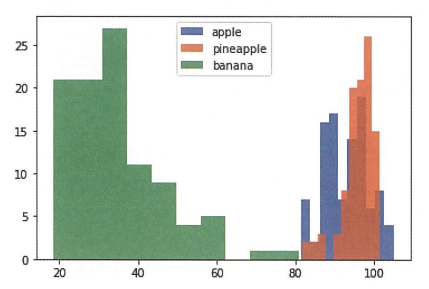
흐음 사과랑 파인애플이 겹쳐있어서 별로다. 그렇다면 샘플의 평균값이 아니니 픽셀별 평균값은 어떻까? 전체 샘플로 평균을 계산해보자
이때 axis=0으로 하면 된다.
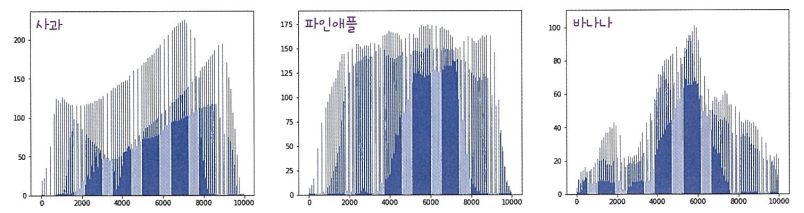
bar로 평균값을 막대그래프로 그리자
subplot으로 3개의 서브 그래프를 만들어 사과, 파인애플, 바나나 막대그래프를 그리자
1
2
3
4
5
fig, axs=plt.subplots(1,3,figsize=(20,5))
axs[0].bar(range(10000), np.mean(apple, axis=0))
axs[1].bar(range(10000), np.mean(pineapple, axis=0))
axs[2].bar(range(10000), np.mean(banana, axis=0))
plt.show()
픽셀 평균값을 100x100으로 바꿔서 비교해보자 픽셀 평균을 모두 합쳤다고 생각하면 된다
1
2
3
4
5
6
7
8
apple_maen=np.mean(apple, axis=0).reshape(100,100)
pineapple_mean=np.mean(pineapple, axis=0).reshape(100,100)
banana_mean=np.mean(banana, axis=0).reshape(100,100)
fig, axs=plt.subplots(1,3,figsize=(20,5))
axs[0].imshow(apple_mean, cmap='gray_r')
axs[1].imshow(pineapple_mean, cmap='gray_r')
axs[2].imshow(banana_mean, cmap='gray_r')
plt.show()

평균값과 가까운 사진 고르기
abs=np.absolute는 절댓값을 계산한다.
fruit의 샘플에서 apple_mean을 뺀 절댓값의 평균을 계산해보자
1
2
3
4
5
abs_diff=np.abs(fruits-apple_mean)
abs_mean=np.mean(abs_diff, axis=(1,2))
print(abs_mean.shape)
#(300,)
apple_mean과 오차가 가장 작은 샘플 100개 고르지
np.argsort는 작은 것에서 큰 순서대로 나열한 abs_mean 배여르이 인덱스를 반환한다.
1
2
3
4
5
6
7
apple_index=np.argsort(abs_mean)[:100]
fig, axs=plt.subplots(10,10,figsize(10,10))
for i in range(10):
for j in range(10):
axs[i,j].imshow(fruits[apple_index[i*10+j]], cmap='gray_r')
axs[i, j].axis('off')
plt.show()

figsize는 크기 지정
axis(‘off’)로 좌표축 삭제
비슷한 샘플끼리 그룹으로 모으는 것을 군집이라고 한다. 이는 비지도 학습 작업 중 하나이다. 군집 알고리즘에서 만든 그룹을 클러스터라고 한다.
마무리
키워드
비지도 학습 히스토그램 군집