[DeepLearning.AI] Course2.W1 Improving Deep Neural Networks
Train/Dev/Test Sets (C2W1L01)
모델의 성능을 효율적으로 개선하기 위한 데이터 세트(훈련, 개발, 테스트 세트) 설정 방법
1. 반복적인 과정
초기 설정의 어려움:
layer 개수, hidden unit 수, 학습률, 활성화 함수 등 수많은 하이퍼파라미터의 최적값을 처음부터 완벽하게 추측하는 것은 거의 불가능
반복 순환(Cycle):
‘Idea -> Code -> Experiment’ 의 사이클을 반복하며 모델을 개선해 나가는 과정. 얼마나 효율적으로 빠르게 돌 수 있느냐가 좋은 모델을 만드는 핵심이다. 데이터를 잘 설정하면 이 과정을 빠르게 할 수 있다.
2. 데이터 세트의 구성과 역할
전통적인 구성:
전체 데이터를 훈련(Train), 개발(Dev, 또는 교차 검증 세트), 테스트(Test) 세트로 나눈다.
- 훈련 세트:
알고리즘을 학습 - 개발(Dev) 세트:
다양한 모델 중 어떤 것이 가장 성능이 좋은지 평가하고 선택 - 테스트 세트:
최종 선택된 모델의 성능을 편향 없이 측정
3. 데이터 세트 비율의 변화
과거:
데이터가 적었을 떄는 60/20/20% (훈련/개발/테스트) 또는 70/30% (훈련/테스트) 비율로 나누는 것이 일반적이었다.
현대:
데이터가 100만 개 이상인 경우 개발 및 테스트 세트는 굳이 전체의 20%를 할당할 필요가 없다.비율은 98/1/1% 혹은 99.5/0.25/0.25% 와 같이 훈련 세트에 많은 비중을 둔다.
4. 데이터 Distribution 불일치
훈련 데이터와 테스트 데이터의 출처(분포)가 다른 경우가 많다.
훈련 데이터는 웹에서 긁어온 고화질 고양이 사진(많은 양)이지만 실제 앱 서비스에서 분류해야 할 개발/테스트 데이터는 사용자가 폰으로 찍은 저화질 사진(적은 양)일 수 있다.
핵심 원칙:
훈련 데이터는 다른 분포에서 가져오더라도 Dev 세트와 Test 세트는 same distribution에서 가져와야 한다. 이는 개발 세트에서 목표로 삼은 성능 지표가 실제 테스트 환경에서도 유효하도록 하기 위함.
5. 테스트 세트의 생략 가능성
테스트 세트의 목적:
최종 모델 성능에 대한 편향 없는 추정치를 얻는 것.
테스트 세트가 없는 경우:
만약 편향 없는 추정치가 굳이 필요 없다면 테스트 세트 없이 훈련/개발 세트만으로 구성해도 된다. 종종 개발 세트를 ‘테스트 세트’라고 부르지만 실제로는 개발 세트에 맞춰 모델을 튜닝(과적합)하고 있으므로 개발 세트입니다.
Bias/Variance (C2W1L02)
편향(Bias)과 분산(Variance) 을 훈련 세트와 개발 세트의 오차율을 통해 분석하는 방법
1. 편향과 분산 (2차원 데이터)
딥러닝 시대에는 ‘편향-분산 트레이드오프’에 대한 논의는 줄었지만, 여전히 오류를 진단하는 핵심 도구이다.
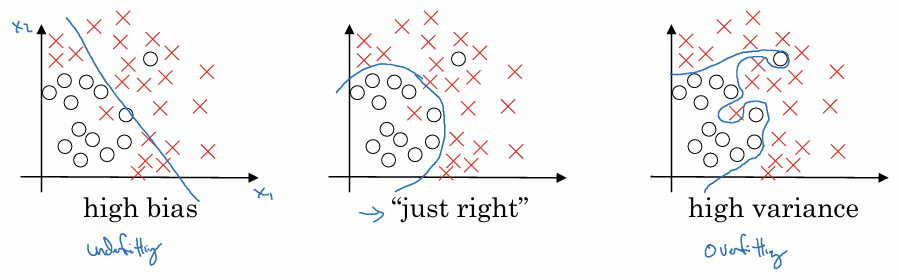
High Bias:
Underfitting
데이터는 곡선 분포인데 직선으로 분류하려는 로지스틱 회귀
Just Right:
편향과 분산 사이의 균형을 찾아 데이터의 패턴을 잘 설명하는 상태
High Variance:
Overfitting
모든 훈련 데이터를 완벽하게 통과하려고 지나치게 복잡하게 구부러진 신경망
2. 고차원 데이터에서의 진단 지표 (훈련 세트 vs 개발 세트)
고차원 데이터는 시각화할 수 없으므로 Train Set Error 와 Dev Set Error 두 가지 숫자를 비교한다. 이때 인간 수준의 성능(베이즈 오차)이 0%에 가깝다고 가정
High Variance
훈련 오차 1%, 개발 오차 11%.
훈련 세트는 매우 잘 맞추지만, 보지 못한 개발 세트에서는 성능이 떨어진다. 훈련 데이터에 과대적합되어 일반화에 실패
High Bias
훈련 오차 15%, 개발 오차 16%.
훈련 세트조차 제대로 맞추지 못하고 있다. 데이터에 과소적합된 상태.
High Bias & High Variance
훈련 오차 15%, 개발 오차 30%.
훈련 세트도 잘 맞추지 못하고(높은 편향), 개발 세트에서는 오차가 훨씬 더 커진다(높은 분산). 최악
Low Bias & Low Variance
훈련 오차 0.5%, 개발 오차 1%.
훈련 세트도 잘 맞추고 일반화도 잘 된 이상적인 상태.
훈련 세트 오차를 통해 알고리즘이 데이터에 얼마나 잘 적합하는지(편향 문제)를 본다.
훈련 오차와 개발 오차의 차이를 통해 분산 문제(일반화 성능)가 얼마나 심각한지 파악한다.
3. High Bias & High Variance
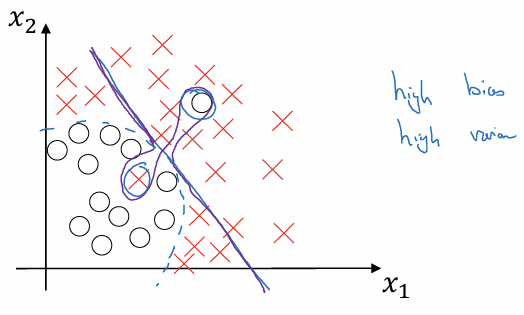
전체적으로는 데이터의 경향을 따르지 못하는 선형 모델(높은 편향)이면서 동시에 몇몇 outlier나 특정 샘플을 맞추기 위해 국소적으로 심하게 구불거리는(높은 분산) 형태.
일부 영역에서는 과소적합되고, 다른 영역에서는 과대적합되는 현상이 발생할 수 있다.
Basic Recipe for Machine Learning (C2W1L03)
이전 강의에서 다룬 ‘Bias/Variance’ 바탕으로 실제로 모델 성능을 개선하기 위해 어떤 조치를 취해야 하는지 체계적인 머신러닝 Basic Recipe 제시.
1. High Bias 해결
모델 학습 후 가장 먼저 해야 할 질문은 “알고리즘이 높은 편향을 가지는가?” 이를 위해 Training Set 의 성능을 확인
해결책:
만약 훈련 세트조차 잘 맞추지 못한다면(높은 편향) 다음 방법들을 시도.
더 큰 네트워크 선택:
Hidden layers이나 Hidden units의 수를 늘린다. 이는 편향을 줄이는 데 매우 효과적이다.
더 오래 훈련시키기:
학습 시간을 느리기.
최적화 알고리즘 변경:
더 발전된 최적화 알고리즘 사용.
신경망 아키텍처 변경:
문제에 더 적합한 구조를 찾을 수도 있지만 항상 성공하는 것은 아니다
충분히 큰 네트워크를 사용하면 거의 항상 훈련 데이터에 잘 맞도록 편향을 줄일 수 있다. 편향 문제가 해결될 때까지 반복한다.
2. High Variance 해결
편향 문제를 해결하여 훈련 세트 성능이 좋아졌다 -> “분산 문제가 있는가?” 이를 위해 개발 세트(Dev Set) 의 성능을 확인
해결책:
훈련 세트 성능은 좋지만 개발 세트 성능이 나쁘다면(높은 분산/과대적합)?
더 많은 데이터 확보:
분산 문제를 해결하는 가장 확실하고 좋은 방법.
Regularization:
데이터를 더 얻을 수 없는 경우 과대적합을 줄이기 위해 사용(다음 강의 주제).
신경망 아키텍처 변경
낮은 편향과 낮은 분산을 모두 달성할 때까지 1단계와 2단계를 반복.
3. 진단의 중요성
문제의 원인이 편향인지 분산인지 명확히 파악하는 것이 중요.
높은 편향 문제가 있는데 더 많은 데이터를 수집하는 것은 시간 낭비. 데이터 추가는 주로 분산 문제를 해결하는 데 도움이 되기 때문.
4. Trade-off의 해소
과거:
딥러닝 이전에는 편향을 줄이면 분산이 커지고 분산을 줄이면 편향이 커지는 ‘편향-분산 트레이드오프’가 심각했다.
현대:
딥러닝과 빅데이터 시대에는 이 두 가지를 독립적으로 제어할 수 있는 도구가 생겼다.
- 더 큰 네트워크를 훈련하면 분산을 해치지 않고 편향만 감소시킬 수 있다.
- 더 많은 데이터를 얻으면 편향을 해치지 않고 분산만 감소시킬 수 있다.
서로 부정적인 영향을 주지 않고 편향과 분산을 각각 줄일 수 있다는 점이 Supervised Learning에서 딥러닝이 강력한 성능의 주요 원인 중 하나이다.
5. 비용과 정규화
큰 네트워크를 사용하는 것의 주된 비용은 computational time 뿐이며 성능 측면에서는 거의 해가 없다.
Regularization는 분산을 줄이는 데 매우 유용하지만 편향을 약간 증가시킬 수도 있다. 하지만 충분히 큰 네트워크를 사용하면 이러한 트레이드오프를 최소화할 수 있다.
Regularization (C2W1L04)
지난 강의에서 High Variance, 과대적합 문제를 해결하기 위한 핵심 기법으로 소개된 Regularization의 원리와 구현 방법.
1. 과대적합 해결을 위한 정규화 도입
문제:
신경망이 과대적합 문제를 겪고 있을 때 더 많은 데이터를 얻는 것은 비용이 많이 든다.
해결책:
정규화는 데이터 추가 없이 과대적합을 막고 분산을 줄이는 매우 효과적인 방법.
기본 아이디어 (로지스틱 회귀):
비용 함수 $J$ 에 Penalty term 을 추가한다.
기존 비용 함수 + $\frac{\lambda}{2m} ||w||^2$
2. L2 정규화 vs L1 정규화
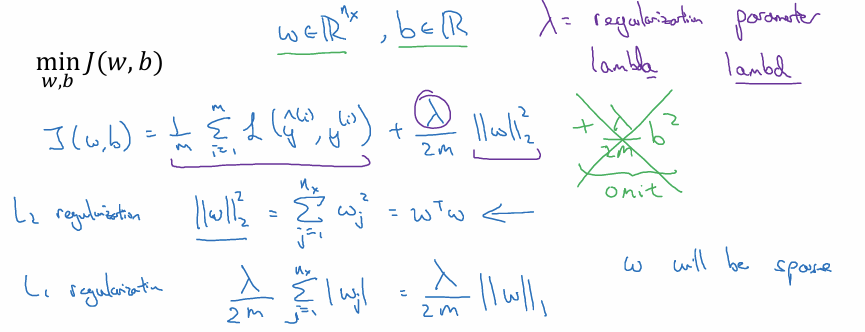
L2 정규화:
매개변수 벡터 $w$ 의 Euclidean norm의 제곱( $w^Tw$ )을 사용하는 방식. 가장 보편적으로 사용된다.
매개변수 b 제외:
보통 가중치 $w$ 만 정규화하고 편향 $b$ 는 제외한다. $w$ 는 고차원 행렬이라 매개변수가 매우 많지만 $b$ 는 각 층마다 하나의 숫자에 불과하여 영향이 미미하기 때문이다.
L1 정규화:
$w$ 의 절대값 합( $||w||_1$ )을 사용하는 방식. $w$ 가 희소(sparse) 해져서 0이 되는 값이 많아진다. 모델 압축 효과가 있지만 일반적으로는 L2 정규화가 훨씬 더 많이 쓰인다.
하이퍼파라미터 $\lambda$ :
정규화 강도를 조절하는 $\lambda$ 는 개발(Dev) 세트를 통해 최적의 값을 찾아야 하는 하이퍼파라미터이다.
3. 신경망에서의 정규화 적용 (프로베니우스 노름)

비용 함수 확장:
신경망의 비용 함수에는 모든 층( $L$ )의 가중치 행렬 $w$ 에 대한 정규화 항을 더한다.
Frobenius Norm:
행렬의 정규화에는 행렬 내 모든 원소의 제곱의 합을 의미하는 프로베니우스 노름( $|| \cdot ||_F$ )을 사용한다. 벡터의 L2 노름을 행렬로 확장한 개념.
4. 경사 하강법 구현과 Weight Decay
미분 값( $dw$ ) 수정:
Backpropagation 과정에서 계산된 $dw$ 에 정규화 항의 미분 값인 $\frac{\lambda}{m} w$ 를 더해준다.
가중치 업데이트:
수정된 $dw$ 를 사용하여 가중치를 업데이트하는 식은 $w^{[l]} = w^{[l]} - \alpha \cdot (\text{기존 } dw + \frac{\lambda}{m} w^{[l]})$ 이 된다.
가중치 감쇠의 의미:
정리하면 $w^{[l]} = (1 - \frac{\alpha \lambda}{m})w^{[l]} - \alpha(\text{기존 } dw)$ 가 된다. 여기서 $(1 - \frac{\alpha \lambda}{m})$ 항은 1보다 약간 작은 값이므로 매 단계마다 가중치 $w$ 의 크기를 조금씩 줄여준다.
이러한 이유로 L2 정규화는 Weight Decay 라고도 한다.
Why Regularization Reduces Overfitting (C2W1L05)
Regularization가 어떻게 Overfitting을 방지하고 Variance을 줄이는지 그 작동 원리에 대한 두 가지 직관과 구현 시 주의사항을 설명.
1. 신경망의 가중치 감소와 단순화
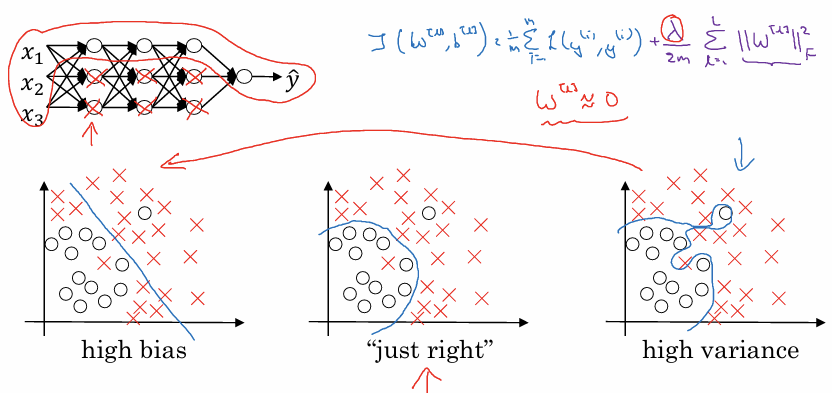
비용 함수와 패널티:
정규화를 적용하면 비용 함수 $J$ 에 가중치 행렬 $W$ 가 너무 커지는 것을 막기 위한 추가적인 항(프로베니우스 노름 등)이 더해진다.
가중치(W)의 감소:
정규화 매개변수 $\lambda$ 를 크게 설정하면 비용을 최소화하는 과정에서 가중치 행렬 $W$ 가 0에 상당히 가까운 값으로 설정된다.
네트워크의 단순화:
$W$ 가 0에 가까워지면 hidden unit들의 영향력이 줄어든다. 이는 복잡하고 깊은 신경망을 마치 로지스틱 회귀 유닛이 많은 단순한 신경망처럼 동작하게 만든다.
과대적합 방지:
은닉 유닛을 완전히 삭제하는 것은 아니지만 그 영향력을 최소화함으로써, 네트워크가 훈련 데이터의 노이즈까지 학습하는 과대적합 상태에서 벗어나게 한다. $\lambda$ 가 너무 크면 과소적합이 될 수 있으므로 적절한 값을 찾아야 한다.
2. 활성화 함수의 Linear 구간 활용
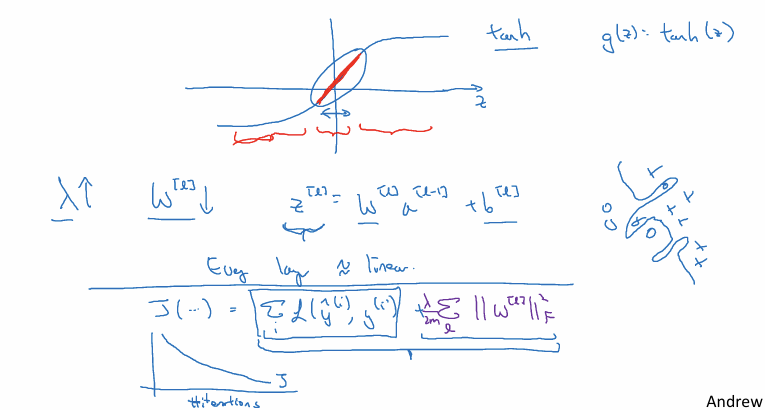
Tanh 함수:
활성화 함수 $g(z) = \tanh(z)$ 를 사용할 때 입력값 $z$ 가 0에 가까운 작은 범위에 있으면 함수는 거의 linear처럼 동작하고 $z$ 값이 클 때만 비선형적인 곡선을 그린다.
선형성 유도:
$\lambda$ 가 커져서 가중치 $W$ 가 작아지면, $z$ ( $= Wa + b$ )의 값도 상대적으로 작아지게 된다. $z$ 가 작은 범위에 머무르면 활성화 함수가 선형 영역에서 작동하게 된다.
복잡한 경계 생성 억제:
모든 층이 선형에 가까워지면 전체 신경망도 선형 함수처럼 단순해진다. 선형 네트워크는 매우 복잡하고 구불구불한 비선형 decision boundary를 만들 수 없으므로 데이터에 과대적합될 가능성이 줄어든다.
3. 구현 시 팁: 비용 함수(J) 디버깅
올바른 J의 정의:
경사 하강법이 잘 작동하는지 확인하기 위해 반복 횟수에 따른 비용 함수 $J$ 의 감소 그래프를 그릴 때 주의해야 한다.
단조 감소 확인:
이때 $J$ 는 단순히 훈련 데이터의 Loss 합만이 아니라 정규화 항(가중치 패널티)까지 포함된 새로운 비용 함수여야 한다. 정규화 항을 포함하지 않고 그래프를 그리면 $J$ 가 매 반복마다 monotonically decrease하지 않는 것처럼 보일 수 있다.
Dropout Regularization (C2W1L06)
이 강의는 L2 정규화와 더불어 Overfitting을 막는 매우 강력한 기법인 Dropout의 작동 원리와 구현 방법(역 드롭아웃)
1. Dropout의 작동 원리
신경망의 각 Layer을 지날 때마다 각 노드(뉴런)에 대해 동전을 던지듯 확률적으로 삭제 여부를 결정.
0.5의 확률을 설정하면 각 노드는 50% 확률로 유지되거나 삭제된다. 노드가 삭제되면 해당 노드와 연결된 들어오고 나가는 모든 Link도 함께 제거된다.
효과:
원래의 거대한 신경망보다 훨씬 작고 간소화된 네트워크가 만들어진다. 이 축소된 네트워크를 사용해 역전파 훈련을 진행한다.
무작위성:
훈련 샘플마다 그리고 경사 하강법의 매 iteration마다 삭제되는 노드가 무작위로 달라딘다. 매번 서로 다른 형태의 축소된 네트워크를 훈련시키는 효과를 준다.
2. 드롭아웃 구현: Inverted Dropout
가장 보편적으로 사용되는 Inverted Dropout
- 무작위 벡터 생성
d3라는 무작위 행렬 생성.keep_prob(유지 확률, 예: 0.8)보다 작은 값은 1(True), 큰 값은 0(False)으로 설정.80%의 노드는 유지하고 20%는 삭제하겠다는 의미.
노드 삭제
활성화 값a3에d3를 요소별 곱셈(Element-wise multiplication). 이 과정에서 20%의 뉴런 활성화 값이 0이 되어 삭제된다.- 스케일링
최종적으로 얻은a3값을keep_prob(0.8)으로 나눈다 (a3 /= keep_prob).
이유:
뉴런의 20%를 0으로 만들면 다음 층으로 전달되는 값( $z^{}$ )의 기댓값이 20%만큼 줄어든다. 이를 방지하기 위해 남은 값들을keep_prob으로 나눠서 값을 키워준다.
이 과정을 통해 훈련 단계에서의 활성화 값 기댓값을 원래대로 유지할 수 있다.
3. Test 단계에서의 동작
드롭아웃 미사용:
훈련이 끝난 후 실제로 예측을 수행하는 테스트 단계에서는 드롭아웃을 사용하지 않는다. 테스트 결과가 무작위로 변하는(노이즈) 것을 원하지 않기 때문이다. 역 드롭아웃의 이점:
훈련 단계에서 이미 keep_prob으로 나누는(역 드롭아웃) 처리를 했기 때문에 테스트 단계에서는 활성화 값에 별도의 스케일링을 할 필요가 없다.
드롭아웃은 훈련 중 무작위로 뉴런을 끄면서 더 작은 네트워크들을 학습시키는 방식이며 ‘역 드롭아웃’을 통해 훈련과 테스트 시의 값의 크기(기댓값)를 일치시킨다.
Understanding Dropout (C2W1L07)
Dropout 기법이 왜 Regularization 효과를 내는지와 실제 구현 시 keep_prob 설정 팁
1. 드롭아웃의 작동 직관: 가중치 분산
단일 뉴런의 관점:
드롭아웃을 적용하면 입력값 중 일부가 무작위로 삭제될 수 있습니다. 따라서 특정 뉴런은 어떤 입력 Feature이 언제 사라질지 모르기 때문에 특정 입력 하나에만 의존(큰 가중치를 부여)할 수 없게 된다.
가중치 확산(Spread out):
결과적으로 뉴런은 모든 입력에 대해 가중치를 조금씩 나누어 분산시키는 방식을 택하게 된다.
L2 정규화와의 유사성:
이렇게 가중치를 분산시키면 가중치 벡터의 Norm의 제곱값이 줄어든다. 가중치의 크기를 줄여 과대적합을 막는 L2 정규화와 매우 유사한 효과
2. 하이퍼파라미터 keep_prob의 설정
Layer별 차등 적용:
keep_prob은 각 층의 유닛을 유지할 확률이다. 모든 층에 같은 값을 쓸 필요는 없다.
매개변수가 많은 층:
예를 들어 $W^{}$ 와 같이 매개변수 행렬이 커서 과대적합의 우려가 가장 큰 층에는 keep_prob을 낮게 설정하여 강력한 정규화를 적용한다.
매개변수가 적은 층:
과대적합 우려가 적은 층은 keep_prob을 높게 잡거나 아예 1.0(드롭아웃 미적용)으로 설정할 수 있다.
입력 층(Input Layer):
이론적으로 입력 층에도 드롭아웃을 쓸 수 있지만 정보 손실을 막기 위해 실제로는 잘 사용하지 않는다. 사용하더라도 keep_prob을 매우 높게 설정.
3. 드롭아웃 사용 시 주의사항 및 단점
컴퓨터 비전(CV) 분야의 표준:
컴퓨터 비전은 입력 픽셀 수에 비해 데이터가 부족한 경우가 많아 과대적합이 빈번하게 발생하므로 드롭아웃을 거의 기본값처럼 사용.
사용 원칙:
하지만 다른 분야에서는 과대적합 문제가 발생하기 전까지는 굳이 드롭아웃을 사용하지 않는 것이 좋다.
비용 함수( $J$ )의 정의 문제:
드롭아웃의 가장 큰 단점은 매 반복마다 삭제되는 노드가 무작위로 바뀌기 때문에 명확하게 정의된 비용 함수 $J$ 가 없다 이로 인해 경사 하강법이 올바르게 작동하여 $J$ 가 단조 감소하는지 그래프로 확인하며 디버깅하기가 어렵다.
4. 디버깅 팁
우선 끄고 확인:
코드를 검증할 때는 먼저 keep_prob을 1로 설정하여 드롭아웃을 끈다.
단조 감소 확인:
드롭아웃이 꺼진 상태에서 비용 함수 $J$ 가 반복마다 줄어드는지 확인.
재적용:
경사 하강법이 잘 작동하는 것을 확인한 후 다시 드롭아웃을 켜서 학습을 진행.
드롭아웃은 뉴런이 특정 입력에 올인하는 것을 막아 가중치를 분산시킴으로써(L2 정규화와 유사) 과대적합을 방지한다. 이때 과대적합 위험이 큰 층일수록 keep_prob을 낮게 설정하여 더 강하게 규제한다.
Other Regularization Methods (C2W1L08)
Overfitting을 방지하기 위해 앞서 배운 L2 정규화나 드롭아웃 외에 사용할 수 있는 Data Augmentation와 Early Stopping
1. Data Augmentation
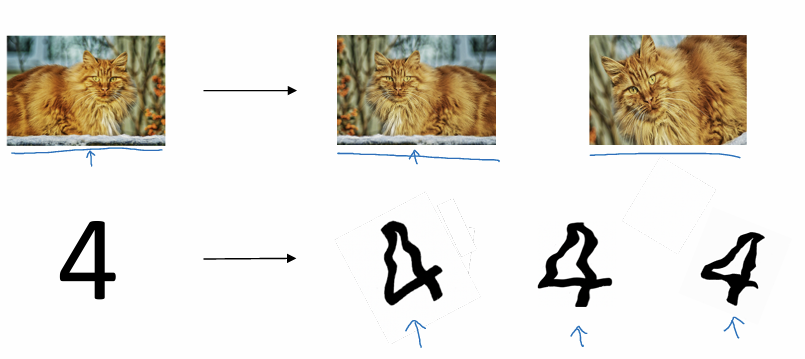
과대적합을 해결하는 가장 좋은 방법은 더 많은 훈련 데이터를 확보하는 것이지만 이는 비용이 많이 들거나 불가능할 수 있다
방법:
기존 훈련 데이터를 조작하여 새로운 샘플을 인위적으로 만든다
- 이미지 처리:
이미지를 수평으로 뒤집거나 무작위로 회전 및 확대하여 데이터셋을 늘린다. - 문자 인식(OCR):
숫자 이미지에 무작위 회전이나 왜곡을 주어 새로운 훈련 샘플을 생성.
장단점:
이렇게 생성된 ‘가짜’ 데이터는 완전히 새로운 독립적인 데이터만큼 많은 정보를 주지는 않지만 컴퓨터 비용이 거의 들지 않고 구현하기 쉽다는 큰 장점이 있어 과대적합을 줄이는 정규화 기법으로 자주 사용.
2. Early Stopping
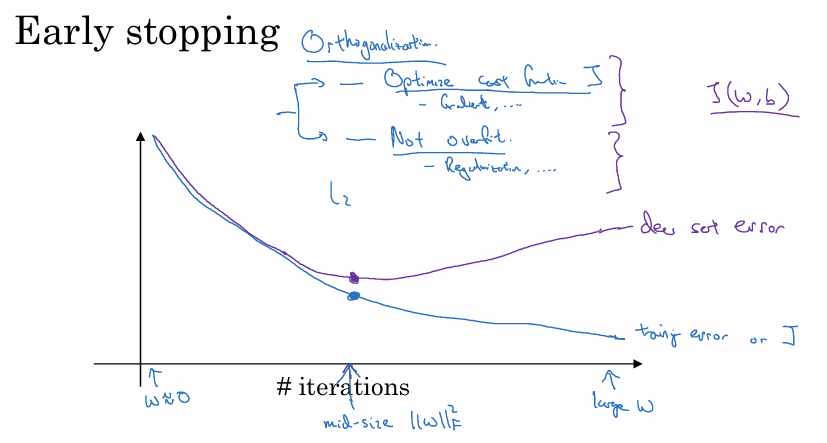
훈련 과정에서 Training Error와 Dev Set Error를 그래프로 함께 모니터링. 훈련 오차나 비용 함수 $J$ 는 반복할수록 계속 감소한다. 반면 개발 세트 오차는 처음에는 감소하다가 어느 시점부터 과대적합이 시작되면서 다시 증가한다.
개발 세트 오차가 가장 낮은 지점(오차가 증가하기 시작하는 직전)에서 훈련을 중단하고 그때의 파라미터를 최종 모델로 선택한다.
작동 원리:
파라미터 $W$ 는 0에 가까운 작은 값으로 초기화된다.
훈련이 진행될수록 $W$ 의 값은 점점 커진다.
훈련을 중간에 멈추면 $W$ 가 지나치게 커지기 전인 ‘중간 크기’ 상태를 유지하게 되며 이는 $W$ 의 Norm을 작게 유지하는 L2 정규화와 유사한 효과를 낸다.
3. 조기 종료의 장단점과 Orthogonalization
단점 (직교화 위배):
머신러닝 과정은 보통
- 비용 함수 최적화
- 과대적합 방지
라는 두 단계를 독립적으로 수행해야 효율적이다(직교화).
하지만 조기 종료는 비용 함수 $J$ 가 충분히 작아지기 전에 과대적합을 막으려고 하므로 두 가지 목표를 한 번에 섞어서 해결하려는 접근.
이로 인해 문제를 복잡하게 만들 수 있다. 반면 L2 정규화는 훈련을 끝까지 시킬 수 있어 최적화와 정규화를 분리해서 생각할 수 있다.
장점 (효율성):
L2 정규화는 적절한 하이퍼파라미터 $\lambda$를 찾기 위해 여러 값을 시도하며 모델을 여러 번 훈련해야 하므로 계산 비용이 많이 든다.
반면 조기 종료는 단 한 번의 경사 하강법 실행만으로도 작은 $W$, 중간 $W$, 큰 $W$를 모두 거치며 최적점을 찾을 수 있어 매우 효율적이다.
L2 정규화를 사용하여 $\lambda$를 튜닝하는 방식을 선호하지만(컴퓨터 자원이 충분할 때) 조기 종료 역시 별다른 하이퍼파라미터 탐색 없이 비슷한 효과를 낼 수 있어 실무에서 매우 자주 사용되는 기법이다.
Normalizing Inputs (C2W1L09)
신경망의 훈련 속도를 획기적으로 높일 수 있는 Normalizing Inputs 기법의 방법과 그 원리.
1. 입력 정규화의 2단계 과정
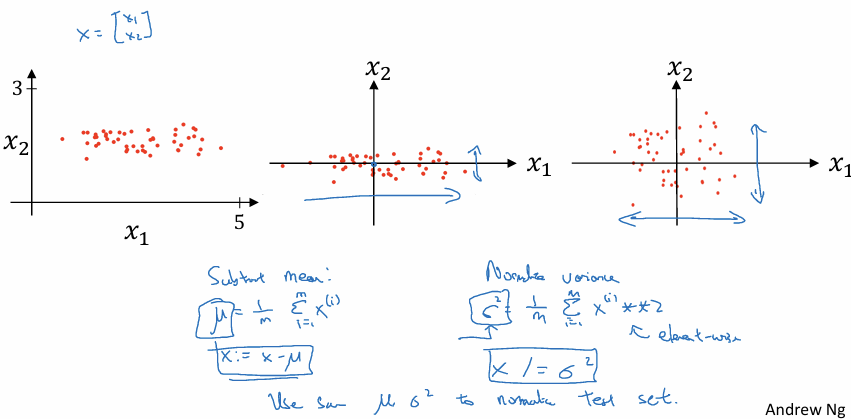 입력 데이터의 Feature $x$가 2차원($x_1, x_2$)이라고 할때
입력 데이터의 Feature $x$가 2차원($x_1, x_2$)이라고 할때
1단계: 평균 빼기 (Zero-centering):
데이터의 중심을 0으로 이동시킨다.
훈련 세트 전체의 평균 벡터 $\mu$를 구한 뒤 모든 훈련 샘플 $x$에서 $\mu$를 뺀다 ($x = x - \mu$).
2단계: 분산 정규화 (Normalizing Variance):
특성 간의 퍼짐 정도(스케일)를 맞춘다.
각 특성의 분산 벡터 $\sigma^2$를 구한 뒤 데이터를 이 값으로 나누어 준다. 이 과정을 거치면 $x_1$과 $x_2$의 분산이 모두 1과 같이 비슷한 크기를 갖게 된다.
2. 테스트 세트 정규화 시 주의사항
동일한 기준 적용:
훈련 데이터를 정규화할 때 계산했던 평균($\mu$)과 분산($\sigma^2$) 값을 그대로 사용하여 테스트 세트를 변환해야 한다.
테스트 세트나 개발 세트에서 별도로 평균과 분산을 다시 계산하면 안 된다. 훈련 데이터와 테스트 데이터가 정확히 똑같은 기준(변환 방식)으로 처리돼야 한다.
3. 정규화를 해야 하는 이유: 비용 함수(J)의 모양
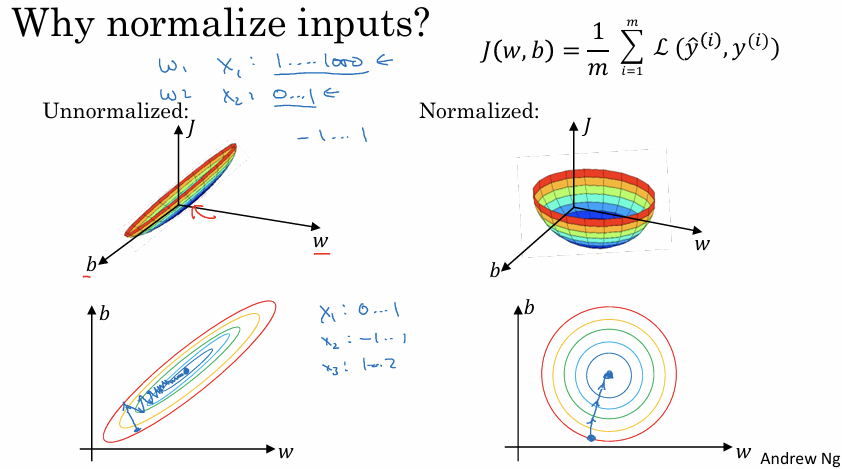
입력 특성들의 스케일(범위)이 서로 다를 때와 같을 때 비용 함수 $J$의 모양
정규화하지 않은 경우 (특성 스케일 차이가 클 때):
$x_1$은 1~1000, $x_2$는 0~1의 범위를 가진다면 비용 함수는 한쪽으로 길게 늘어진 ‘가늘고 긴 활 모양(elongated bowl)’ 이 된다.
경사 하강법을 실행하면 최솟값을 찾아가는 과정에서 지그재그로 진동하며 앞뒤로 왔다 갔다 하게 된다. 이 때문에 매우 작은 Learning rate을 써야 한다. -> 학습 속도가 매우 느려진다.
정규화한 경우 (특성 스케일이 비슷할 때):
모든 특성이 -1에서 1 사이 등 비슷한 범위를 가지면 비용 함수는 대칭적인 ‘둥근 그릇 모양(spherical bowl)’이 된다.
어디서 시작하든 최솟값으로 곧바로 향할 수 있어 더 큰 학습률을 사용하여 빠르게 학습(최적화)할 수 있다.
4. 언제 정규화를 적용해야 하는가?
스케일 차이가 클 때:
입력 특성 간의 범위 차이가 크다면 정규화는 필수적.
스케일이 비슷할 때:
특성들의 범위가 비슷하다면 정규화가 굳이 필요하지는 않다.
권장 사항:
하지만 정규화를 해서 해가 되는 경우는 없으므로 스케일 차이가 불분명하더라도 일단 정규화를 기본적으로 적용하는 것을 권장한다. 이는 학습 알고리즘의 실행 속도를 보장하는 안전한 방법이다.
입력 정규화는 비용 함수를 최적화하기 쉬운 둥근 형태로 만들어주어 경사 하강법이 더 큰 보폭으로 빠르게 수렴할 수 있게 돕는다.
Vanishing/Exploding Gradients (C2W1L10)
Deep Neural Networks를 훈련할 때 발생하는 문제인 Vanishing Gradients과 Exploding Gradients의 개념과 원인을 수학적 직관을 통해 설명.
1. 깊은 신경망의 학습 어려움
문제:
신경망의 층(Layer)이 매우 깊어질 때, 역전파 과정에서 미분값(기울기, gradient)이 기하급수적으로 작아지거나(소실) 커지는(폭발) 현상이 발생한다.
-> 이로 인해 훈련 자체가 매우 어려워지거나 불가능해질 수 있다.
2. 문제 발생의 수학적 직관
왜 발생하는지 이해하기 위해 활성화 함수가 선형($g(z)=z$)이고 편향($b$)이 0인 단순한 심층 신경망을 가정하여 설명한다.
연쇄적 곱셈:
이 가정하에서 출력값 $\hat{y}$는 입력 $x$에 각 층의 가중치 행렬 $W$를 차례대로 곱한 형태($W^{[L]} \times W^{[L-1]} \times \dots \times W^{} \times x$)가 된다.
가중치 행렬의 영향:
만약 각 층의 가중치 행렬 $W$가 Identity Matrix보다 조금이라도 크거나 작다면 층이 깊어질수록 그 차이가 지수 함수적으로 커진다.
3. 폭발과 소실
경사 폭발 (Exploding Gradients):
가중치 행렬의 값이 단위 행렬보다 큰 경우
대각 원소가 1.5인 행렬
층의 깊이가 $L$일 때, 값은 $1.5^{L-1}$과 같이 층의 수에 따라 기하급수적으로 증가하여 값이 폭발한다.
경사 소실 (Vanishing Gradients):
가중치 행렬의 값이 단위 행렬보다 작은 경우
대각 원소가 0.5인 행렬
값은 $0.5^{L}$과 같이 층의 수에 따라 기하급수적으로 감소하여 0에 수렴하게 된다.
4. 훈련에 미치는 영향
현실적인 깊이:
현대의 신경망은 150층 혹은 마이크로소프트의 사례처럼 800층이 넘는 경우도 있다.
학습 속도 저하:
경사가 소실되어 매우 작아지면 경사 하강법이 업데이트하는 step size가 극도로 작아진다. 이로 인해 학습 속도가 너무 느려져서 훈련에 엄청난 시간이 걸리게 됩니다. 반대로 폭발하면 숫자가 너무 커져서 계산이 불가능해진다.
깊은 신경망에서는 층을 거듭할수록 가중치가 곱해지며 값이 기하급수적으로 변하므로 가중치를 적절히 제어하지 않으면 학습이 멈추거나 발산하게 된다.
Weight Initialization in a Deep Network (C2W1L11)
이전 영상에서 다루었던 Vanishing gradients과 Exploding gradients 문제를 완화하여 심층 신경망을 효율적으로 학습시키기 위한 Weight Initialization 방법을 다룬다.
1. 단일 뉴런의 초기화 직관
아주 깊은 신경망이 겪는 경사 소실과 폭발 문제를 완전히 해결할 수는 없지만 초기 가중치를 신중하게 선택하면 문제를 완화할 수 있다.
단일 뉴런 예시:
하나의 뉴런에 들어가는 입력 특성($n$)이 많을수록($x_1, \dots, x_n$), $z = w_1x_1 + \dots + w_nx_n$ 값이 너무 커지거나 작아지지 않도록 가중치 $w_i$의 값은 작아져야 한다.
분산 설정:
따라서 합리적인 방법은 가중치 $w_i$의 분산을 입력 특성의 개수 $n$에 반비례하도록($1/n$) 설정한다.
2. 활성화 함수에 따른 초기화 공식
가중치 행렬을 초기화할 때 np.random.randn(...) (가우시안 분포) 뒤에 곱해주는 스케일링 계수(표준편차)가 활성화 함수에 따라 달라진다.
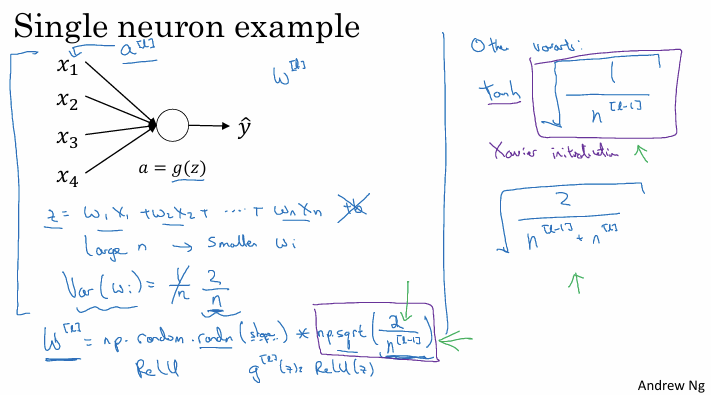
ReLU 함수 (He 초기화):
ReLU 활성화 함수를 사용할 때는 분산을 $2/n$로 설정하는 것이 훨씬 잘 작동한다.
가우시안 랜덤 변수에 $\sqrt{\frac{2}{n^{[l-1]}}}$ 을 곱한다. 여기서 $n^{[l-1]}$은 해당 층으로 들어오는 입력(이전 층의 유닛) 개수이다.
Tanh 함수 (Xavier/Glorot 초기화):
세이비어(Xavier) 초기화: Tanh 활성화 함수를 사용할 때는 분산을 $1/n$ 로 설정하는 것이 좋다.
가우시안 랜덤 변수에 $\sqrt{\frac{1}{n^{[l-1]}}}$ 을 곱한다.
기타 변형:
$\sqrt{\frac{2}{n^{[l-1]} + n^{[l]}}}$ 공식을 사용하는 경우도 있는데 이는 이론적인 근거가 있지만 ReLU를 쓸 때는 일반적으로 $2/n$ 공식을 선호한다.
3. 초기화의 효과와 하이퍼파라미터 튜닝
목표:
이러한 초기화는 각 층의 활성값들이 비슷한 크기(평균 0, 표준편차 1 등)를 유지하게 하여, 가중치가 훈련 초기에 너무 빨리 폭발하거나 0으로 소실되는 것을 방지한다.
하이퍼파라미터 여부:
이 초기화 공식의 곱해지는 수(상수) 자체를 하이퍼파라미터로 보고 튜닝할 수도 있다. 가끔 튜닝이 도움이 되기도 하지만 Learning rate 같은 다른 하이퍼파라미터에 비해 중요도는 낮다.
딥러닝 모델 특히 ReLU를 사용하는 심층 신경망에서는 가중치 초기화 시 분산을 $2/n$로 설정하는 것이 학습 속도를 높이고 경사 문제를 방지하는 데 효과적인 기본 설정이다.
Numerical Approximations of Gradients (C2W1L12)
Backpropagation 구현이 올바른지 검증하기 위한 Gradient Checking의 기초 단계로 미분값(경사)을 수치적으로 정확하게 근사하는 방법
1. Gradient Checking의 필요성
역전파 알고리즘을 구현할 때 수식이나 세부 사항에 버그가 있어도 겉으로는 작동하는 것처럼 보일 수 있다. 따라서 구현이 100% 맞는지 확신하기 위해 경사 검사라는 테스트가 필요하다.
2. 수치적 근사 방법: Two-sided Difference

기존 방식의 한계:
특정 지점 $\theta$에서 오른쪽으로만 조금 이동한 $\theta + \epsilon$을 사용하여 기울기를 구하는 방식(단방향 차이)은 덜 정확하다.
양방향 접근:
더 정확한 기울기를 얻기 위해 $\theta$를 기준으로 오른쪽($\theta + \epsilon$)과 왼쪽($\theta - \epsilon$)을 모두 고려한다.
공식 도출:

함수 $f(\theta)$ 그래프에서 두 점 사이의 큰 초록색 삼각형을 그린다.
높이는 $f(\theta + \epsilon) - f(\theta - \epsilon)$이고 너비는 $2\epsilon$.
-> $\frac{f(\theta + \epsilon) - f(\theta - \epsilon)}{2\epsilon}$
3. 예시
$f(\theta) = \theta^3$, $\theta = 1$, $\epsilon = 0.01$이라고 가정한다. 실제 미분값($g(\theta)=3\theta^2$)은 3이다.
양방향 차이 계산:
공식을 적용하면 $\frac{(1.01)^3 - (0.99)^3}{2(0.01)}$이 되며 결과값은 3.0001이다. 실제 값 3과의 오차는 0.0001이다.
단방향 차이 비교:
한쪽 차이($\theta + \epsilon$)만 사용했을 때의 결과는 3.0301로 오차가 0.03이었다.
양방향 차이를 사용하는 방식이 단방향 방식보다 훨씬 더 정확하다.
4. 오차율의 수학적 의미 (심화)
오차 차수(Order of Error):
단방향 차이의 근사 오차는 $O(\epsilon)$.
양방향 차이의 근사 오차는 $O(\epsilon^2)$.
$\epsilon$은 0.01과 같이 1보다 매우 작은 수이므로 $\epsilon$보다 $\epsilon^2$(0.0001)이 훨씬 더 작다. 양방향 차이 방식이 수학적으로 훨씬 정밀한 근사법.
트레이드오프:
양방향 차이는 함수를 두 번 계산해야 하므로 단방향보다 계산 속도가 2배 느리지만 정확도가 훨씬 높기 때문에 경사 검사에서는 이 방식을 사용한다.
5. 결론 및 활용 예고
$\frac{f(\theta + \epsilon) - f(\theta - \epsilon)}{2\epsilon}$ 공식을 사용하면 함수 $g(\theta)$가 올바른 도함수인지 수치적으로 확인할 수 있다.
Gradient Checking (C2W1L13)
Backpropagation 구현 시 발생할 수 있는 미묘한 버그를 찾아내기 위한 Gradient Checking 기법의 원리와 구체적인 실행 단계
1. 경사 검사를 위한 준비: 파라미터의 벡터화
경사 검사는 역전파 구현의 버그를 찾아 시간을 절약해 준다.
파라미터 변환 ($\theta$):
신경망의 모든 층에 있는 가중치와 편향 매개변수($W^{}, b^{}, \dots, W^{[L]}, b^{[L]}$)를 전부 concatenate하여 하나의 거대한 벡터 $\theta$로 만든다. 비용 함수 $J$는 이 $\theta$를 입력받는 함수가 된다.
기울기 변환 ($d\theta$):
역전파를 통해 계산된 모든 미분값($dW^{}, db^{}, \dots$)도 동일한 순서로 연결하여 $\theta$와 같은 차원을 가진 거대한 벡터 $d\theta$ 로 만든다.
2. 수치적 근사 기울기 계산 (Grad Check 구현)
반복문 실행:
벡터 $\theta$의 모든 원소에 대해 반복문을 돌며 수치적인 기울기 근사값 $d\theta_{\text{approx}}$를 계산한다.
Two-sided difference 사용:
각 원소 $\theta_i$에 대해 아주 작은 값 $\epsilon$을 더했을 때와 뺐을 때의 비용 함수 차이를 이용하여 미분값을 근사한다.
이 값은 해당 지점에서의 실제 편미분값($d\theta[i]$)과 매우 가까워야 한다.
3. 검증: 두 벡터의 차이 비교
비교 수식:
역전파로 구한 기울기 벡터 $d\theta$와 수치적으로 구한 근사 벡터 $d\theta_{\text{approx}}$가 얼마나 유사한지 확인하기 위해 유클리드 거리(L2 노름) 를 계산하고 정규화한다.
분모에 각 벡터의 노름 합을 두는 이유: 벡터의 크기가 너무 크거나 작을 때 비율을 맞춰주기 위함이다.
4. 결과 해석 및 디버깅 기준
일반적으로 $\epsilon = 10^{-7}$을 사용할 때 결과 값에 따른 판단 기준
$10^{-7}$ 이하:
근사가 매우 잘 되었음.
$10^{-5}$ 수준:
괜찮은 편이지만 혹시 차이가 큰 특정 성분이 있는지 확인해 볼 필요가 있다.
$10^{-3}$ 이상:
버그가 있을 가능성이 매우 크다.
이 경우 $\theta$의 원소들을 하나씩 추적하여 $d\theta_{\text{approx}}[i]$와 $d\theta[i]$의 차이가 유독 큰 인덱스 $i$를 찾는다.
해당 인덱스가 어떤 층의 가중치나 편향에 해당하는지 파악하면 역전파 코드의 어느 부분(미분 계산)이 잘못되었는지 원인을 찾을 수 있습니다.
이러한 경사 검사 과정을 통과하여 결과 값이 매우 작게 나온다면 역전파 구현에 대해 자신감을 가져도 좋다.
Gradient Checking Implementation Notes (C2W1L14)
Gradient Checking를 실제 신경망에 구현할 때 주의해야 할 5가지 실질적인 팁
1. Training 중에는 사용 금지
속도 문제:
경사 검사는 모든 파라미터에 대해 근사치를 계산해야 하므로 매우 느리다.
용도:
오직 Debugging 목적으로만 사용해야 한다. 역전파 코드가 올바른지 검증할 때만 켜고 검증이 끝나면 경사 검사를 끄고 실제 훈련을 진행해야 한다.
2. 알고리즘 실패 시 컴포넌트별 확인
버그 위치 추적:
만약 경사 검사 결과 두 값의 차이가 크게 난다면 단순히 실패했다고 넘기지 말고 어떤 인덱스 $i$에서 차이가 발생하는지 들여다봐야 한다.
매개변수 구분:
$d\theta_{approx}[i]$와 $d\theta[i]$의 차이가 큰 항목이 편향($db$)인지 가중치($dw$)인지 확인한다. $db$ 쪽에서만 차이가 크다면 편향을 계산하는 코드에 버그가 있을 확률이 높다.
3. Regularization 항 포함 주의
비용 함수 정의:
만약 정규화를 사용하고 있다면, 비용 함수 $J(\theta)$는 손실 함수 합계뿐만 아니라 정규화 항(가중치 제곱 합 등)을 포함하고 있다는 점을 기억.
경사 계산:
따라서 경사 검사를 할 때도 정규화 항에 대한 미분 값이 $d\theta$에 올바르게 포함되어 있는지 확인해야 한다.
4. Dropout과는 함께 사용 불가
이유:
드롭아웃은 매 반복마다 무작위로 노드를 삭제하므로 비용 함수 $J$의 형태가 매번 달라집니다. 이 때문에 경사 검사를 수행하기 위한 명확한 기준 비용 함수를 정의하기 어렵다.
해결책:
경사 검사를 할 때는 keep_prob을 1.0으로 설정하여 드롭아웃을 끈다. 알고리즘이 올바른지 확인한 후 다시 드롭아웃을 켜서 훈련을 진행하는 방식으로 한다.
5. 초기화 단계 및 훈련 중반 검사
특수 상황:
가중치 $w, b$가 0에 가까운 초기화 단계에서는 역전파가 맞게 작동하다가 훈련이 진행되어 값이 커지면 오차가 커지는 경우가 드물게 발생할 수 있다.
팁:
안전을 위해 무작위 초기화 직후에 경사 검사를 한 번 실행하고 네트워크를 일정 시간 훈련시켜 가중치가 0에서 멀어진 뒤에 다시 한 번 경사 검사를 실행해보는 것도 좋은 방법이다.
Week 1에서는 훈련/개발 세트 설정, 편향/분산 진단, 정규화(L2, 드롭아웃), 최적화 설정, 그리고 경사 검사까지 신경망 성능 향상을 위한 실전적인 기법들을 학습했다.