[DeepLearning.AI] Course2.W3 Improving Deep Neural Networks
Tuning Process (C2W3L01)
1. 하이퍼파라미터의 중요도 분류
딥러닝 모델 학습에는 수많은 하이퍼파라미터가 관여한다.

가장 중요한 파라미터:
학습률($\alpha$)이 튜닝해야 할 가장 중요한 요소이다.
그 다음으로 중요한 그룹 (주황색 박스):
모멘텀 계수($\beta$, 보통 0.9), 미니 배치 크기, Hidden units의 개수
세 번째로 중요한 그룹 (보라색 박스):
Layer의 개수, Learning rate decay
튜닝하지 않는 파라미터:
Adam 최적화 알고리즘의 $\beta_1, \beta_2, \epsilon$ 값은 보통 기본값($0.9, 0.999, 10^{-8}$)을 그대로 사용한다.
2. 탐색 전략: Grid vs Random
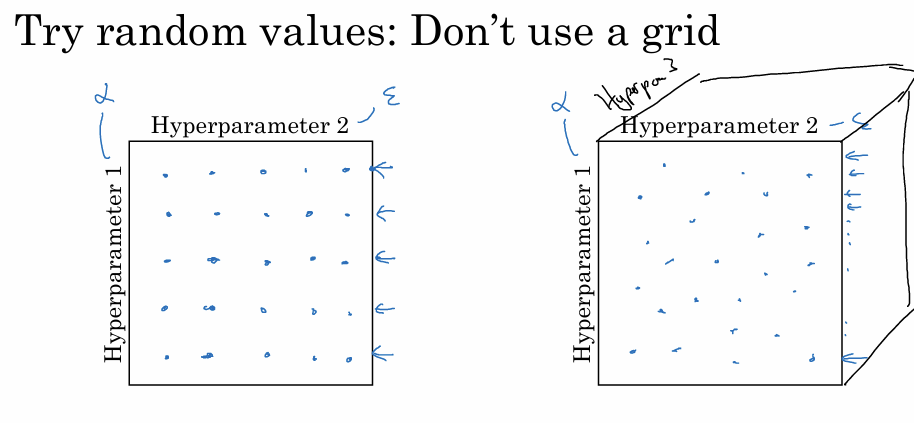
과거 머신러닝 초기에는 하이퍼파라미터가 적을 때 일정한 간격으로 값을 탐색하는 Grid Search 을 주로 사용했다. 하지만 딥러닝에서는 Random Search가 훨씬 권장된다.
무작위 탐색을 추천하는 이유:
어떤 하이퍼파라미터가 문제 해결에 결정적인지 미리 알 수 없기 때문이다.
중요한 파라미터인 학습률($\alpha$)과 덜 중요한 파라미터인 $\epsilon$이 있다고 가정한다. 5x5 격자점 탐색을 하면 $\alpha$에 대해 단 5가지 값만 시도하게 된다(나머지 탐색은 결과에 영향이 적은 $\epsilon$만 바꾸는 꼴이 됨). 반면 무작위로 25개의 점을 찍으면 서로 다른 25가지의 $\alpha$ 값을 테스트할 수 있어 최적의 값을 찾을 확률이 높아진다. 이는 파라미터의 차원이 늘어나도(3개 이상) 동일하게 적용된다.
3. 정밀화 접근 (Coarse to Fine)

무작위 탐색을 통해 좋은 성능을 보이는 대략적인 영역을 발견했다면 그 영역을 중심으로 탐색 범위를 좁히는 정밀화 접근을 사용할 수 있다.
전체 영역에서 무작위 탐색을 수행한 후 성능이 좋은 점들이 모여 있는 특정 영역(더 작은 사각형)으로 범위를 축소한다. 그 안에서 다시 조밀하게 점들을 선택하여 최적의 파라미터를 찾는다.
- 격자점 탐색 대신 무작위 탐색(Random Search)을 사용하여 중요한 파라미터의 다양한 값을 확인.
- 필요하다면 좋은 성능을 보인 구역을 집중적으로 탐색하는 정밀화 접근(Coarse to Fine) 방식을 활용.
Using an Appropriate Scale (C2W3L02)
지난 강의에서 Random Search가 좋다고 배웠지만 단순히 모든 범위에서 Uniformly 값을 뽑는 것이 항상 정답은 아니다. 하이퍼파라미터의 특성에 맞는 적절한 Scale를 설정하는 것이 중요한다.
1. Linear Scale가 적합한 경우
일부 하이퍼파라미터는 주어진 범위 내에서 균일하게 무작위로 뽑아도 문제가 없다.
은닉 유닛의 수($n^{[l]}$):
50개에서 100개 사이를 정할 때 이 수직선 상에서 무작위로 점을 찍는 것은 합리적이다.
층의 개수($L$):
2층에서 4층 사이를 정할 때도 균일하게 뽑는 것이 괜찮다.
2. Log Scale가 필요한 경우: 학습률($\alpha$)
학습률 $\alpha$를 0.0001에서 1 사이에서 찾는다고 가정해보자.
문제점:
선형 척도로 무작위 추출을 하면 전체 자원의 90%가 0.1과 1 사이(큰 값 구간)에 집중되고 정작 중요한 0.0001과 0.1 사이(작은 값 구간)는 단 10%만 탐색하게 된다. 이는 비효율적이다.
해결책:
로그 척도를 사용하여 $10^{-4}$부터 $10^0$까지 지수를 기준으로 탐색해야 한다.
구현 방법:
최소값의 지수($a=\log_{10}0.0001 = -4$)와 최대값의 지수($b=\log_{10}1 = 0$) 사이에서 무작위 값 $r$을 뽑은 뒤 $\alpha = 10^r$로 설정한다. 작은 값 구간과 큰 값 구간을 공평하게 탐색할 수 있다.
3. 민감한 파라미터 튜닝: $\beta$ (모멘텀 등)
지수가중평균에 사용되는 $\beta$를 0.9에서 0.999 사이에서 탐색하는 경우이다.
문제점:
$\beta$는 1에 가까워질수록 결과에 주는 영향이 급격히 커진다. $\beta$가 0.9에서 0.9005로 변하는 것은 큰 차이가 없지만 0.999에서 0.9995로 변하는 것은 평균을 내는 데이터 구간이 1000개에서 2000개로 2배나 늘어나는 큰 변화를 만든다.
해결책:
$\beta$ 대신 $1-\beta$ 값을 탐색한다. $0.1$($10^{-1}$)에서 $0.001$($10^{-3}$) 사이를 로그 척도로 탐색하는 것이다.
효과:
이 방법을 쓰면 $\beta$가 1에 아주 가까운 구간(0.99…구간)을 더 조밀하게 탐색할 수 있어 효율적이다.
4. 결론
하이퍼파라미터 탐색 시 적절한 척도를 사용하면 더 효율적으로 최적값을 찾을 수 있다. 척도를 잘못 설정했더라도 지난 강의의 정밀화 접근(Coarse to Fine)을 반복하면 결국 좋은 결과를 얻을 수는 있겠지만 처음부터 올바른 척도를 쓰는 것이 탐색 속도를 높여준다.
ai:
로그 척도 탐색은 카메라의 Zoom 기능과 비슷한다. 넓은 풍경(0.1~1)과 아주 작은 개미(0.0001~0.1)를 동시에 관찰해야 한다면 같은 배율로만 찍어서는 개미가 보이지 않습니다. 로그 척도를 사용한다는 것은 작은 개미가 있는 영역은 ‘확대’해서 자세히 보고 넓은 풍경은 ‘축소’해서 전체적으로 훑어보며 두 영역에 동등한 주의를 기울이는 것과 같다.
Hyperparameter Tuning in Practice (C2W3L03)
1. 하이퍼파라미터 직관의 적용과 주기적 재평가
직관의 전이:
딥러닝의 구조나 아이디어(예: ResNet)는 컴퓨터 비전에서 음성 인식이나 NLP 등 다른 분야로 잘 적용되는 경향이 있다. 하지만 특정 문제에서 찾은 하이퍼파라미터 설정값 자체가 다른 분야에도 그대로 통용될 것이라고 기대하기는 어렵다.
하이퍼파라미터의 유효기간:
데이터의 변화나 서버 하드웨어 업그레이드 등의 이유로 과거에 최적이었던 하이퍼파라미터가 시간이 지나면 더 이상 좋은 결과를 내지 못할 수 있다. 따라서 몇 달에 한 번씩 하이퍼파라미터를 재평가하는 것이 좋다
2. 하이퍼파라미터 탐색의 두 가지 전략
강의에서는 컴퓨팅 자원의 상황에 따라 크게 두 가지 접근법을 제시한다.
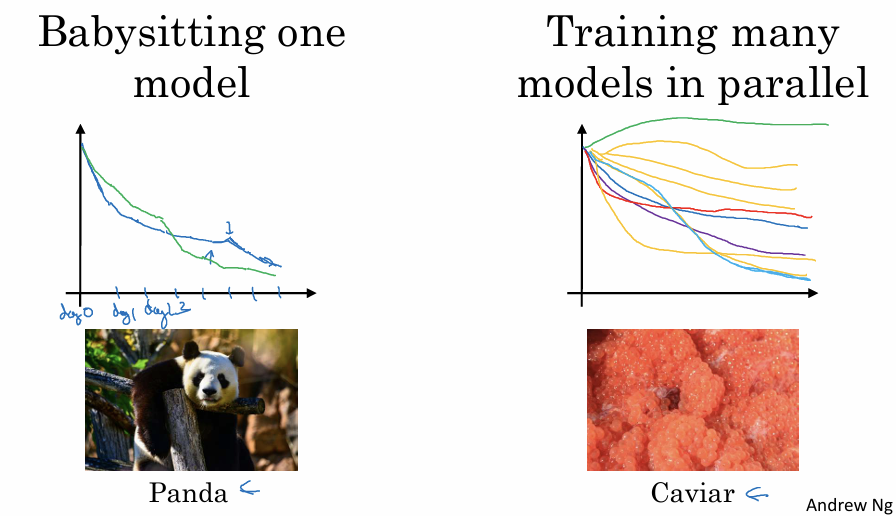
전략 1: Babysitting - “판다 접근법” 상황:
CPU나 GPU 등 컴퓨터 자원이 부족하여 한 번에 하나의 모델(또는 아주 적은 수)만 학습시킬 수 있을 때 사용한다. 방법:
학습 과정을 매일 지켜보며 Learning Curve의 상태에 따라 Learning rate이나 모멘텀 등을 조금씩 수정해 나가는 방식이다.
비유:
한 번에 한 마리의 새끼만 낳아 정성껏 키우는 판다의 육아 방식과 유사하다. 온라인 광고나 대규모 컴퓨터 비전 모델처럼 데이터가 방대하여 모델 학습에 많은 자원이 드는 경우 주로 이 방식을 사용한다.
전략 2: 여러 모델 동시 학습 - “캐비어 접근법” 상황:
충분한 컴퓨터 자원을 보유하고 있어 여러 모델을 동시에 돌릴 수 있을 때 사용한다.
방법:
서로 다른 하이퍼파라미터 설정을 가진 여러 모델을 동시에 학습시킨다. 사람의 개입 없이 각 모델이 그려내는 학습 곡선을 지켜보다가, 결과가 가장 좋은 모델을 선택한다.
비유:
번식기에 1억 개의 알을 낳고 그중 일부가 살아남기를 기대하는 물고기나 파충류의 번식 방식, 캐비어 전략과 유사한다.
3. 요약 및 결론
두 전략 중 어떤 것을 사용할지는 전적으로 가용한 컴퓨터 자원(CPU/GPU)의 양에 달려 있다.
Normalizing Activations in a Network (C2W3L04)
심층 신경망의 학습 성능을 획기적으로 개선하는 Batch Normalization의 개념과 구현 방법을 다룬다.
1. 배치 정규화의 배경과 이점
Sergey Ioffe와 Christian Szegedy가 개발한 배치 정규화 알고리즘.
이 알고리즘은 다음과 같은 강력한 이점을 제공한다. 하이퍼파라미터 탐색을 훨씬 쉽게 만들어준다. 신경망이 하이퍼파라미터 설정에 덜 민감하게 반응하게 하여 다양한 설정에서도 잘 작동하게 한다. Deep Neural Network도 쉽게 학습할 수 있도록 돕는다.
2. 입력 정규화의 확장: $z$ vs $a$
로지스틱 회귀에서 입력값($x$)을 정규화(평균 0, 분산 1)하면 비용 함수의 형태가 둥글게 되어 학습 속도가 빨라진다. 배치 정규화는 이 아이디어를 Hidden Layer으로 확장한 것이다.
적용 대상:
활성 함수를 거친 값($a$)보다 활성 함수를 통과하기 전의 값인 $z$를 정규화하는 것이 일반적이며 권장된다.
3. Normalization
신경망의 특정 층에서 은닉 유닛 값들($z^{(1)}, \dots, z^{(m)}$)이 주어졌을 때
- 평균($\mu$)과 분산($\sigma^2$)을 계산한다.
- 평균을 빼고 표준편차로 나누어 정규화된 값 $z_{\text{norm}}^{(i)}$을 구한다 (이때 분모가 0이 되는 것을 막기 위해 작은 값 $\epsilon$을 더한다).
해당 은닉 유닛들은 평균 0, 표준편차 1의 분포를 갖게 된다.
4. Scale과 Shift: $\gamma$와 $\beta$의 도입
모든 은닉 유닛의 평균이 0이고 분산이 1인 것이 항상 좋은 것은 아니다.
시그모이드 함수를 사용할 경우 입력값이 0 근처에만 몰려있으면 비선형성을 제대로 활용하지 못하고 선형 영역에서만 작동할 수 있다
이를 해결하기 위해 학습 가능한 파라미터 $\gamma$와 $\beta$ 를 도입한다.
$\tilde{z}^{(i)} = \gamma \cdot z_{\text{norm}}^{(i)} + \beta$.
역할:
$\gamma$와 $\beta$는 경사하강법 등을 통해 학습되는 변수이다. 이 값들을 통해 모델은 은닉 유닛의 평균과 분산을 원하는 대로 조절할 수 있다.
유연성:
만약 $\gamma = \sqrt{\sigma^2 + \epsilon}$, $\beta = \mu$로 학습된다면 정규화 과정을 취소하고 원래의 $z$ 값으로 되돌릴 수도 있다. 모델이 정규화가 필요한지 아닌지를 스스로 결정할 수 있게 한다.
5. 결론 및 요약
결과적으로 배치 정규화는 입력층뿐만 아니라 신경망 깊숙한 곳에 있는 은닉층의 값($z$)들까지 정규화하는 기법이다. 핵심은 단순히 평균을 0으로 만드는 것이 아니라 $\gamma$와 $\beta$를 이용해 은닉 유닛이 학습에 가장 적합한 평균과 분산을 갖도록 표준화하는 것이다.
ai:
배치 정규화는 오케스트라의 지휘자와 음향 감독의 역할에 비유할 수 있다.
정규화 ($z_{\text{norm}}$):
각 악기(은닉 유닛)의 소리 크기를 일단 통일시켜서 특정 악기만 너무 크거나 작게 들리지 않도록 균형을 잡는다 (평균 0, 분산 1).
$\gamma$와 $\beta$:
하지만 모든 악기 소리가 똑같은 크기면 음악이 지루해진다. 음향 감독($\gamma, \beta$)은 곡의 분위기에 맞게 바이올린은 좀 더 크게($\gamma$), 첼로는 좀 더 부드럽게($\beta$) 미세 조정한다.
즉 일단 균형을 맞춘 뒤(Normalization), 가장 듣기 좋은 상태로 다시 조정(Scale & Shift)하는 과정이라고 볼 수 있다.
Fitting Batch Norm Into Neural Networks (C2W3L05)
1. 신경망 내 Batch Norm의 위치
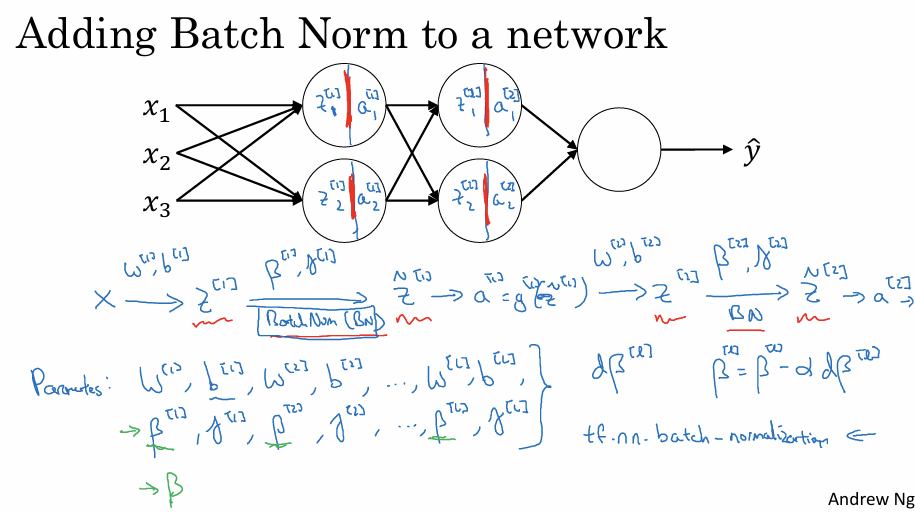
기존 신경망은 $z$를 계산한 후 바로 활성화 함수를 적용하여 $a$를 구하지만 Batch Norm를 적용할 때는 $z$와 $a$ 계산 사이에 정규화 과정이 추가된다
선형 결합 값 $z^{[l]}$을 계산한다.
$z^{[l]}$에 배치 정규화를 적용하여 정규화된 값 $\tilde{z}^{[l]}$를 얻는다. 이때 학습 가능한 파라미터 $\beta^{[l]}$와 $\gamma^{[l]}$가 사용된다.
활성화 함수에 $\tilde{z}^{[l]}$를 입력하여 최종 활성화 값 $a^{[l]}$를 계산한다.
이 과정은 첫 번째 층부터 마지막 층까지 반복적으로 적용되며 비정규화된 $z$ 대신 평균과 분산으로 정규화된 $\tilde{z}$를 다음 단계로 넘기는 방식이다.
2. 새로운 파라미터 $\beta$와 $\gamma$의 역할 및 주의점
각 층에는 가중치 $w$, 편향 $b$ 외에도 배치 정규화를 위한 새로운 파라미터 $\beta$와 $\gamma$가 추가된다.
주의할 점:
여기서 사용되는 $\beta$는 모멘텀(Momentum)이나 Adam 알고리즘 등에서 사용되는 하이퍼파라미터 $\beta$와는 완전히 다른 변수이다.
$\beta$와 $\gamma$는 $w$와 마찬가지로 경사 하강법, Adam, RMSprop 등의 최적화 알고리즘을 통해 학습되고 업데이트된다.
3. Mini-batch 단위의 적용
실제 학습 시 배치 정규화는 전체 데이터가 아닌 미니 배치 단위로 적용된다.
첫 번째 미니 배치 $X^{{1}}$에 대해 $z^{}$을 계산하고 해당 미니 배치 내에서의 평균과 분산을 구하여 정규화를 진행한다. 이후 $\beta$와 $\gamma$를 이용해 값을 조정하여 $\tilde{z}^{}$을 얻고 활성화 함수를 통과시킨다. 두 번째 미니 배치 $X^{{2}}$에 대해서도 동일하게 해당 배치의 데이터만을 이용해 평균과 분산을 계산하고 정규화를 수행한다.
4. Bias 파라미터 $b$의 제거
배치 정규화를 사용할 때 중요한 특징은 편향 파라미터 $b^{[l]}$이 불필요해진다는 점이다.
이유:
배치 정규화 과정에서 $z$의 평균을 빼주는 단계가 있는데 이때 상수인 $b$는 평균 계산에 포함되어 뺄셈 과정에서 상쇄되어 사라진다. 따라서 배치 정규화를 적용하는 층에서는 $b$를 0으로 두거나 아예 없앨 수 있으며, 대신 배치 정규화 파라미터인 $\beta^{[l]}$가 데이터의 편향(shift)을 담당하는 역할을 하게 된다
참고로 $\beta^{[l]}$와 $\gamma^{[l]}$의 차원은 해당 층의 은닉 유닛 수($n^{[l]}$)와 동일한 $(n^{[l]}, 1)$이다.
5. Gradient Descent의 구현
순방향 전파(Forward prop) 시 각 층에서 $z$를 $\tilde{z}$로 변환한다.
역방향 전파(Backprop)를 통해 $dw$뿐만 아니라 $d\beta$, $d\gamma$를 계산한다 ($db$는 제외).
최적화 알고리즘(경사 하강법, Adam 등)을 사용하여 $w, \beta, \gamma$를 업데이트한다.
딥러닝 프레임워크를 사용하면 복잡한 수식 구현 없이 한 줄의 코드로 이 모든 과정을 처리할 수 있다.
ai:
요리를 할 때(신경망 학습), 각 단계마다 재료(데이터)의 간을 맞추는 것(정규화)과 같다. 배치 정규화가 없다면 앞 단계 요리의 간이 들쑥날쑥할 때 뒤 단계에서 맛을 잡기가 매우 어렵습니다. 하지만 배치 정규화는 요리의 중간 단계마다 재료의 맛(평균과 분산)을 표준화한 뒤, 셰프가 원하는 만큼 소금($\beta$)과 설탕($\gamma$)을 다시 쳐서 최적의 상태로 다음 단계에 넘겨주는 과정이라고 볼 수 있다. 이때 기존에 무작정 넣던 기본 조미료($b$, 편향)는 재료를 씻어내는 과정(평균 차감)에서 어차피 씻겨나가므로 굳이 넣을 필요가 없게 되는 것이다.
Why Does Batch Norm Work? (C2W3L06)
1. 입력 정규화와 유사한 효과
배치 정규화가 작동하는 첫 번째 이유는 Input features을 정규화하는 원리와 같다. 입력 데이터의 평균을 0, 분산을 1로 만들면 학습 속도가 빨라지는 것처럼 배치 정규화는 Hidden units의 값들도 비슷한 범위를 갖도록 정규화하여 은닉층의 학습 속도를 높인다.
2. 공변량 변화(Covariate Shift) 문제
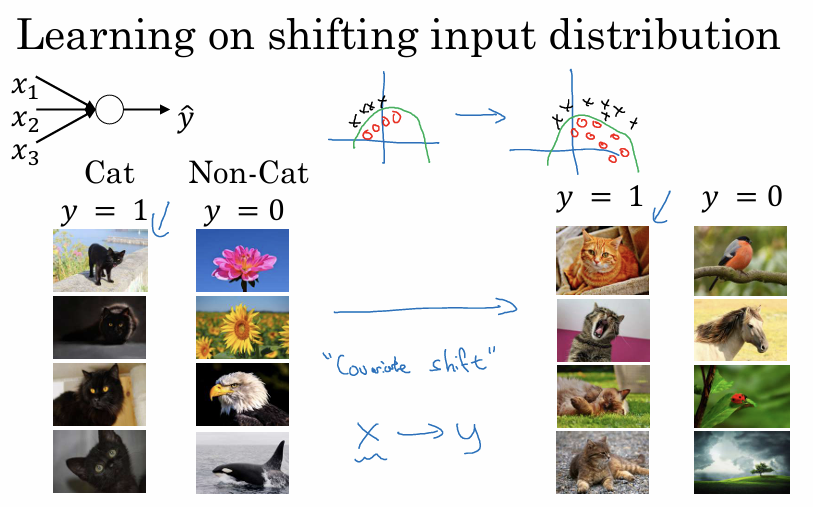
입력 데이터(X)의 분포가 바뀌면, X와 Y의 관계가 그대로여도 학습 알고리즘을 다시 학습시켜야 하는 현상.
검은 고양이 이미지만으로 학습한 모델에 색깔이 있는 고양이 이미지를 입력하면 고양이라는 정답(Y)은 같아도 데이터 분포(X)가 달라져 성능이 떨어진다.
3. 심층 신경망 내부의 안정성 확보
신경망 내부에서도 공변량 변화 문제가 발생한다.
내부의 변화:
학습이 진행되면서 앞쪽 층의 파라미터($w, b$)가 계속 업데이트된다. 이로 인해 뒤쪽 층이 받아들이는 입력값($a^{}$)의 분포가 끊임없이 바뀐다.
배치 정규화의 역할:
배치 정규화는 은닉층 값들의 평균과 분산을 일정하게 유지하도록 제한한다. 값 자체는 변하더라도 그 분포의 평균과 분산은 고정되거나 안정적으로 유지된다.
결과:
뒤쪽 층은 앞쪽 층의 변화에 덜 민감해지며 각 층이 서로에게 덜 의존하고 독립적으로 학습할 수 있게 되어 전체적인 학습 속도가 빨라진다.
4. 부수적인 Regularization 효과
배치 정규화는 의도치 않게 약간의 Regularization 효과를 가진다
노이즈의 추가:
미니 배치 단위로 평균과 분산을 계산하기 때문에 전체 데이터셋의 통계치와 비교했을 때 약간의 Noise가 섞이게 된다. 이는 평균을 뺄 때 ‘덧셈 잡음’ 표준편차로 나눌 때 ‘곱셈 잡음’을 추가하는 것과 같다.
일반화:
Dropout이 은닉 유닛에 잡음을 주어 하나의 유닛에 의존하지 않게 만드는 것처럼 배치 정규화도 비슷한 원리로 과대적합을 막는 일반화 효과를 낸다.
주의점:
미니 배치 크기가 커지면 잡음이 줄어들어 규제 효과도 약해집니다. 따라서 규제만을 목적으로 배치 정규화를 사용해서는 안 되며, 이는 어디까지나 부수적인 효과로 이해해야 한다.
ai:
배치 정규화가 없는 신경망은 마치 “계속 흔들리는 배 위에서 블록 쌓기를 하는 것”과 같습니다. 배(앞쪽 층)가 흔들릴 때마다 내가 서 있는 바닥(뒤쪽 층의 입력)의 기울기가 변하므로 균형을 잡는 데 에너지를 다 써버려 블록을 높이 쌓기(학습하기) 어렵다.
반면 배치 정규화를 적용한 신경망은 “흔들림 방지 장치가 있는 평평한 테이블 위에서 블록을 쌓는 것” 이다. 배가 흔들려도 테이블(은닉층의 분포)은 수평을 유지하므로 각 층은 균형 잡는 걱정 없이 블록을 쌓는 본연의 임무(학습)에만 집중하여 훨씬 빠르게 작업을 마칠 수 있다.
Batch Norm At Test Time (C2W3L07)
1. 테스트 시의 문제점: 단일 샘플 처리의 한계
Training 과정:
Batch Norm는 미니 배치(예: 64, 128개 데이터) 단위로 평균($\mu$)과 분산($\sigma^2$)을 계산하여 데이터를 정규화한다.
Test 과정:
실제 운영 환경에서는 데이터를 미니 배치로 묶어서 처리하기보다 한 번에 하나의 샘플씩 처리해야 하는 경우가 많다.
문제:
샘플이 하나뿐일 때는 그 자체의 평균과 분산을 구하는 것이 불가능하거나 의미가 없으므로 학습 때와는 다른 방식으로 평균과 분산 값을 구해야 한다.
2. 해결책: 지수가중평균(Exponentially Weighted Averages) 활용
테스트 과정에서 사용할 평균과 분산의 추정치를 얻기 위해, 학습 과정에서 각 Layer의 미니 배치마다 계산되는 $\mu$와 $\sigma^2$ 값을 추적한다.
학습이 진행되는 동안 여러 미니 배치에 걸쳐 평균과 분산의 지수가중평균(이동 평균)을 계산하여 저장해둔다.
3. 테스트 과정에서의 적용
테스트 시에는 입력 데이터로부터 새로 평균과 분산을 계산하지 않는다. 대신 학습 중에 미리 구해둔 이동 평균값(저장된 $\mu$와 $\sigma^2$) 을 가져와서 데이터를 정규화($z_{norm}$ 계산)한다.
마지막으로 학습된 파라미터인 $\beta$와 $\gamma$를 사용하여 최종 출력값($\tilde{z}$)을 계산한다.
4. 결론 및 구현
이론적으로는 학습이 끝난 후 전체 훈련 데이터를 다시 돌려 정확한 평균과 분산을 구할 수도 있지만 실제로는 학습 중에 구한 이동 평균을 사용하는 것이 매우 효율적이고 결과도 안정적이다. 대부분의 딥러닝 프레임워크는 이 과정을 자동으로 처리해주기 때문에 사용자는 이를 통해 더 깊은 신경망을 빠르게 학습시키기만 하면 된다.
Softmax Regression (C2W3L08)
1. 다중 클래스 분류의 필요성
지금까지의 이진 분류와 달리 여러 선택지 중 하나를 골라야 하는 문제가 있다. 이미지를 보고 고양이, 개, 병아리, 혹은 그 외로 분류하는 경우이다. 이처럼 $C$개의 클래스를 인식할 때는 로지스틱 회귀를 일반화한 Softmax Regression을 사용한다.
2. 출력층의 구조
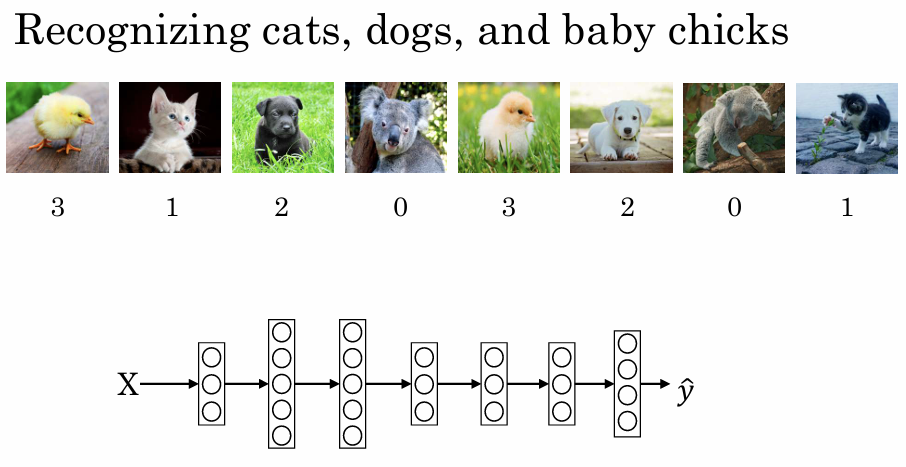
클래스가 4개($C=4$)라면 신경망의 출력층 유닛 개수도 4개가 된다.
출력값 $\hat{y}$은 $(4, 1)$ 차원의 벡터가 되며, 각 원소는 입력값 $X$가 주어졌을 때 해당 클래스일 확률을 나타냅니다. 따라서 $\hat{y}$의 모든 원소를 합하면 반드시 1이 되어야 한다.
3. 소프트맥스 활성화 함수 계산 과정
출력층의 선형 계산값인 $z^{[L]}$을 확률값 $a^{[L]}$로 변환하기 위해 두 단계를 거친다.
- 임시 변수 $t$ 계산:
$z^{[L]}$의 각 원소에 지수 함수($e$)를 취한다($t = e^{z^{[L]}}$). - Normalization:
모든 $t$ 값의 합으로 각 $t$ 성분을 나눈다. 이를 통해 모든 출력값의 합이 1이 되도록 만든다.
4. 구체적인 계산 예시
만약 $z^{[L]} = [5, 2, -1, 3]$이라는 벡터가 나왔다면:
각 원소에 $e$를 취하면 약 $[148.4, 7.4, 0.4, 20.1]$이 된다.
이들의 합(약 176.3)으로 각 값을 나누면 최종 출력 벡터는 $[0.842, 0.042, 0.002, 0.114]$가 된다.
이는 첫 번째 클래스일 확률이 약 84.2%라는 의미이다.
5. 소프트맥스 함수의 특징과 결정 경계
벡터 입출력:
시그모이드나 ReLU 같은 기존 활성화 함수가 실수를 받아 실수를 내놓는 것과 달리 소프트맥스는 벡터를 입력받아 정규화된 벡터를 출력한다는 점이 특이하다.
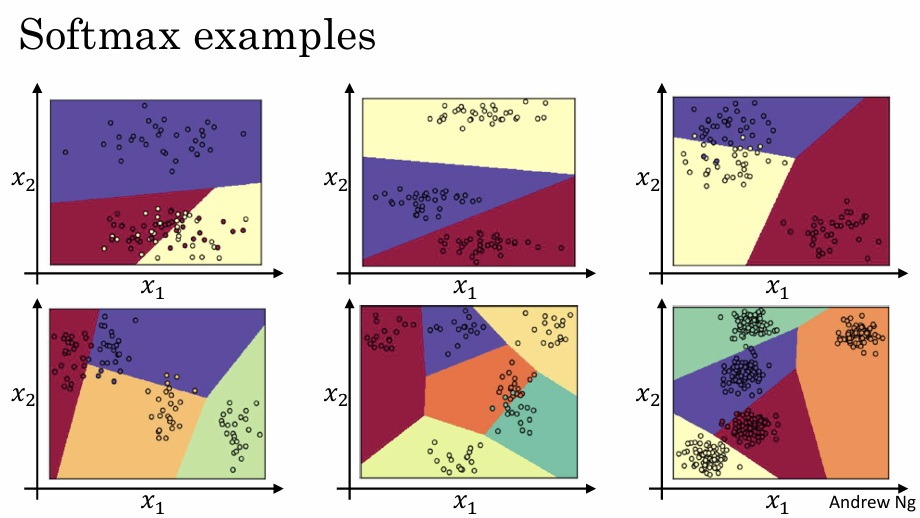
선형 결정 경계:
은닉층 없이 소프트맥스 층만 사용할 경우, 클래스 간의 경계는 선형으로 나타난다. 하지만 은닉층이 있는 깊은 신경망과 결합하면 더 복잡하고 비선형적인 경계를 학습하여 다양한 클래스를 분류할 수 있다.
Training Softmax Classifier (C2W3L09)
1. Softmax와 Hardmax의 차이
이전 영상에서 배운 소프트맥스 층의 계산 과정을 복습하며 시작한다. $z^{[L]}$ 벡터의 각 원소에 지수 함수($e$)를 취하고 정규화하여 확률값인 $a^{[L]}$을 얻는다.
Hardmax:
가장 큰 값을 가진 위치에만 1을 부여하고 나머지는 모두 0으로 만드는 Hard 방식이다.
Softmax:
하드맥스와 달리 값을 확률 분포로 부드럽게 대응시키므로 Soft맥스라고 불린다.
2. 로지스틱 회귀와의 관계
소프트맥스 회귀는 로지스틱 회귀의 일반화된 형태이다. 분류할 클래스의 수 $C$가 2라면 소프트맥스 회귀는 정확히 로지스틱 회귀와 동일하게 작동한다. 두 개의 출력값 중 하나의 확률만 알면 나머지도 알 수 있기 때문이다(합이 1이므로).
3. Loss Function의 이해
신경망 학습을 위해 단일 훈련 샘플에 대한 손실 함수를 정의한다.
$L(\hat{y}, y) = -\sum_{j=1}^{C} y_j \log(\hat{y}_j)$
정답 레이블 $y$는 원-핫 벡터이므로 실제 정답 클래스에 해당하는 항만 남고 나머지는 사라진다. 정답이 두 번째 클래스라면 손실 함수는 $-\log(\hat{y}_2)$ 가 된다.
목표:
경사하강법으로 이 손실 값을 최소화하는 것은 결국 정답 클래스에 해당하는 예측 확률($\hat{y}$)을 최대화하는 것과 같다. 이는 통계학의 Maximum Likelihood Estimation과 유사한 개념이다.
4. 구현을 위한 행렬 차원과 역전파
행렬 차원:
$m$개의 훈련 샘플을 묶어서 처리할 때 정답 행렬 $Y$와 예측 행렬 $\hat{Y}$의 차원은 $(C, m)$이 된다.
Backpropagation:
경사하강법 구현 시 핵심이 되는 도함수 $dz^{[L]}$(비용 함수를 $z$에 대해 미분한 값)은 매우 간단하게 $\hat{y} - y$ 로 계산된다. 최신 딥러닝 프레임워크를 사용하면 정방향 전파(Forward prop)만 정의해도 역전파 과정은 자동으로 처리된다.
The Problem of Local Optima (C2W3L10)
1. Local Optima에 대한 오해와 진실
과거의 직관:
딥러닝 초기에는 알고리즘이 나쁜 지역 최적값에 갇혀 전역 최적값에 도달하지 못하는 것을 크게 걱정했다. 이는 우리가 흔히 2차원 그래프를 통해 상상하는 굴곡이 많은 지형에서 움푹 패인 곳에 갇히는 이미지 때문이다.
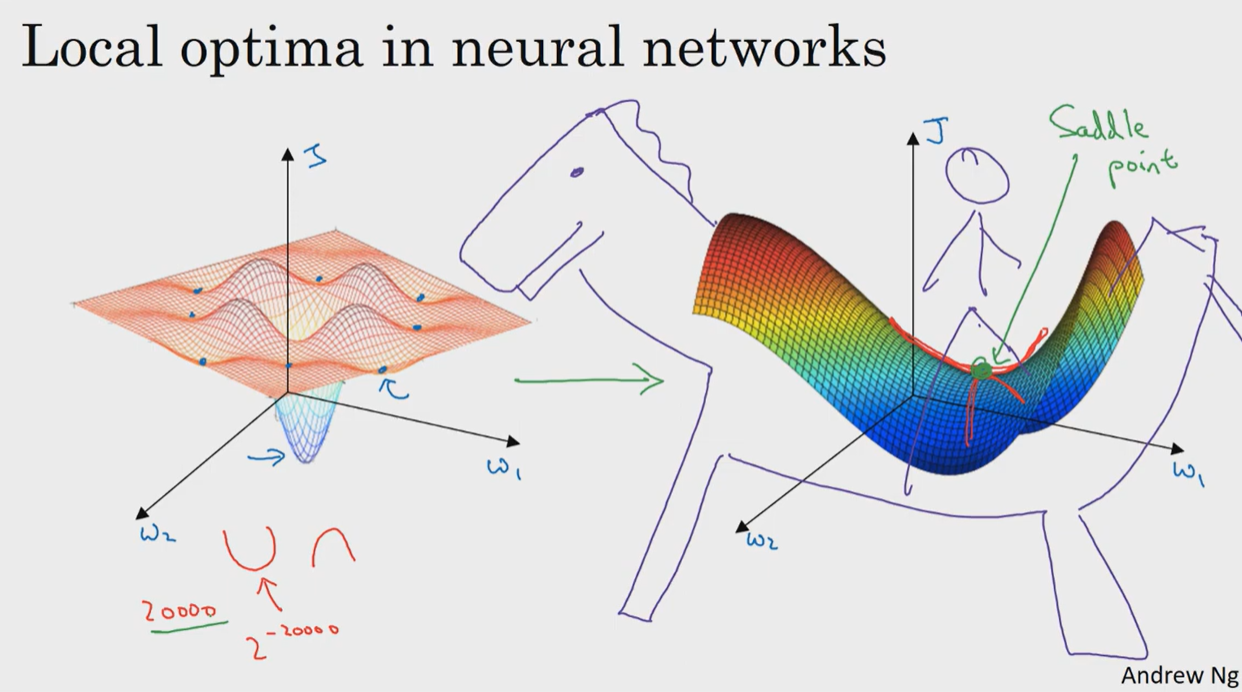
고차원에서의 현실:
하지만 매개변수가 많은 고차원 공간에서는 모든 방향에서 아래로 볼록한 형태, 지역 최적값의 조건이 나올 확률이 극히 희박하다
Saddle Point:
실제로는 어떤 방향에서는 아래로 볼록하고 다른 방향에서는 위로 볼록한 형태인 안장점이 훨씬 더 자주 나타납니다. 이 지점은 미분값이 0이지만 말 안장처럼 생겨서 지역 최적값이 아니다.
2. 진짜 문제는 ‘안정지대(Plateaus)’
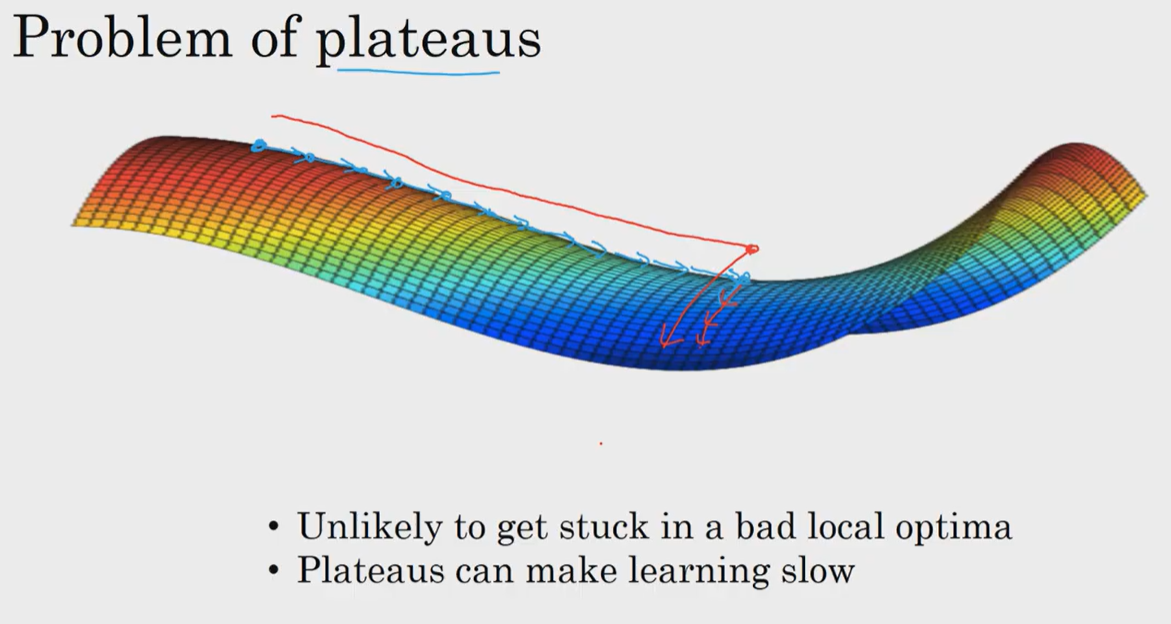
따라서 충분히 큰 신경망을 학습시킬 때 지역 최적값에 갇히는 일은 거의 발생하지 않는다.
최적화 알고리즘이 겪는 진짜 문제는 안정지대(Plateaus) 이다. 미분값이 아주 오랫동안 0에 가깝게 유지되는 평평한 지역.
경사가 거의 없는 이 지역에서는 학습 속도가 극도로 느려지며 알고리즘이 이 평지를 가로질러 벗어나는 데 매우 긴 시간이 걸린다.
3. 해결책 및 결론
이러한 안정지대에서의 느린 학습 문제를 해결하기 위해 Momentum, RMSprop, Adam 같은 발전된 최적화 알고리즘을 사용한다. 이 알고리즘들은 관성 등을 이용해 안정지대를 더 빠르게 통과하고 학습 속도를 높이는 데 도움을 준다.
ai:
지역 최적값을 걱정하는 것은 산을 내려오다가 작은 ‘웅덩이’에 빠져서 못 나오는 것을 걱정하는 것과 같다. 하지만 수만 개의 차원이 있는 고차원 세계에서는 사방이 다 막힌 웅덩이가 생기기 매우 어렵다.
대신 우리가 마주하는 진짜 문제는 끝없이 펼쳐진 ‘평평한 얼음판(안정지대)’이다. 경사가 없어서 어디로 가야 할지 모르고 제자리걸음만 하기 쉬운데, 이때 Adam이나 모멘텀 알고리즘은 미끄러지듯 속도를 붙여서(가속도) 이 얼음판을 빠르게 주파하도록 도와주는 스케이트 역할을 한다.
TensorFlow (C2W3L11)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import numpy as np
import tensorflow as tf
coefficients = np.array([[1], [-20], [25]])
w = tf.Variable([0],dtype=tf.float32)
x = tf.placeholder(tf.float32, [3,1])
cost = x[0][0]*w**2 + x[1][0]*w + x[2][0] # (w-5)**2
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
print(session.run(w))
# or
with tf.Session() as session:
session.run(init)
print(session.run(w))
for i in range(1000):
session.run(train, feed_dict={x:coefficients})
print(session.run(w))
1. 문제 정의 및 기본 설정
목표:
텐서플로우를 사용하여 비용 함수 $J(w) = w^2 - 10w + 25$를 최소화하는 매개변수 $w$를 찾는다. 이 식은 $(w-5)^2$와 같으므로 우리가 기대하는 최적값은 5이다.
변수 정의:
최적화하려는 매개변수 $w$를 tf.Variable로 정의한다.
비용 함수 및 최적화 도구:
tf.add, tf.multiply 등을 사용해 비용 함수를 정의하고 tf.train.GradientDescentOptimizer를 사용하여 이 비용 함수를 최소화하는 train을 정의한다.
2. 세션 실행과 학습 과정
초기화:
tf.Session()을 시작하고 global_variables_initializer를 실행하여 변수를 초기화한다. 초기 $w$값은 0이다.
학습 실행:
session.run(train)을 실행할 때마다 경사 하강법이 한 단계씩 진행된다. 한 번 실행 후 $w$는 약 0.1이 된다.
결과:
약 1,000번의 학습 단계를 반복 실행하면 $w$는 4.99999가 되어 목표값인 5에 매우 근접.
연산자 오버로딩:
텐서플로우는 덧셈, 뺄셈 등의 기본 파이썬 연산자를 지원하므로 tf.add 같은 복잡한 함수 대신 cost = w### **2 - 10*w + 25처럼 직관적인 수식을 사용할 수 있다.
3. 데이터 주입을 위한 Placeholder 활용
유동적인 데이터:
실제 신경망 학습에서는 고정된 숫자가 아니라 학습 데이터($x, y$)에 따라 비용 함수가 달라집니다. 이를 위해 tf.placeholder를 사용한다.
역할:
placeholder는 나중에 값을 넣을 공간을 미리 만들어두는 변수이다. 비용 함수의 계수 등을 placeholder로 설정하면 데이터에 따라 식을 바꿀 수 있다.
데이터 주입 (feed_dict):
session.run을 실행할 때 feed_dict 인자를 사용하여 placeholder에 실제 데이터(배열 등)를 전달한다. 이를 통해 미니 배치 학습 시 매번 다른 데이터 묶음을 모델에 넣을 수 있다.
4. 텐서플로우의 핵심: 계산 그래프와 자동 미분
With 구문:
with tf.Session() as session: 구문을 사용하면 오류 처리(예외 처리)가 더 깔끔해지며 관용적으로 많이 사용된다.
계산 그래프:
사용자가 비용 함수를 코드로 작성하면 텐서플로우는 내부적으로 Computation Graph를 생성한다. 이는 연산의 흐름을 노드와 엣지로 표현한 것이다.
자동 역전파:
텐서플로우의 가장 큰 장점은 사용자가 정방향 전파(비용 함수 정의)만 구현하면 프레임워크가 알아서 미분을 계산하고 Backpropagation를 자동으로 수행한다는 것이다. 따라서 복잡한 미분 공식을 직접 짤 필요가 없다.
유연성:
최적화 알고리즘을 바꾸고 싶다면 코드를 한 줄만 수정하여 경사 하강법 대신 Adam 최적화 알고리즘 등으로 쉽게 교체할 수 있다.