[논문정리] LOOKING BACKWARD: STREAMING VIDEO-TO-VIDEO TRANSLATION WITH FEATURE BANKS
LOOKING BACKWARD: STREAMING VIDEO-TO-VIDEO TRANSLATION WITH FEATURE BANKS(2025).Feng Liang, Akio Kodaira, Chenfeng Xu, Masayoshi Tomizuka, Kurt Keutzer, Diana Marculescu.ICLR 2025
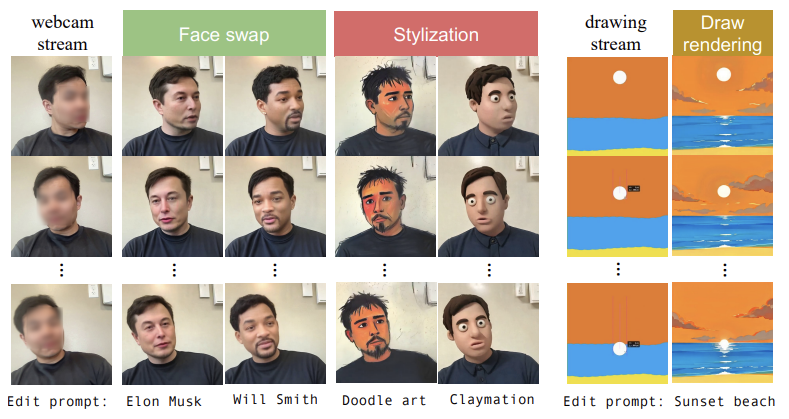
스트리밍 입력을 위한 실시간 비디오-투-비디오 번역을 지원하기 위해 StreamV2V를 제시한다. 웹캠 입력의 경우, 우리의 StreamV2V는 얼굴 교체(일론 머스크로)와 비디오 스타일링(낙서 아트로)을 지원한다. 또한, StreamV2V는 반복적인 창작을 가능하게 하는 그림 렌더링 기능을 제공한다.
Purpose
실시간 스트리밍 video to video 변환을 지원하는 stream video to stream 모델을 소개한다.
Video-to-Video (V2V) Translation
입력 비디오를 사용자의 프롬프트에 따라 변환하는 기술
Streaming Processing
데이터를 한 번에 모두 처리하는 대신 연속적으로 처리하는 방식
Diffusion Model
노이즈로부터 점진적으로 데이터를 생성하는 생성 모델의 한 종류
Methods
과거 프레임의 정보를 저장하는 Feature Bank 유지하고 현재 프레임의 셀프 어텐션에 과거 프레임의 키와 값을 통합하여 temporal consistency를 높인다.
Feature Bank
과거 프레임의 중간 feature 정보를 저장하는 저장소
Self-Attention
입력 시퀀스의 각 요소가 다른 요소들과의 관련성을 학습하는 메커니즘
Temporal Consistency
비디오의 연속적인 프레임 간의 일관성을 유지하는 것
1. Introduction
실시간 스트리밍 V2V 변환을 위한 StreamV2V라는 새로운 확산 모델을 제안한다. 기존 V2V 방법들은 비디오를 batch로 처리하여 저장 공간 제약으로 인해 짧은 길이의 비디오만 처리할 수 있었고 실시간 변환도 불가능했다.
StreamV2V는 이러한 한계를 극복하기 위해 다음과 같은 핵심 아이디어를 제시한다.
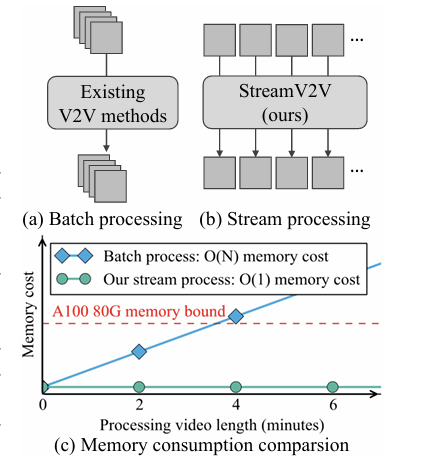
(a) 기존 V2V 방법은 프레임을 batch 단위로 처리하여 처리할 수 있는 프레임 수가 제한. (b) 이 논문의 StreamV2V 프레임워크는 프레임을 streaming 방식으로 처리하며 실시간으로 스트리밍 비디오에서 작동
스트리밍 방식 처리: 입력 비디오를 프레임 단위로 순차적으로 처리하여 비디오 길이에 제한 없이 무한히 긴 비디오도 실시간으로 변환할 수 있다. 이는 배치 처리 방식에서 요구하는 O(N) 메모리 복잡도와 달리 O(1)의 메모리만 사용한다.
“Looking Backward” 원칙: 현재 프레임을 생성할 때 과거 프레임의 정보를 활용하여 시간적 일관성을 유지한다.
피처 뱅크(Feature Bank): 과거 프레임의 중간 특징(intermediate features)을 저장하는 피처 뱅크를 유지한다.
확장된 셀프 어텐션(Extended Self-Attention, EA) 및 직접적인 피처 융합(Feature Fusion, FF): EA는 과거 프레임에서 가져온 keys와 values을 현재 프레임의 셀프 어텐션 계산에 통합하여 과거 프레임의 유사 영역과 현재 프레임을 연결한다. FF는 과거 프레임의 특징과 현재 프레임의 특징 간의 유사도를 기반으로 직접 융합하여 미세한 디테일까지 일관성을 강화한다.
동적 피처 뱅크 업데이트(Dynamic Merging, DyMe): 피처 뱅크 내 중복된 특징들을 병합하여 뱅크를 컴팩트하면서도 정보력을 유지하도록 한다.
StreamV2V의 주요 특징 및 장점:
실시간 성능: 단일 A100 GPU에서 20 FPS로 512x512 해상도의 비디오를 처리할 수 있으며 이는 기존 방법들보다 훨씬 빠르다.
무제한 비디오 길이 지원: 스트리밍 처리 방식으로 인해 비디오 길이에 대한 제약이 없다.
훈련 불필요: 기존 이미지 확산 모델에 쉽게 통합될 수 있는 add-on 형태로 작동하며 별도의 fine-tuning이 필요 없다.
시간적 일관성: 사용자 연구 및 정량적 평가 결과 뛰어난 시간적 일관성을 보여준다.
이 방법이 단순한 queue 방식의 피처 뱅크보다 효율적이며 피처 뱅크의 크기를 단 하나의 프레임 크기로 압축할 수 있음을 실험적으로 보여준다.
2. Related Work
3. Background : Stream Disffusion
StreamDiffusion은 Latent Consistency Model(LCM)을 활용해 확산 모델의 다중 denoising 과정을 스트리밍 방식으로 재구성하여 실시간 이미지 생성을 가능하게 하는 파이프라인이다.
stream batch
기존의 확산 과정은 하나의 이미지에 대해 여러 단계의 denoising을 순차적으로 수행한다. StreamDiffusion은 서로 다른 denoising 단계에 있는 S개의 이미지를 한 번에 배치로 처리한다. 시점 t에서 인코딩된 노이즈 잠재값을 $z_t^{S}$ 라 하면 스트림 배치는 ${\,z_t^{S},\; z_{t-1}^{S-1},\; \dots,\; z_{t-S+1}^{1}\,}$ 와 같이 구성되어 동시에 연산된다.
타임스텝을 한 단계 전진시키면 해당 배치에서 최종 복원된 잠재 $z_{t-S+1}^{0}$을 얻고 이를 디코딩해 출력 이미지 $I’_{t-S+1}$을 생성한다.
1) 현재 프레임 $I_t$를 VAE로 인코딩하고 일정 수준의 노이즈를 더해 잠재 $z_t^{S}$를 만든다.
2) 위에서 설명한 스트림 배치를 구성하여 한 번에 denoising 연산을 수행한다.
3) 배치의 일부가 완전 복원되면 해당 잠재를 디코딩해 출력 이미지를 얻고 새 프레임의 잠재를 배치에 추가해 계속 진행한다.
이 방식은 파이프라인이 warm start을 위해 초기에 동일한 시작 이미지를 S번 넣어 시작하는 전략을 사용한다.
하나씩 스트리밍 하나고 한거 같은데 왜 계속 배치의 개념이 나오는지?
하나씩 스트리밍이지만 내부적으로는 연산 효율성을 위해 여러 denoising 단계에 해당하는 서로 다른 프레임들을 한 번에 묶어 처리하는 stream batch 개념을 쓴다. 일반적인 V2V의 프레임 배치와는 다르다.
한번의 네트워크 호출로 여러 프레임을 동시에 조금씩 전진시키는 방식이다. 배치 안에 같은 프레임이 여러 단계로가 아닌 서로 다른 프레임이 서로 다른 단계로 섞여있다고 한다.
추가로 다시 알아봐야할듯하다..!
속도 향상
StreamDiffusion은 LCM 같은 소수 단계 복원 모델을 쓰기 때문에 전체 스텝 수가 적어 빠르고 추가적으로 Tiny autoencoder와 TensorRT 같은 엔진 최적화를 이용해 추론 속도를 더 높인다.
한계
StreamDiffusion은 프레임별로 독립적으로 이미지를 생성하면 실시간 속도는 확보되지만 temporal consistency이 유지되지 않아 깜박임(flicker)이 발생할 수 있다. 그래서 본 논문에서는 StreamDiffusion의 실시간 파이프라인을 기반으로 하되 과거 프레임의 특징을 재사용하는 feature bank 등을 도입해 시간적 일관성을 보강한 것이다.
4. StreamV2V
StreamDiffusion은 각 프레임을 독립적으로 처리하여 실시간 생성은 가능하지만 프레임 간의 시간적 연속성을 무시해 깜박임(flickering)이 발생한다. StreamV2V는 looking-backward는 원칙으로 현재 프레임이 과거 프레임 정보를 참조하도록 하여 일관성을 개선한다.
4.1. Extended Self-Attention
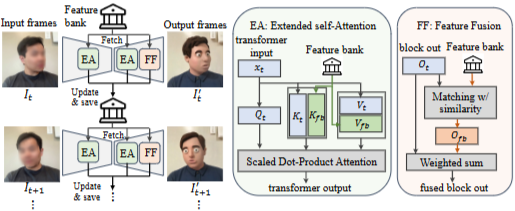
왼쪽: 스트리밍 파이프라인 개요. 각 입력 프레임 It가 들어오면 과거 프레임의 중간 특징들을 저장한 Feature bank에서 관련 특징을 Fetch하여 Extended self-Attention(EA)과 Feature Fusion(FF)을 적용한 뒤 출력 프레임 I′t를 생성. 처리 후에는 bank를 업데이트(merge)하여 저장.
중앙: EA(Extended self-Attention) 구조. 현재 프레임의 transformer 입력 xt로부터 Query Qt, Key Kt, Value Vt를 얻고 과거 프레임에서 저장된 bank의 keys K_fb와 values V_fb를 현재의 Kt/Vt와 이어붙여 attention을 계산.
오른쪽: FF(Feature Fusion) 구조. transformer의 block 출력 Ot의 각 토큰에 대해 bank의 출력 토큰 Ofb 중 가장 유사한 토큰을 찾아 가중합으로 직접 융합하여 세밀한 일관성 유지.
Extended self-Attention(EA)는 U-Net 내부의 self-attention을 확장하여 현재 프레임의 쿼리(Q_t)가 과거 프레임에서 저장해둔 키/값(K_fb, V_fb)을 함께 참조하도록 만든 기법이다. 목적은 현재 프레임을 과거 관찰과 align하여 프레임 간의 temporal consistency을 높이는 것이다.
핵심 아이디어: self-attention 연산에서 키,값 집합을 현재 프레임 것과 feature bank에 저장된 과거 것들을 concatenate해 사용한다.
\[\text{ExAttn} = \text{softmax} \left( \frac{Q_t [K_t, K_{fb}]^T}{\sqrt{d}} \right) [V_t, V_{fb}]\]$Q_t \in \mathbb{R}^{n\times d}$
현재 프레임의 query 행렬 (토큰 수 n, 차원 d).
$K_t \in \mathbb{R}^{n\times d},\; V_t \in \mathbb{R}^{n\times d}$
현재 프레임의 key, value 행렬.
$K_{fb} \in \mathbb{R}^{m\times d},\; V_{fb} \in \mathbb{R}^{m\times d}$
feature bank에 저장된 past-keys와 past-values (은행의 크기 m).
현재 프레임의 쿼리들이 feature bank에 저장된 과거 키들과 내적해 어떤 과거 위치가 유사한가를 계산한다.
softmax로 정규화된 가중치를 얻어 그 가중치로 현재와 과거의 value들을 가중합한다.
이렇게 계산된 출력은 현재 프레임의 표현을 과거의 일치하는 부분들과 연결시키므로 색감, 구조, 세부의 시간적 일관성이 개선된다.
EA는 U-Net의 모든 self-attention 레이어와 모든 denoising 타임에서 적용됨
bank 크기 mmmm은 dynamic merging(DyMe)로 작게 유지되므로 계산 오버헤드 억제 가능.
bank가 부정확하거나 적절한 과거 매칭이 없을 경우(빠른 카메라 이동 등) 잘못된 참조가 생겨 일시적 아티팩트가 나올 수 있다. 그래서 paper는 EA에 더해 Feature Fusion(명시적 유사도 기반 합성)와 유사도 임계값 마스크를 함께 사용.
Extended self-Attention은 현재 토큰이 저장된 과거 키/값들을 직접 참조하도록 self-attention을 확장하여 스트리밍 환경에서도 프레임 간 일관성을 확보하는 간단하면서도 효과적인 방법이다.
4.2 FEATURE FUSION
Feature Fusion(FF)는 Extended self-Attention(EA)가 암묵적으로 제공하는 시간적 일관성 보강을 보완하기 위한 명시적 방법이다. 핵심 아이디어는 현재 프레임의 각 토큰에 대해 피처 뱅크에 저장된 과거 토큰 중 가장 유사한 하나를 찾아 그 값을 직접 섞어준다는 것이다. 이렇게 하면 세세한 디테일이 과거와 더 일관되게 유지된다.
\[O'_t(p) = (1-\alpha)\,O_t(p) + \alpha\,O^{fb}(q)\] \[q = \arg\max_{j}\; \cos\big(O_t(p),\,O^{fb}(j)\big)\]여기서 코사인 유사도는
\[cos(u,v)=\frac{\|u\|\|v\|}{u \cdot v}\]유사도 기반 마스킹
모든 현재 토큰에 대해 피처 뱅크의 최댓값 유사도를 계산하고 그 값이 사전정의된 임계값보다 낮으면 융합을 건너뛴다(마스크).
현재 프레임에 새로 등장한 영역을 잘못 매칭해서 엉뚱하게 덮어쓰는 것을 방지하기 위함이다.
적용 위치
논문 실험에서는 고해상도(상세) 레이어에서 직접 융합을 하면 디테일이 희석되어 블러 현상이 생길 수 있음을 관찰했다. 따라서 FF는 저해상도 블록에서만 적용하는 것이 품질, 일관성에서 더 좋다. 이 위치들은 구조적/상황적 정보를 보존하면서도 세부 노이즈를 덜 손상시킨다.
EA(Extended self-Attention)와의 관계
EA는 현재 쿼리가 피처 뱅크의 key/value와 상호작용하도록 하여 간접적으로 과거 정보를 반영한다. FF는 그와 달리 해당 토큰을 직접 과거 토큰과 평균하는 방식으로 더 명시적이고 강한 일관성 보정 효과를 낸다. 두 기법을 같이 쓰면 서로 보완되어 전체적인 시간적 일관성이 더 좋아진다
Feature Fusion은 가장 닮은 과거 패치 한 조각을 찾아 현재 패치와 섞어주는 명시적 복붙이다. 유사도가 충분히 높을 때만 적용해서 새로 나온 요소는 보존하고 기존에 반복되는 요소는 과거와 맞춰 일관되게 만든다.
약간 헷갈렸던 것: 여기서 마스크는 병합하지 않음을 의미하는 것이지 학습에 반영하지 않음이 아님
4.3 UPDATING THE FEATURE BANK WITH DYNAMIC MERGING
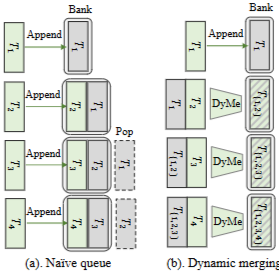
왼쪽 (a): Naïve queue(단순 큐) 방식
들어오는 각 프레임의 특징 T1, T2, T3, T4(초록) 을 순차적으로 Bank(회색)에 append.
Bank가 최대 용량에 도달하면 가장 오래된 항목을 pop(점선)하여 제거함.
결과: 시간 축 정보를 오래 유지하지 못하고, 비슷한 특징이 중복 저장되어 비효율적.
오른쪽 (b): Dynamic merging (DyMe)
새로 들어온 특징을 단순 적재만 하지 않고 기존 Bank의 특징들과 병합(merge)함.
T1, T2 가 만나면 T{1,2} 로 합쳐지고, 이후 T3 와 합쳐져 T{1,2,3} 같이 압축된 표현을 유지.
시각적으로 병합된 블록은 무늬(해시/스트라이프)로 표시되어 여러 프레임 정보를 담고 있음을 나타냄.
결과: Bank 크기는 작게 유지하면서도 긴 시계열 정보를 보존.
DyMe(동적 병합)의 동작 원리(핵심 단계)
현재 프레임 특징(current)과 Bank에 저장된 특징(stored)을 concatenate 하여 전체 집합을 만듦.
전체를 무작위로 절반씩 src와 dst로 분할(random partition).
각 src 벡터 f_src 에 대해 cosine 유사도로 가장 유사한 dst 벡터 f_dst 를 찾음대응된 쌍을 병합(merge) — 간단히 평균을 취함
dst 집합(병합된 것)이 업데이트된 feature bank가 됨(크기는 유지됨).
StreamV2V의 feature bank는 과거 프레임의 중간 feature들을 저장해 현재 프레임 생성 시 참조한다. Dynamic Merging (DyMe)은 이 bank를 컴팩트하면서도 정보량을 유지”하도록 주기적으로 update하는 전략이다. 목표: 오래된 프레임을 단순히 버리는 naive queue보다 더 넓은 시간 정보를 적은 용량으로 유지하면서 중복을 제거.
고정 개수(frames)만 저장 → 시간 범위가 짧아짐(긴 비디오는 정보 손실). 저장된 프레임들이 비슷하면 중복이 많아 비효율적(메모리·연산 낭비).
현재 프레임의 모든 transformer 중간 feature들 T_t = {K_t, V_t, O_t}를 기존 feature_bank와 concatenate 한다. 전체 feature들을 무작위로 두 세트(src, dst)로 반반 나눈다(랜덤 partition). 각 src feature에 대해 dst에서 가장 유사한 feature를 찾아 매칭(효율적 bipartite matching 기법 사용 가능).
유사도는 cosine similarity 사용:
\[\mathrm{sim}(f_{src}, f_{dst})=\frac{f_{src}\cdot f_{dst}}{\|f_{src}\|\|f_{dst}\|}\]매칭된 쌍에 대해 src를 dst에 병합(평균)하여 dst를 업데이트:
\[f^{\text{new}}_{dst} = \frac{f_{src} + f_{dst}}{2}\]업데이트된 dst 집합이 새로운 compact feature bank가 된다(크기는 원래 한 세트 크기와 동일).
랜덤 partition:
current features가 bank를 지배하지 않도록 균형을 맞추기 위함. 실험에서 random이 uniform grid나 split보다 성능(낮은 warp error)이 좋음.
평균(average) 병합: 간단하고 안정적으로 두 특징을 섞어 대표성을 유지. (token merging 계열의 아이디어와 유사) 병합 빈도: 논문 기본값은 4프레임마다 업데이트(실험 상 8프레임도 좋은 성능). 움직임이 크면 더 자주 업데이트 필요. bank 크기: 실험 결과 DyMe는 bank를 한 프레임 분량으로 응축해도 성능 유지 가능 → 메모리 O(1)에 가까움. 연산/메모리 영향: DyMe는 naive queue보다 메모리·시간에서 더 유리한 trade-off(예: Table 2에서 DyMe(1)는 queue(2)보다 빠르고 warp error가 낮음).
DyMe 장점
장기 정보(더 많은 과거 프레임)를 보존하면서도 저장 공간을 줄임.
중복 feature 제거로 연산 효율 개선.
StreamV2V 전체의 temporal consistency 향상(특히 warp error 감소).
5. experiment
6. conclusion
StreamV2V라는 실시간 streaming video-to-video( V2V ) 변환 시스템을 제안한다.
핵심 아이디어는 looking-backward로, 현재 프레임이 과거 프레임의 정보를 참조하도록 하여 시간적 일관성(temporal consistency)을 유지한다. 이를 위해 intermediate features을 저장하는 feature bank 와 저장된 특징을 재사용하는 비학습적 기법 Extended self-Attention, Feature Fusion 을 도입한다.
EA는 현재 프레임의 self-attention 계산에 과거 프레임에서 저장한 keys/values를 concatenate하여 현재 쿼리가 과거에 있는 유사한 위치들을 참조하도록 만드는 기법이다. 이는 stream-batch의 효율성은 유지하면서도 과거 정보를 참조해 시간적 일관성(temporal consistency)을 향상시키려는 목적이다.
FF는 현재 위치 p 와 가장 유사한 과거 특징 q 를 찾아 직접 가중합한다. 미세한 디테일의 일관성 보강한다.
DyMe는 feature bank의 크기를 고정하면서도 시간적으로 대표성 있는(중복 적은) 토큰들을 유지하기 위해 새로 들어온 프레임의 토큰들과 기존 은행 토큰들을 쌍별 매칭하여 유사한 토큰들을 병합(average)하는 온라인 병합 전략이다. bank를 작게 유지하면서도 과거 정보 스펙트럼을 보존한다.