[논문정리] Learning Transferable Visual Models From Natural Language Supervision
Learning Transferable Visual Models From Natural Language Supervision(2021).Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.arXiv
2021년에 발표된 Learning Transferable Visual Models From Natural Language Supervision, 즉 CLIP입니다.
CLIP은 “이미지를 보고 설명하는 모델”이라기보다, “이 이미지는 제시된 설명 중 어떤 것과 가장 가깝니?”라고 물어봤을 때 답을 하는 모델
이 논문의 핵심은 자연어를 감독자로 활용해 시각 모델을 학습시킨다는 것입니다. 기존 모델들이 ‘이 사진은 개야’라고 암기했다면, CLIP은 ‘개라는 개념’을 언어적으로 이해합니다. 결과적으로 추가 학습 없이도(Zero-shot) 수많은 벤치마크를 정복했습니다.
결과: ResNet-50의 ImageNet 유사한 성능 달성
자연어 감독?
기존의 컴퓨터 비전 모델처럼 숫자로 된 라벨을 보고 배우는 것이 아니라 인터넷에 널려 있는 텍스트를 감독자로 삼아 학습하는 방식을 말한다.
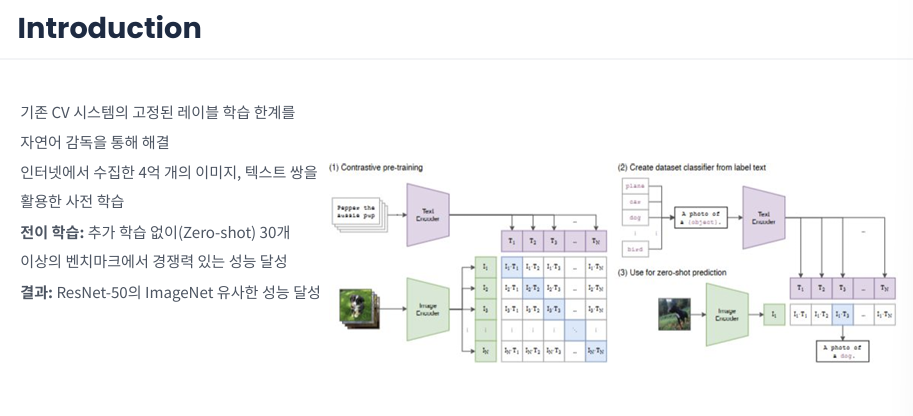
1. 대조 사전 학습 (Contrastive Pre-training)
그림의 왼쪽 (1)번 과정입니다. CLIP은 웹에서 수집한 이미지와 그에 대응하는 텍스트 쌍을 동시에 학습합니다.
• 학습 방식: 이미지 인코더와 텍스트 인코더를 통해 각각의 특징(Feature)을 추출한 뒤, N X N 행렬에서 대각선에 위치한 정답 쌍(Positive Pair)의 유사도는 높이고, 나머지 오답 쌍(Negative Pair)의 유사도는 낮추도록 학습합니다.
• 핵심: 단순히 이미지를 분류하는 법을 배우는 것이 아니라, 이미지와 텍스트 사이의 연관성을 배웁니다.
2. 데이터셋 분류기 생성 (Create Dataset Classifier)
오른쪽 위 (2)번 과정입니다. 학습이 끝난 후 특정 데이터셋을 분류하기 위해 라벨을 준비합니다.
• 프롬프트 활용: 단순히 ‘dog’, ‘cat’ 같은 단어만 쓰지 않고, “A photo of a {object}.” 와 같은 문장 템플릿에 라벨을 넣어 자연어로 변환합니다.
• 가중치 생성: 이 문장들을 텍스트 인코더에 통과시켜 각 클래스를 대표하는 텍스트 임베딩(가중치) 을 미리 생성해 둡니다.
3. 제로샷 예측 (Zero-shot Prediction) 오른쪽 아래 (3)번 과정입니다. 실제 추론 단계입니다.
• 유사도 매칭: 새로운 이미지가 들어오면 이미지 인코더를 통해 벡터를 추출합니다. 이 이미지 벡터와 앞서 (2)단계에서 만든 여러 텍스트 벡터들 간의 유사도를 비교합니다.
• 최종 판정: 유사도가 가장 높은 문장(예: “A photo of a dog.”)을 찾아내어 해당 이미지를 ‘개’라고 최종 예측합니다.
요약하자면, CLIP은 고정된 라벨 번호를 맞추는 것이 아니라 “이미지와 가장 잘 어울리는 문장을 찾는 방식”으로 작동하기 때문에, 별도의 재학습 없이도 새로운 데이터를 분류할 수 있는 유연성을 가진다.

지난 10년간 우리는 ImageNet 방식에 갇혀 있었습니다.
이미지넷 방식?
미리 정의된 카테고리 내에서만 정답을 찾도록 모델을 가두는 패쇄형 학습
제한된 감독: 1,000개의 카테고리로 학습된 모델은 1,001번째 물체를 보는 순간 바보가 됩니다. ‘Open-vocabulary’ 능력이 전혀 없다는 뜻입니다.
미리 정의된 고정된 범주의 객체만 인식 가능. 새로운 개념 학습 시 수작업 데이터가 필수적임.
전통적인 이미지넷 방식은 모델에게 1000개의 단어만 가르친다. 이때 모델은 1000지 선다형. 전동킥보드를 학습시키지 않으면 전동 킥보드를 보고 맞출 수 없어 자전거를 택한다. 학습하지 않은 새로운 개념이 등장하면 아예 인식 자체가 불가능한 지능 단절 상태
open-vocabulary : 세상의 모든 단어를 조합해 설명할 수 있는 언어 능력 그 자체
높은 비용: 사람이 일일이 라벨링하는 방식은 4억 장의 데이터를 처리할 수 없습니다.
ImageNet과 같은 고품질 데이터셋 구축에는 막대한 시간과 비용이 소요됨.
취약성: 훈련 데이터셋의 특징(Bias)에만 최적화되어, 실제 환경에서 사진의 각도만 바뀌어도 성능이 폭락합니다. 이를 Robustness Gap이라 부르며, CLIP은 이를 해결하고자 등장했습니다.
특정 데이터셋에 과적합되어 실제 환경의 다양한 시각적 개념 전이에 취약함.

당시 NLP 분야에서는 특정 작업에 종속되지 않는 Task-Agnostic Pre-training이 이미 대세로 자리 잡고 있었습니다. 그 중심에는 GPT-3가 있으며, 이는 웹 규모의 방대한 원시 텍스트를 직접 학습하여 모델의 범용성을 증명했습니다.
이러한 성공을 가능하게 한 구체적인 요소는 다음과 같다.
- 데이터 규모: 정제된 라벨링 데이터가 아닌, 웹상의 대규모 원시 데이터를 직접 활용했습니다.
- 인터페이스의 표준화: 모든 문제를 “텍스트 투 텍스트” 방식으로 통일하여 모델의 유연성을 극대화했습니다.
- Zero-Shot 학습: 별도의 미세 조정(Fine-tuning)이나 커스터마이징 없이도 다양한 하위 태스크를 즉각 수행할 수 있게 되었습니다.
결국 본 연구는 이러한 NLP의 성공적인 확장 방식을 시각 지능 분야에 도입하고자 하는 시도입니다. “컴퓨터 비전에서도 자연어라는 방대한 지도를 기반으로 모델을 확장하는 것이 가능할까?” 라는 질문이 CLIP 연구의 시작점이 되었습니다.
Text-to-Text
input과 output 형식을 오직 자연어 문자열 하나로 설계하는 패러다임.
기존 방식: [이미지] → 모델 → [0번(강아지)]
Text-to-Text 방식: [이미지 + “이 사진에 무엇이 있니?”] → 모델 → [“강아지가 있습니다.”]
task-agnostic ? pre-training?
task-agnostic: 나는 특정 task를 잘하는 범생이가 아니라 무엇이든 물어봐도 대답하는 박학다식한 존재가 되자
pre-training: 그걸 위해 미리 읽는 과정
어떤 용도로 쓰일지 미리 정하지 않고 일단 세상의 모든 지식을 거대하게 먼저 가르치는 방식
nlp 무엇을 어떻게 비전에 적용?
nlp가 성공한 비결을 컴퓨터 비전에 가져온 것이 CLIP의 핵심.
nlp에서 단어 사이 관계를 배우듯 이미지 벡터와 텍스트 벡를 하나의 공간에 둔다. 강아지 사진과 강아지라는 단어가 같은 좌표 근처에 찍히도록 정렬해 비전 모델이 nlp처럼 문맥을 이해하게 한다.

압도적인 규모의 확장
기존 컴퓨터 비전 연구에서 주로 사용되던 MS-COCO 데이터셋이 약 10만 개 수준이었던 것과 비교해, WIT는 그보다 수천 배 큰 4억 개의 이미지-텍스트 쌍을 수집했습니다. 이러한 거대 규모의 데이터는 모델이 특정 레이블에 갇히지 않고 세상의 다양한 맥락을 학습하게 합니다.
원래는 다양하지 않아서 레이블에 갇혔던 건지
YES. 기본 모델은 고정된 카테고리 안에. 넘어가는 물체는 모델에게 존재하지 않는 물체.
시각적 개념의 다양성 확보
단순히 양만 늘린 것이 아니라 약 50만 개의 검색 쿼리를 활용해 인터넷상의 광범위한 시각적 개념을 커버했습니다. 이를 통해 일상적인 사물부터 추상적인 개념까지 아우르는 폭넓은 이해력을 갖추게 되었습니다.
데이터 정제와 일반성 유지 인터넷의 원시 데이터를 최대한 활용하되, 과도한 필터링 대신 최소한의 정제만을 거쳤습니다. 이는 데이터의 편향을 줄이고 모델이 실제 세상의 복잡한 데이터를 처리할 수 있는 일반성을 유지하기 위함입니다.
최소한의 필터링인거랑 일반성과 무슨 관계?
데이터를 너무 깨끗하게 깎아내면 모델은 현실 세계의 복잡함을 견디지 못한다. CLIP은 필터링을 최소화해 인간의 좁은 시야에 갇히지 않고 웹에 존재하는 방대한 지식 분포를 흡수한다.
이 WIT 데이터셋은 규모 면에서 NLP의 혁신을 이끌었던 GPT-2의 학습 데이터와 유사한 수준이며, 이를 통해 비전 모델에서도 텍스트 기반의 거대 규모 학습이 가능하다는 것을 입증했습니다.

이 부분이 기술적으로 매우 중요합니다. 처음엔 이미지를 보고 문장을 생성하는 방식을 시도했지만 연산량이 너무 많아 효율이 떨어졌습니다. 저자들은 대조 학습(Contrastive Learning) 으로 선회했습니다. 텍스트를 정확히 생성하는 대신 N개의 이미지와 N개의 문장 중 서로 짝이 맞는 쌍을 찾아내는 방식을 택한 것이죠. 이는 생성 방식보다 4배 이상 효율적이었으며 모델이 이미지의 핵심 특징을 빠르게 추출하게 만들었습니다.
학습: 이미지와 텍스트 임베딩 간의 코사인 유사도 극대화
코사인 유사도 극대화란 이미지와 텍스트를 숫자 벡터로 바꾼 뒤 서로 관련 있는 것끼리 화살표 방향을 똑같이 맞추는 과정
코사인 유사도: 얼마나 같은 방향인지
극대화: 정답 쌍.
positive pair: 강아지 사진과 강아지 글자의 임베딩 화살표가 최대한 같은 바향을 향하도록 모델의 가중치 조절.
negative pair: 강아지 사진과 자동차라는 글자는 서로 먼 방향을 향하도록 밀어낸다.
이 방법으로 CLIP에 이미지 공간과 텍스트 공간이 하나로 합쳐진다. 사진을 보든 글을 읽든 같은 의미라면 같은 좌표 공간에 모이게 된다. CLIP이 별도 학습 없이도 사진을 보고 알만은 단어를 찾아낼 수 있는 이유이다.
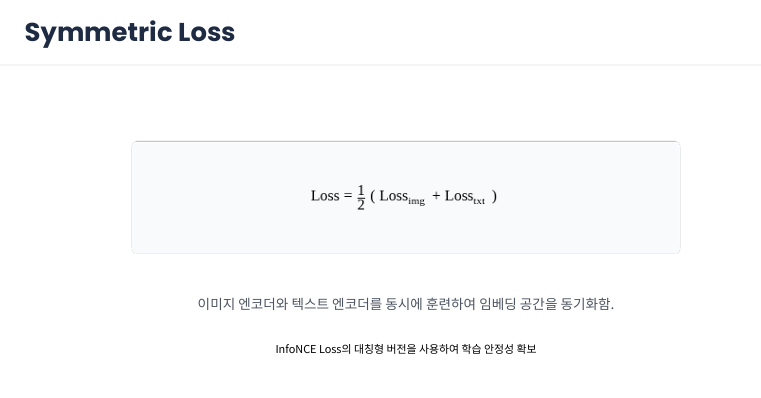
CLIP은 이미지와 텍스트라는 서로 다른 데이터를 하나의 공유 공간에서 정렬하기 위해 Symmetric Loss를 도입했습니다.
symmetric loss 뜻
대칭 손실. 이미지와 텍스트는 서로 다른 도메인 데이터를 하나의 공유 공간(shared embedding space)에서 서로 마주보게 alignment
이게 어떻게 동기화한다는건지 동기화한다는게 맞긴 맞는지
이미지 인코더 출력 벡터를 v, 텍스트 인코더 출력 벡터를 u라고 할때 두 인코더가 서로 다른 숫자 체계를 쓰지 않도록 joint training 시켜 하나의 공간으로 묶는 것이다. 이미지 인코더는 텍스트 인코더가 만든 좌표를 향해 가고 동시에 텍스트 인코더는 이미지 인코더가 만든 좌표로 달려간다. 어느 한쪽이 기준이 되는 것이 아니라 두 모델이 서로 위치를 참고하며 정렬되기 때문에 동기화된다고 표현하는 것이다.
Loss_img (행 방향): $N$개의 문장 중 사진에 딱 맞는 문장을 찾아내는 능력입니다.
Loss_txt (열 방향): $N$개의 사진 중 문장에 딱 맞는 사진을 찾아내는 능력입니다.
이 두 손실값을 합쳐 평균(1/2) 을 내는 이유는 이미지 인코더와 텍스트 인코더 중 어느 한쪽으로 지식이 쏠리지 않고 동등하게 학습(동기화) 시키기 위해서입니다.
임베딩 공간의 동기화 이미지 인코더와 텍스트 인코더를 동시에 훈련시켜, 두 데이터가 같은 의미를 가질 때 임베딩 공간 내에서 가까운 위치에 놓이도록 동기화합니다. 단순히 한쪽을 다른 쪽에 맞추는 것이 아니라, 두 모델이 서로를 향해 학습하며 시각 지능과 언어 지능을 결합하는 과정입니다.
대칭형 InfoNCE를 통한 안정성 이러한 대칭형 InfoNCE Loss 구조는 학습 과정을 매우 안정적으로 만들어줍니다. 한 방향으로 편향되지 않고 양방향에서 서로를 견인함으로써, 4억 개의 거대 데이터셋 학습에서도 무너지지 않는 견고한 최적화가 가능해집니다.

이미지 인코더는 ResNet과 ViT를, 텍스트 인코더는 Transformer를 사용합니다.
이미지 인코더: CNN과 Transformer의 병행 이미지 정보를 처리하기 위해 두 가지 방식의 인코더를 사용합니다.
- ResNet 계열: 기본적인 RN50부터 성능 개선 모델인 RN50x64까지 확장하여 기존 합성곱 신경망의 잠재력을 최대한 활용했습니다.
- Vision Transformer(ViT): 최신 기술인 ViT-B/32, B/16, L/14 모델을 적용해 데이터 규모에 따른 유연한 성능 확장을 실현했습니다.
텍스트 인코더: 최적화된 Transformer 구조 텍스트 처리는 63M 파라미터 기반의 Transformer 모델이 담당합니다.
- BPE 토큰화: 약 4.9만 개의 어휘 사전을 활용해 텍스트를 효율적으로 임베딩합니다.
- 컨텍스트 제한: 효율적인 연산을 위해 시퀀스 길이를 최대 76개 토큰으로 설계하여 데이터 처리 속도를 높였습니다.
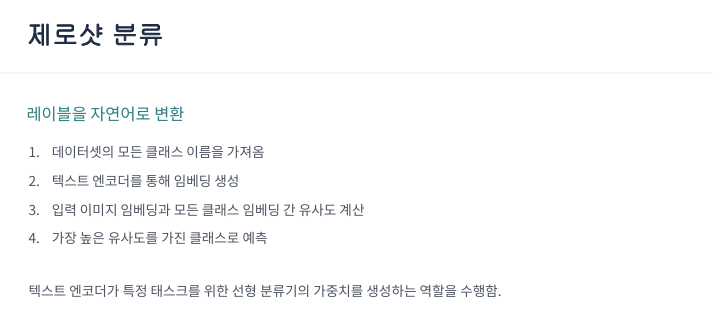
레이블을 자연어로 변환하는 과정 CLIP의 추론은 고정된 번호(ID)가 아닌 자연어를 매개체로 한다.
- 먼저, 분류하고자 하는 모든 클래스 이름을 가져옵니다. (예: ‘개’, ‘고양이’)
- 텍스트 인코더를 통해 이 이름들을 임베딩 벡터로 변환합니다.
- 입력 이미지 역시 인코더를 통해 임베딩을 생성한 후, 이미지 벡터와 모든 클래스 벡터 간의 유사도(Similarity) 를 계산합니다.
- 결과적으로 가장 높은 유사도를 가진 클래스를 최종 정답으로 예측합니다.
Hypernetwork 관점의 깊이 있는 이해 (우측 박스 내용) 일반적인 분류 모델은 마지막 레이어의 가중치(Weight)가 고정되어 있어 새로운 클래스를 배우려면 재학습이 필요합니다.
하지만 CLIP은 텍스트 인코더가 특정 태스크를 위한 선형 분류기의 가중치를 실시간으로 생성해주는 역할을 합니다. 즉, 클래스 이름만 바꿔주면 모델 스스로가 즉석에서 새로운 분류기를 만들어내는 유연성을 갖게 되는 것입니다.

CLIP은 단순히 단어를 입력하는 것을 넘어, 문맥을 디자인하는 프롬프트 엔지니어링을 통해 모델의 잠재력을 최대로 끌어냈습니다.
템플릿 활용의 위력: 단순히 ‘개’라고 명명하기보다 “A photo of a {label}” 과 같이 자연스러운 문장 형식을 취했을 때 성능이 1.3% 향상되었습니다. 이는 모델이 학습했던 데이터의 분포와 추론 형식을 맞추는 중요한 과정입니다.
어떻게 그러는가? 단순한 단어보다 문장 template가 성능이 높은 이유는 모델이 공부했던 환경을 동일하게 재현해주기 때문이다. WIT 학습 데이터가 그런 형태였다.
80개의 프롬프트 앙상블: 하나의 프롬프트에 고정되지 않고, 서로 다른 문맥을 가진 80개의 프롬프트를 사용해 예측값을 평균 냈습니다. 이 앙상블 전략은 결과적으로 3.5%의 추가 성능 향상을 가져오며 모델의 강건함을 증명했습니다.
- 평균방법
- 1단계 문장 생성: 강아지라는 라벨 하나를 80개의 템플릿에 넣습니다. (예: “강아지 사진”, “강아지 스케치”, “강아지 근접 촬영” 등 80개)
- 2단계 벡터화: 이 80개의 문장을 각각 텍스트 인코더에 통과시켜 80개의 독립적인 임베딩 벡터를 추출합니다.
- 3단계 평균 계산: 생성된 80개 벡터의 각 차원 값을 모두 더한 뒤 80으로 나누어, 강아지를 상징하는 단 하나의 평균 벡터(Mean Vector) 를 산출합니다.
- 4단계 유사도 측정: 이렇게 만들어진 평균 벡터와 입력 이미지 벡터 사이의 유사도를 계산하여 최종 정답 여부를 판별합니다.
모호성 제거와 다의어 해결: “Cranes”처럼 중의적인 단어의 경우, 주변 문맥 프롬프트를 통해 이것이 기계인지 동물인지 명확히 구분할 수 있습니다. 자연어 기반의 확장이 가진 유연성이 빛을 발하는 지점입니다.
어떻게 모호성 제거?
단어가 가진 고립된 의미를 문맥으로 잡아두는 것이다. 기존에는 단순히 라벨로 인식하지만 CLIP은 텍스트 인코더를 통해 문장 전체의 의미를 벡터화한다.

왼쪽 표를 보시면, 2017년 발표된 기존의 시각 모델인 Visual N-Grams와 비교했을 때 모든 데이터셋에서 비약적인 발전을 이루었습니다. 특히 ImageNet에서는 11.5%에 불과했던 기존 성능을 76.2%까지 끌어올리며, 제로샷 모델이 실전에서도 충분히 강력할 수 있음을 증명했습니다.
지도 학습 모델인 ResNet-50과 대등한 성능 가장 놀라운 점은 CLIP이 ImageNet의 학습 데이터 128만 개를 단 하나도 보지 않고도(Zero-shot), 수개월 동안 해당 데이터를 공부한 ResNet-50과 동일한 수준의 정확도를 달성했다는 점입니다.
- Top-1 정확도: 76.2%를 기록하며 지도 학습 모델의 기준선을 통과했습니다.
- Top-5 정확도: 95%를 달성하여 Inception-V4와 같은 고성능 모델 수준에 도달했습니다.
범용적 사전 학습의 의의 이 결과의 핵심 의의는 범용적 사전 학습(General-purpose Pre-training)의 가능성입니다. 특정 작업을 위해 정제된 데이터를 수집하고 라벨링하는 고비용의 과정 없이도, 웹상의 방대한 데이터를 학습하는 것만으로 특정 태스크 전용 모델을 대체가능하다
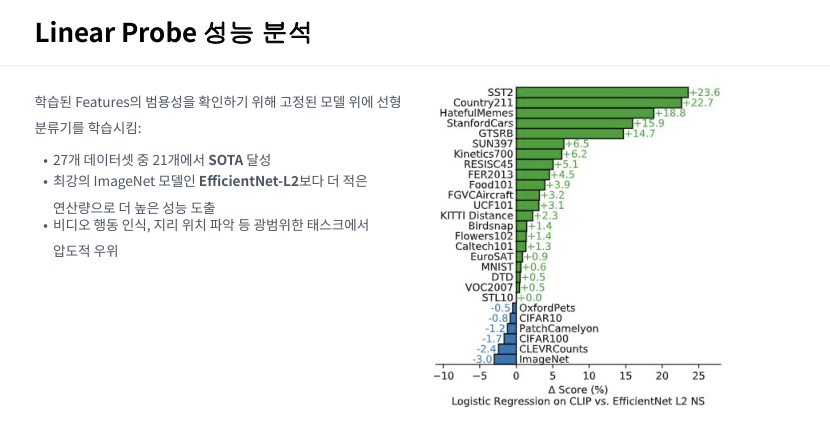
CLIP의 인코더를 고정(Freeze)하고 그 위에 선형 분류기만 추가하여 학습시킨 결과, CLIP은 특정 데이터셋에 특화된 기존 모델들을 압도하는 성능을 보여주었습니다.
- 27개 중 21개 데이터셋 SOTA: 총 27개의 광범위한 데이터셋 중 무려 21개에서 당시 최고 성능(SOTA)을 경신하며 특징 추출기 성능을 증명했습니다.
- EfficientNet-L2 NS 모델 압도: 우측 그래프를 보시면, 당대 최강의 이미지 분류 모델이었던 EfficientNet-L2보다 훨씬 더 적은 연산량으로도 더 높은 성능(녹색 막대)을 내는 것을 확인할 수 있습니다.
- 압도적인 태스크 커버리지: 일반적인 사물 분류뿐만 아니라 비디오 행동 인식(Kinetics700), 지리 위치 파악 등 고도의 지능이 필요한 영역에서도 기존 모델들을 큰 격차로 따돌렸습니다.
그래프 해석 및 의의 우측 그래프의 녹색 막대는 CLIP이 EfficientNet-L2보다 우수한 데이터셋을 의미합니다. 대다수의 지표가 녹색으로 채워져 있다는 것은, CLIP이 웹 규모의 방대한 텍스트-이미지 쌍을 통해 세상의 시각적 정보를 얼마나 깊이 있게 이해하고 있는지를 단적으로 보여줍니다.
결국 CLIP은 단순히 문장을 읽는 모델이 아니라, 어떤 시각 지능 태스크에도 바로 투입될 수 있는 ‘최강의 시각적 기초 모델(Foundation Model)’임을 이 실험이 증명하고 있습니다.
efficientNet-L2?
구글이 개발한 efficientNet 제품군 중 가장 큰 모델로 CLIP 논문 발표 당시 지도 학습 기반 이미지 분류 분야에서 SOTA. efficientNet-L2는 ImageNet이라는 정해진 범위에서는 1등이지만 사진의 각도가 바뀌거나 화풍이 바뀌는 경우에는 성능이 급감한다.

분포 변화와 강건성(Robustness)의 차이
좌측 그래프는 ImageNet 성적과 실제 환경(Distribution Shift) 성적의 상관관계를 보여줍니다. 파란색 선으로 표시된 기존 지도 학습 모델들은 ImageNet 점수가 높더라도 데이터 분포가 조금만 바뀌면 성능이 급격히 추락합니다. 반면, 보라색 선인 Zero-Shot CLIP은 이상적인 강건성 지표인 y=x 점선에 매우 가깝게 위치하며, 기존 모델 대비 Robustness Gap을 최대 75% 감소시켰습니다.
데이터셋별 성능 격차 분석
가운데 표를 통해 실제 사례를 확인해 보겠습니다. ImageNet-A(인공지능이 헷갈리도록 의도된 자연 이미지)나 Sketch(스케치 이미지) 같은 데이터셋에서 그 차이가 극명합니다.
• 기존 ResNet101: 바나나의 형태가 조금만 왜곡된 ImageNet-A에서 정확도가 2.7% 까지 폭락합니다. 사실상 사물을 판별하지 못하는 수준입니다.
• Zero-Shot CLIP: 동일한 데이터셋에서 77.1% 라는 놀라운 성적을 유지합니다. 무려 74.4%의 성능 격차를 벌리며 압도적인 우위를 점했습니다.
진정한 의미의 일반화
이러한 결과는 CLIP이 특정 데이터셋의 라벨링 방식이나 촬영 각도 같은 편향(Bias) 을 학습한 것이 아니라, 4억 개의 방대한 데이터를 통해 사물의 본질적인 특징을 이해했음을 시사합니다. 결국 “진정한 의미의 일반화”란 특정 환경에 최적화된 모델이 아닌, 어떤 환경에서도 범용적으로 작동하는 지능임을 CLIP이 증명해 낸 것입니다.
전문 분야 및 세밀한 분류의 취약성
일반적인 사물 인식과 달리, 특정 자동차의 세부 모델이나 꽃의 구체적인 품종을 구분하는 세밀한 분류(Fine-grained Classification) 에서는 전문 데이터셋으로 학습된 모델에 비해 성능이 낮습니다. 이는 광범위한 데이터를 학습하는 과정에서 아주 좁고 깊은 도메인 지식까지 완벽히 포착하기는 어려웠음을 시사합니다.
추상적이고 체계적인 태스크의 한계
이미지 내의 물체 개수를 정확히 세는 카운팅(Counting) 이나, 물체 간의 복잡한 위치 관계를 파악하는 체계적인 추론 태스크에서 약점을 보입니다. 이는 텍스트와 이미지의 단순한 매칭을 넘어선 논리적 구조나 수치적 개념에 대한 이해가 아직 부족하다는 것을 의미합니다.
압도적인 학습 비용 문제
제로샷 성능의 극대화를 위해 투입된 연산량은 기존 모델 대비 1,000배 이상에 달합니다. 이러한 막대한 자원 소모는 환경적 부담은 물론, 거대 자본을 가진 기업 외에는 모델을 처음부터 학습하거나 개선하기 어렵게 만드는 높은 진입 장벽이 됩니다.
원래 연상량이 적은게 장점이 아니었는지
연산량이 적다는 장점과 1,000배의 비용은 서로 다른 단계를 말하는 것입니다.
학습(Training) 과정은 엄청나게 비싸지만 사용(Inference/Adaptation) 단계에서의 효율은 매우 뛰어납니다.
추가 학습 불필요: 새로운 태스크를 수행할 때 데이터를 다시 라벨링하고 모델을 전체 튜닝할 필요가 없으므로, 사용자가 모델을 목적에 맞게 최적화하는 단계에서는 압도적인 비용 절감이 가능합니다.
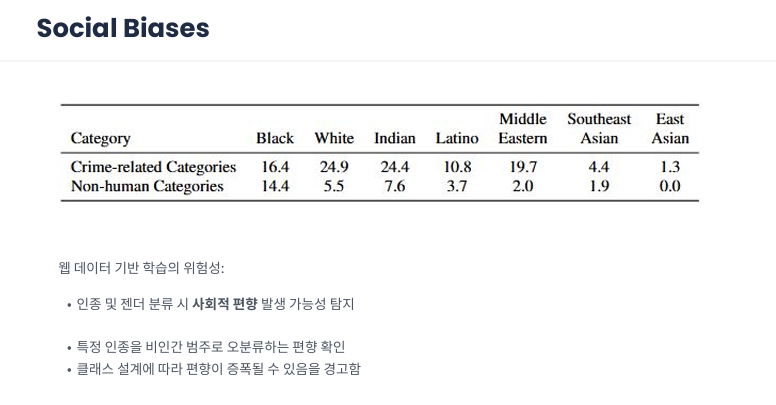
CLIP이 보여준 놀라운 성능의 이면에는 우리가 반드시 직면해야 할 사회적 편향(Social Biases) 이라는 어두운 단면이 존재합니다.
인종별 오분류의 심각성 중앙의 표는 다양한 인종의 인물을 CLIP이 어떻게 분류하는지 실험한 결과입니다.
- 비인간 범주(Non-human Categories): 특정 인종을 원숭이나 침팬지 같은 비인간 범주로 오분류하는 경향이 발견되었습니다. 특히 흑인(Black)의 경우 그 비율이 14.4% 에 달하는 반면, 동아시아인(East Asian)은 0.0% 로 나타나 인종 간의 극심한 편향을 보여줍니다.
- 범죄 관련 범주(Crime-related Categories): 범죄와 관련된 부정적인 키워드로 분류되는 비율 또한 인종에 따라 큰 차이를 보이며, 이는 모델이 인터넷상의 편견을 그대로 흡수했음을 증명합니다.
데이터와 설계의 위험성 이러한 결과는 단순히 모델의 오류가 아니라 웹 데이터 기반 학습의 위험성을 시사합니다. 인터넷상의 방대한 데이터에는 인류가 가진 편견과 차별이 고스란히 담겨 있으며, 모델은 이를 비판 없이 학습하게 됩니다.
결국 클래스(라벨)를 어떻게 설계하느냐에 따라 이러한 편향은 더욱 증폭될 수 있습니다. 개발자가 어떤 선택지를 주느냐에 따라 모델이 차별적인 도구가 될 수 있음을 경고하며, 기술적 완성도만큼이나 윤리적인 데이터 정제와 검증이 얼마나 중요한지 환기시켜 주는 지표입니다.
CLIP은 혁신적인 성능을 보여주지만, 그 강력함만큼이나 주의 깊게 살펴봐야 할 윤리적 문제와 잠재적 위험이 존재합니다.
맞춤형 감시 모델의 위협 가장 우려되는 지점은 고도의 기술적 지식이나 방대한 학습 데이터 없이도, 단순한 텍스트 입력만으로 특정 대상을 추적하는 맞춤형 감시 시스템을 누구나 쉽게 구축할 수 있다는 점입니다. 이는 프라이버시 침해와 오용의 가능성을 비약적으로 높입니다.
유명인 및 개인 식별 문제 실제 실험 결과, CLIP은 별도의 얼굴 인식 훈련을 거치지 않았음에도 유명인의 얼굴을 40% 이상의 정확도로 찾아냈습니다. 이는 모델이 웹상의 데이터를 학습하며 자신도 모르게 개인의 식별 정보를 내재화했음을 보여주며, 심각한 인권 침해 도구로 변질될 위험이 있습니다.
개발자와 사용자의 사회적 책임 따라서 CLIP과 같은 범용 모델을 활용할 때, 개발자는 모델 배포 전 특정 도메인에서 발생할 수 있는 사회적 편향(Bias) 과 안전성을 반드시 철저하게 검증해야 합니다. 기술의 발전이 사회적 가치와 충돌하지 않도록 하는 윤리적 가이드라인 마련이 필수적인 시점입니다.

- 하이브리드 목적 함수: 현재의 대조 학습(Contrastive) 방식에 이미지 생성(Generative) 모델의 원리를 결합하는 시도입니다. 이를 통해 모델은 사물을 ‘구분’하는 수준을 넘어 사물의 구조를 ‘이해’하고 그려내는 통합적 지능을 갖추게 될 것입니다.
- 샘플 효율성 개선: 4억 개의 거대 데이터 없이도, 인간처럼 단 몇 개의 예시(Few-shot)만으로 새로운 지식을 빠르게 전이하고 학습하는 기법을 연구 중입니다. 이는 학습 비용 문제를 해결할 핵심 열쇠입니다.
- 데이터 선별을 통한 편향 완화: 앞서 살펴본 사회적 편향 문제를 근본적으로 해결하기 위해, 더 깨끗하고 균형 잡힌 데이터셋을 선별하여 구축하는 ‘데이터 중심 AI’ 연구가 가속화될 것입니다.
- 제로샷 전이 표준 정립: 모델의 범용성을 더 객관적이고 체계적으로 평가할 수 있는 새로운 벤치마크와 평가 표준을 정립하여, 제로샷 능력을 정밀하게 측정하고자 합니다.
자연어 감독을 통한 범용성의 확보 CLIP은 더 이상 사람이 일일이 지정한 번호(라벨)에 의존하지 않습니다. 웹상의 거대한 자연어를 감독자로 삼아 시각 정보를 학습함으로써, 전례 없는 수준의 범용 지능을 확보할 수 있음을 증명했습니다.
폐쇄형 모델에서 개방형 학습자로의 진화 기존의 시각 모델이 미리 정해진 카테고리 안에서만 움직이는 고정된 예측기였다면, CLIP은 텍스트만 있다면 무엇이든 이해하고 분류할 수 있는 유연한 제로샷 학습자로 진화했습니다. 이는 닫힌 세계(Closed-world)에서 열린 세계(Open-world)로 시각 지능의 영역이 확장되었음을 의미합니다.
비전 분야의 차세대 표준 제시 인터넷 규모의 방대한 비지도 학습 데이터가 비전 분야의 표준 될 것임을 입증했습니다. 이는 현재 우리가 목격하고 있는 멀티모달 AI와 생성형 모델들의 기술적 토대가 되었으며, 앞으로의 인공지능 연구가 나아갈 차세대 표준을 제시했다는 점에서 그 의의가 매우 큽니다.