[머신러닝] 3-1. k-최근접 이웃 회귀
지도학습의 한 종류인 회귀 문제를 이해하고 k-최근접 이웃 알고리즘을 사용해 농어의 무게를 예측하는 프로그램 만들기
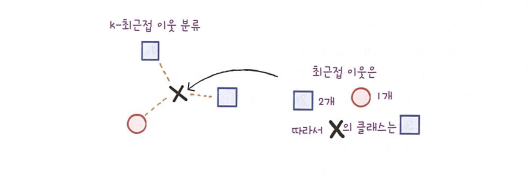
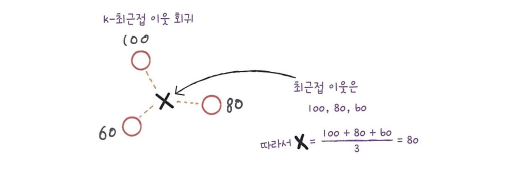
k-최근접 이웃 회귀
지도학습 알고리즘: 분류, 회귀
분류는 샘플을 몇 개의 클래스 중에서 하나로 분류하는 것이다.
회귀는 임의의 어떤 숫자를 예측하는 것이다. 정해진 클래스가 없고 임의의 수를 예측하는 것이다. 두 변수 사이에 상관관계를 예측하는 방법이다.
데이터 준비
사이킷런에 사용할 훈련 세트는 2차원 배열이어야 한다. 2차원 배열로 나타내기 위해 하나의 열을 추가했다. 배열을 나타내는 방법이 달라진 것이지 원소의 개수가 달라지진 않았다

특성이 하나이기 때문에 수동으로 2차원 배열으로 만들어야 한다. 넘파이의 reshape()를 사용하면 된다. reshape()로 배열의 크기를 지정할 수 있다.
1
2
3
test_array=np.array([1,2,3,4])
print(test_array.shape)
#(4,)
(4,)배열을 (2,2)로 바꾸기
1
2
3
test_array=test_array.reshape(2,2)
print(test_array.shape)
#(2,2)
reshape( )에서 원소의 개수가 다르면 에러가 발생한다. {: .prompt-tip }
넘파이에서 배열의 크기를 자동으로 지정할 수도 있다. 크기에 -1을 넣으면 나머지 원소의 개수로 모두 채우게 된다. 이렇게 하면 전체 원소의 개수를 외우지 않아도 돼서 편하다
1
2
3
4
train_input=train_input.reshape(-1,1)
test_input=test_input.reshape(-1,1)
print(train_input.shape, test_input.shape)
#(42,1) (14,1)
결정계수 \(R^2\)
1
2
3
4
5
6
7
8
9
from sk.learn import KNeighborsRegressor
knr=KNeighborsRegressor()#객체 생성
knr.fit(train_input, train_target)#k-최근접 이웃 회귀 모델 훈련
print(knr.score(test_input, test_target))#테스트 세트 점수 확인
#0.99280
| 분류에서 score | 회귀에서 score |
|---|---|
| 테스트 세트에 있는 샘플을 정확하게 분류한 개수의 비율(정확도) | 모델로 만들어진 회귀식이 얼마나 잘 예측하는지 |
회귀에서 정확한 숫자를 맞힌다는 것은 거의 불가능! 예측하는 값이나 타깃 모두 임의의 수치이기 때문
회귀에서 점수를 결정 계수(\(R^2\))라고 부른다.
계산 방법 \(R^2\) =1-\((타깃-예측)^2\)/\((타깃-평균)^2\)
R^2=1-((타깃-예측)^2/(타깃-평균)^2)
만약 타깃의 평균 정도를 예측하는 수준! 즉, 전혀 예측을 못한다면 결정계수는 0에 가까워지고 타깃이 예측에 아주 가까워지면 1에 가까운 값이 된다.
mean_absolute_error는 타깃과 예측의 절댓값 오차를 평균하여 반환한다.
1
2
3
4
5
6
7
8
9
10
from sklearn.metics import mean_absolute_error
#테스트 세트에 대한 예측
test_prediction=knr.predict(test_input)
#테스트 세트에 대한 평균 절댓값 오차를 계산한다.
mae=mean_absolute_error(test_target, test_prediction)
print(mae)
#19.157
평균적으로 19g 정도 타깃값이 다르다. 지금까지는 훈련 세트를 사용해 모델을 훈련하고 테스트 세트로 모델을 평가했다. 그런데 만약 훈련 세트를 사용해 평가한다면?
과대적합 vs 과소 적합
1
2
3
4
5
6
7
8
9
10
11
12
from sk.learn import KNeighborsRegressor
#객체 생성
knr=KNeighborsRegressor()
#k-최근접 이웃 회귀 모델 훈련
knr.fit(train_input, train_target)
#테스트 세트 점수 확인
print(knr.score(test_input, test_target))
#0.99280
1
2
3
print(knr.score(train_input, train_target))
#0.96882
훈련 세트에서 모델을 훈련했으니 훈련 세트에서 더 좋은 점수가 나와야 한다.
어랏?? 왜 훈련 세트보다 테스트 세트의 점수가 높지?
과소적합이다.
| 과대적합 | 과소적합 |
|---|---|
| 훈련 세트에서 점수가 좋았는데 테스트 세트에서 점수가 나쁘다 | 훈련 세트<테스트 세트 점수 or 두 점수 모두 낮다 |
| 훈련세트에만 잘 맞는 모델, 실전에 투입하면 잘 동작하지 않는다 | 모델이 너무 단순하여 훈련 세트에 적절히 훈련되지 않은 경우이다. 훈련 세트가 전체 데이터를 대표한다고 가정하기 때문에 훈련 세트를 잘 학습하는 것이 중요하다 |
왜 과소적합이 일어날까?
훈련 세트와 테스트 세트의 크기가 매우 작기 때문이다. 데이터가 작으면 테스트 세트가 훈련 세트의 특징을 따르지 못할 수 있다.
어떻게 해결할까? 모델을 좀 더 복잡하게 만들면 된다. 훈련 세트에 더 잘 맞게 만들면 되는 것이다.
k-최근접 이웃 알고리즘으로 모델을 더 복잡하게 만드는 방법은 이웃의 개수 k를 줄이는 것이다.
이웃의 개수를 줄인다 -> 훈련 세트에 있는 제한된 패턴에 민감해진다.
이웃의 개수를 늘린다 -> 데이터 전반에 있는 일반적인 패턴을 따른다.
이웃의 개수를 줄여서 과소적합 문제를 해결할 수 있다.
마무리
키워드
회귀 k-최근접 이웃 회귀 결정계수(R^2) 과대적합 과소적합
핵심 패키지와 함수
scikit-learn
KNeighborsRegressor mean_absolute_error()
numpy
reshape()
참고: 혼자 공부하는 머신러닝+딥러닝