[머신러닝] 3-2. 선형회귀
k-최근접 이웃 회귀와 선형 회귀 알고리즘의 차이를 이해하고 사이킷런을 사용해 여러 가지 성형 회귀 모델을 만들기
k-최근접 이웃의 한계
혼공머신의 모델을 사용해 50cm 농어의 무게를 예측해보자
1
2
print(knr.predict([[50]]))
#[1033.3333]
1033g 정도로 예측한다. 그런데 실제로는 이보다 훨씬 많이 나간다
무엇이 문제일까?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
improt matplotlib.pyplot as plt
#50cm 농어의 이웃을 구하자
distances, indexes = knr.kneighbors([[50]])
#훈련 세트의 산점도를 그리자
plt.scatter(train_input, train_target)
#훈련 세트 중에서 이웃 샘플만 다시 그리자
plt.scatter(train_input[indexes], train_target[indexes], marker'D')
#50cm 농어 데이터
plt.scatter(50, 1033, marker='^')
plt.show
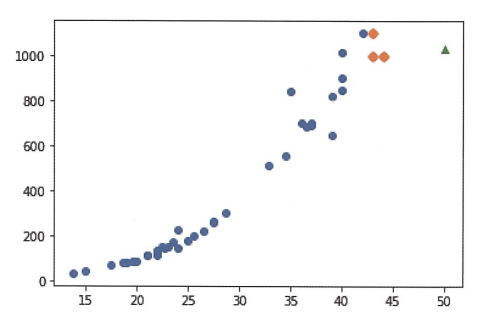
아하! 길이가 커질수록 농어의 무게가 증가한다. 그런데 50cm 농어에서 가장 가까운 것은 45cm 이기 때문에 k-최근접 이웃 알고리즘은 이 샘플들의 무게를 평균한다.
새로운 샘플이 훈련 세트 범위에서 벗어나 제대로 예측되지 않았던 것이다!
그렇다면 다른 알고리즘을 찾아보자
선형회귀
선형회귀는 널리 사용되는 회귀 알고리즘이다. 비교적 간단하고 성능이 뛰어나다
선형적이라는 말을 기억하는가? 선형회귀는 특성이 하나인 경우 어떤 직선을 학습하는 알고리즘이다.
1
2
3
4
5
6
7
8
9
10
from sklearn.linear_model import LinearRegression
lr=LinearRegression()
#선형회귀 모델 훈련
lr.fit(train_input, train_target)
#50cm 농어에 대해 예측하기
print(lr.predict([[50]]))
#[1241.83]
k-최근접 이웃 회귀와 달리 무게를 높게 예측했다.
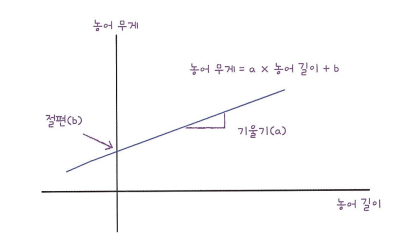
LinearRegression 클래스가 이 데이터에 가장 잘 맞는 a, b를 찾아냈다.
이 a,b는 lr 객체의 coef_ 와 intercept_ 속성에 저장되어 있다.
1
2
3
print(lr.coef_, lr.intercept_)
#[39,017] -709.0186
머신러닝에서 기울기를 계수(coefficient) 또는 가중치(weight) 라고 부른다
coef_ 와 intercept_를 머신러닝 알고리즘이 찾은 값이라는 의미로
모델 파라미터라고 부른다. 알고리즘의 훈련 과정은 최적의 모델 파라미터를 찾는 것이다. 이를모델 기반 학습이라고 부른다.
k-최근접 이웃에는 모델 파라미터가 없다. 훈련 세트를 저장하는 것이 훈련의 전부였다. 이를사례 기반 학습이라고 한다.
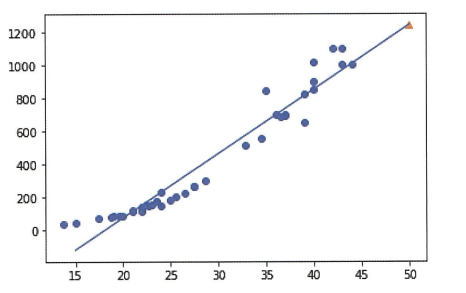
선형 회귀 알고리즘이 데이터셋에서 찾은 최적의 직선이다. 길이가 50cm인 농어에 대한 예측은 이 직선의 연장선에 있다.
이렇게 훈련 세트의 범위를 벗어난 농어의 무게도 예측할 수 있다. 이번에도 결정계수 (\(R^2\)) 점수를 확인해 보자.
1
2
3
4
5
#훈련 세트(0.939)
print(lr.score(train_input, train_target))
#테스트 세트(0.824)
print(lr.score(test_input, test_target))
점수 차이가 조금 난다. 과대적합인가? 으음 훈련 세트의 점수가 높지는 않다. 오히려 과소 적합이다.
또다른 문제도 있다. 왼쪽 아래를 보자 잘 안 맞는 듯 하다…! 이렇게 예측하면 농어의 무게가 0g 이하로 내려가게 될 것이다. 현실에서 있을 수 없는 일이다!
다항회귀
농어의 길이와 무게에 대한 산점도를 보면 일직선보다는 구부러진 곡선이다. 그러면 어떻게 최적의 곡선을 찾을까?
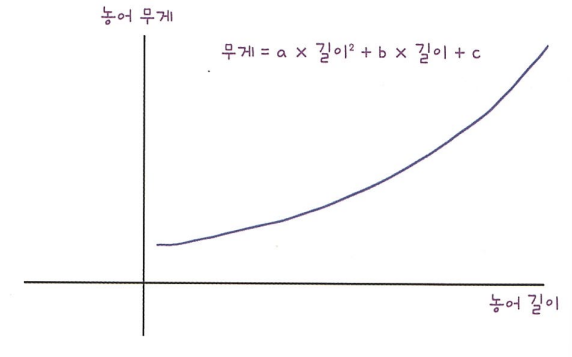
이렇게 2차 방정식 그래프로 그리려면 길이를 제곱한 항이 훈련 세트에 추가돼야 한다. 넘파이를 또 사용해보자!
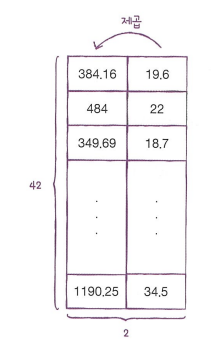
column_stack()을 활용하자
1
2
3
4
train_poly=np.column_stack((train_inpur**2, train_input))
test_poly=np.column_stack((test_input**2, test_input))
2차 방정식 그래프를 찾기 위해 훈련 세트에 제곱항을 추가했지만 타깃값은 그대로 사용한다. 목표하는 값은 어떤 그래프를 훈련하든지 바꿀 필요가 없기 때문이다.
예측할 때 모델에 농어 길이의 제곱와 원래 길이를 함께 넣어야 함을 잊지 말자
1
2
3
4
5
6
lr=LinearRegression()
lr.fit(train_poly, train_target)
print(lr.predict([[50**2, 50]]))
#[1573.98]
1
2
3
print(lr.coef_, lr.intercept_)
#[1.04 - 21.55] 116.05
무게=1.01 x 길이^2 - 21.6 x 길이 +116.05
으음 2차 방정식은 비선형 아닌가?
2차 방정식도 선형회귀이다. 길이^2를 왕길이로 바꿔서 쓸 수 있기 때문이다.
무게=1.01 x 왕길이 - 21.6 x 길이 +116.05
이렇게 선형 관계로 표현할 수 있다
이런 방정식을 다항식이라 하고 다항식(polynomial)을 사용한 선형 회귀를 다항 회귀(polynomial regression)라 한다.
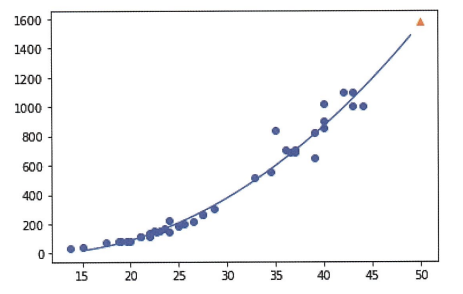
훈련 세트의 경향을 잘 따르고 있다. 이제 무게가 음수로 나오는 일도 없다!
테스트 세트의 결정계수 (\(R^2\)) 점수를 확인해 보자.
1
2
3
print(lr.score(train_poly, train_target)) #0.9706
print(lr.score(test_poly, test_target)) #0.9775
약간의 과소적합이 아직 남아있다. 조금 더 복잡한 모델을 찾아보도록 하자
마무리
키워드
선형회귀 계수 가중치 모델 파라미터 다항 회귀
핵심 패키지와 함수
scikit-learn
LinearRegression
참고: 혼자 공부하는 머신러닝+딥러닝