[머신러닝] 4-2. 확률적 경사 하강법
경사 하강법 알고리즘을 이해하고 대량의 데이터에서 분류 모델을 훈련하는 방법을 알아보자
점진적인 학습
이전에 훈련한 모델을 버리고 다시 새로운 모델을 훈련하는 방식! 훈련한 모델을 벌지 않고 새로운 데이터에 대해서만 조금씩 더 훈련할 수는 없을까?
이것은 점진적 학습, 온라인 학습이라고 부른다. 대표적인 점진적 알고리즘은! 확률적 경사 하강법!! 빠밤
확률적 경사 하강법
확률적? 무작위하게, 랜덤하게
경사? 기울기
하강법? 내려가는 방법
확률적 경사하강법은 경사를 따라 내려가는 방법
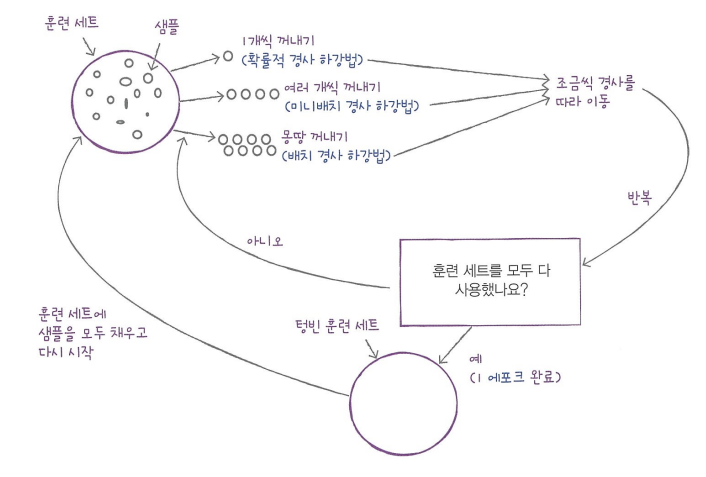
훈련 세트를 사용해 모델을 훈련하기 때문에 경사 하강법도 훈련 세트를 사용하여 가장 가파른 길을 찾을 것이다. 여기서! 전체가 아닌 하나만 골라 가자앙 가파른 길을 찾자! 이렇게 훈련 세트에서 랜덤하게 하나만 고르는 것! 그것이 확률적 경사 하강법이다!!!
랜덤하게 하나씩 샘플을 선택해서 가파른 경사를 조금씩 내려간다. 그 다음 훈련 세트에서 랜덤하게 또 다른 샘플을 하나 선택하여 경사를 또 내려간다. 이렇게 전체 샘플을 모두 사용할 때까지 계속한다
그래도 다 못 내려왔다면? 다시 처음부터..
훈련 세트를 한 번 모두 사용하는 것을 에포크라고 부른다 가혹하지만 일반적으로 경사하강법은 수백 번 이상 에포크를 수행한다.
하나씩 말고 여러개 선택해서 내려가면 어떨까? 그것이 바로 미니 배치 경사 하강법이다
극단적으로 한 번 경사로를 따라 이동하기 위해 전체 샘플을 사용할 수도 있다! 이것은 배치 경사 하강법이다! 안정적이지만 컴퓨터 자원을 많이 사용한다.
손실함수
우리가 내려가려고 하는 산이 손실 함수이다
손실함수는 어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지 측정하는 기준이 된다
이 값이 작을 수록 좋다. 하지만 최솟값은 모른다. 가능한 많이 찾아보고 적당하면 인정해야한느 것이다.
비용함수=손실함수
엄밀히 말하면 손실함수는 샘플 하나에 대한 손실을 정의하고 비용 함수는 훈련 세트에 있는 모든 샘플에 대한 손실함수의 합이다. 하지만 섞어서 사용
분류에서 손실은 확실하다. 4개 중에서 2개만 맞으면 정확도는 0.5이다. 정확도에서 4개 샘플만 있다면 정확도는 5가지 뿐이다!
정확도가 듬성듬성하다면 경사하강법을 이용해 조금씩 움직일 수 없다. 산의 경사면이 연속적이어야 한다. 즉, 손실 함수는 미분 가능해야 한다.
그렇다면 어떻게?? 로지스틱 회귀 모델! 0에서 1사이의 어떤 값도 될 수 있다고 했다
로지스틱 손실 함수
 양성 클래스(타깃=1)일 때 손실은 -log(예측 확률)로 계산한다. 확률이 1에서 멀어질수록 손실은 아주 큰 양수가 된다. 음성 클래스(타깃=0)일 때 손실은 -log(1-예측 확률)로 계산한다. 예측 확률이 0에서 멀어질수록 손실은 아주 큰 양수가 된다
양성 클래스(타깃=1)일 때 손실은 -log(예측 확률)로 계산한다. 확률이 1에서 멀어질수록 손실은 아주 큰 양수가 된다. 음성 클래스(타깃=0)일 때 손실은 -log(1-예측 확률)로 계산한다. 예측 확률이 0에서 멀어질수록 손실은 아주 큰 양수가 된다
이 손실함수를 로지스틱 손실함수,이진 크로스엔트로피 손실 함수라고 부른다. (이진 분류)
다중분류에서 사용하는 손실 함수를 크로스엔트로피 손실 함수라고 부른다.
그럼 회귀에서는 뭘까? 3장에서 나온 평균 절댓값 오차를 사용할 수 있다. 타깃에서 예측을 뺀 절댓값을 모든 샘플에 평균한 값이다! 아니면
평균 제곱 오차를 사용한다. 타깃에서 예측을 뺀 값을 제곱한 다음 모든 샘플에 평균한 값이다. 값이 작을 수록 좋은 모델!
SGDClassifier
1
from sklearn.linear_model import SDGClassifier
사이킷런에서 확률적 경사 하강법을 제공하는 대표적인 분류용 클래스이다.
2개의 매개변수를 지정하고 loss는 손실 함수의 종류를 지정한다. loss=’log’로 지정하여 로지스틱 손실 함수를 지정한다. max_iter는 수행할 에포크 횟수를 지정한다.
1
2
3
4
5
6
7
sc=SGDClassifier(loss='log', max_iter=10, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
#0.773
#0.775
정확도가 낮다. 반복 횟수가 부족했나보다
모델을 이어서 훈련할 때는 partial_fit()을 사용하자
1
2
3
4
5
6
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
#0.813
#0.825
확률적 경사 하강법이 아닌 배치 경사 하강법 아닌가? 아니다! 훈련 세트 전체를 전달했지만 훈련 세트에서 1개씩 샘플을 꺼내서 경사 하강법 단계를 수행한다. SGDClassifier은 미니 배치 경사 하강법이나 배치 하강법을 제공하지 않는다.
에포크와 과대/과소적합
에포크 횟수가 적으면 훈련 세트를 덜 학습한다. 과소적합된 모델일 가능성이 높다
충분히 많으면 완전히 학습한다. 훈련 세트에 너무 잘 맞아 테스트 세트에는 오히려 점수가 나쁜 과대적합된 모델일 가능성이 높다.
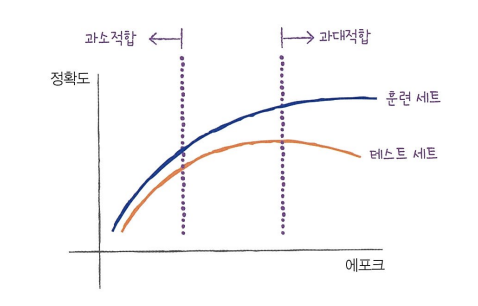
에포크가 진행됨에 따라 모델의 정확도를 나타낸 것이다
과대적합 전에 훈련이 멈추는 것을 조기 종료라고 한다.
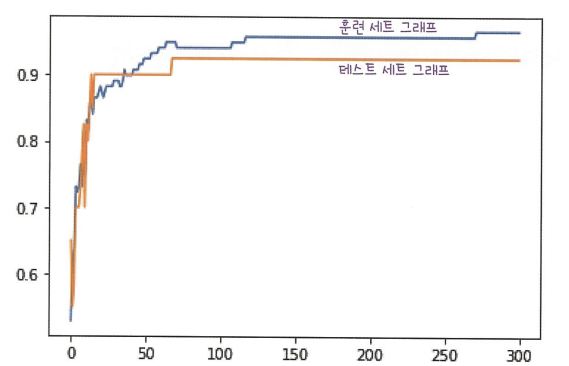
백 번째 에포크 이후에 훈련 세트와 테스트 세트의 점수가 조금씩 벌어지고 있다. 에포크 초기에는 과소적합되어 훈련 세트와 테스트 세트의 점수가 낮다. 백 번째 에포크가 적절해 보인다.
1
2
3
4
5
6
7
sc=SGDClassifier(loss='log', max_iter=100, tol=None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
#0.958
#0.925
일정 에포크 동안 성능이 향상되지 않으면 자동으로 멈춘다. tol 매개 변수에서 향상될 최솟값을 정한다. None으로 지정하여 멈추지 않고 max_iter=100만큼 무조건 반복!
아주 점수가 좋다! 성공!!
SGDRegressor: 확률적 경사 하강법을 사용한 회귀 알고리즘 제공
loss 매개변수 기본값은 hinge이다. 힌지 손실은 서포트 벡터 머신이라 불리는 또 다른 머신러닝 알고리즘을 위한 손실함수이다. 서포트 벡터 머신이 널리 사용되는 머신러닝 알고리즘 중 하나다. SGDClassifier가 여러 종류의 손실 함수를 loss 매개 변수에 지정하여 다양한 머신 러닝 알고리즘을 지원한다.
마무리
키워드
확률적 경사 하강법 손실함수 에포크
핵심 패키지와 함수
scikit-learn
SGDClassifier SGDRegressor
참고: 혼자 공부하는 머신러닝+딥러닝