[논문정리] Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, Pieter Abbeel(2020). Denoising Diffusion Probabilistic Models . arXiv.
abstract
비평형 열역학에서 영감을 받은 변수 모델인 확산 확률 모델을 사용하여 고품질 이미지 합성 결과를 제시한다. 확산 확률 모델과 랑주뱅 동역학을 이용한 노이즈 제거 점수 매칭 간의 새로운 연관성을 기반으로 설계된 가중치 변분 경계를 사용하여 학습함으로써 최상의 결과를 얻울 수 있었다. 이 모델은 자기 회귀 디코딩의 일반화로 해석될 수 있는 점진적 손실 감압 방식을 자연스럽게 수용한다.
CIFAR10 데이터셋에서 Inception 점수는 9.46, FID 점수는 3.17을 기록했다. 256X256 LSUN에서 Progressive GAN 과 유사한 샘플 품질을 얻었다.
Diffusion Probabilistic Models (Diffusion Models): 데이터에 점진적으로 가우시안 노이즈를 추가하는 순방향 과정(forward process)과 이 과정을 역전시키도록 학습된 마르코프 체인(Markov chain)을 사용하는 생성 모델
점진적 손실 감압 방식 (Progressive Lossy Compression): 점진적으로 노이즈를 추가하여 정보를 손상시키는 과정과 이 손상된 정보로 원본 데이터를 복원하는 과정을 학습하는 방식
가중 변분 경계 (Weighted Variational Bound): 목적함수. 실제 데이터의 복잡한 확률 분포를 직접 계산하는 대신 계산 가능한 하한선(Evidence lower bound, ELBO)을 설정한다. 이를 최대화 하여 모델을 학습시킨다. 여기에 가중치를 부여하여 원본 복원 품질과 잠재 공간의 정규화 사이의 균형을 조절하는 방식을 가중변분 경계라고 한다.
변분: 어떤 함수의 형태를 조금씩 변화시키면서 그 결과가 최적이 되는 조건을 찾는 방법
변분경계 (ELBO) 목표: 실제 데이터 x의 복잡하고 계산 불가능한 확률 분포를 직접 최대화하는 대신 계산이 가능한 하한선(Lower Bound)인 ELBO (Evidence Lower BOund)를 설정하고 이를 최대화.
랑주뱅 동역학(Langevin Dynamics): 물리학에서 입자의 무작위적 움직임을 설명하는 방정식. 머신러닝에서 이 원리를 샘플링 기법에 응용한다. 특정 확률 분포에서 데이터를 생성할 때 밀도가 높은 방향으로 이동시키면서 적절한 노이즈를 추가하는 과정을 반복하여 원하는 분포의 샘플을 얻는다.
비평형 열역학 (Non-equilibrium Thermodynamics): 시스템이 열역학적 평형(안정된) 상태에 있지 않을때 에너지 흐름을 다루는 물리학. DPM은 이 개념에 이론적 기반을 둔다. 데이터를 평형상태로 노이즈를 비평형 상태로 보고 데이터가 노이즈로 변하는 과정과 노이즈에서 데이터를 보원하는 과정을 열역학적 흐름으로 모델링한다.
LSUN (Large-scale Scene Understanding): 대규모 장면 이해를 위한 데이터셋이다. 다양한 장소와 카테고리별로 수배만장의 이미지를 제공한다.
1. Introduction

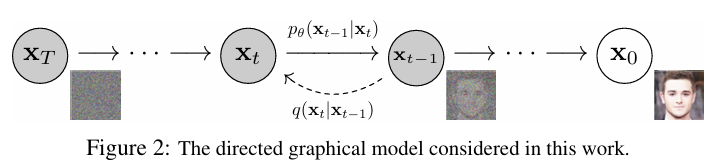
Diffusion model은 Markov chain을 매개변수화 해서 훈련시키는 방식이다. 데이터에 점점 노이즈를 추가하는 확산 과정을 역으로 학습해서 최종적으로는 원본 데이터와 일치하는 샘플을 생성한다.
조금씩 노이즈를 추가하면서 데이터를 흐리게 만들고 다시 노이즈를 없애며 깨끗한 이미지를 복원한다.
2. Background
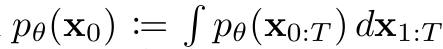
Diffusion model은 위 수식의 latent variable 모델이다.
$x1, ⋯, x_T$는 데이터 $x_0~q(x_0)$와 같은 크기이다.
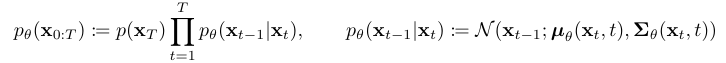
결합 분포 pθ(x{0:T})는 reverse process이다. $p(x_T)=N(x_T;0,I)$ 에서 시작하는 Gaussian transition으로 이루어진 Markov chain으로 정의된다.
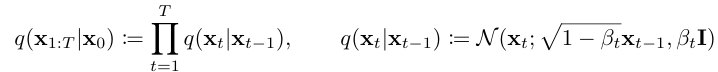 $q(x_{1:T} ∣x_0 )$ : forward diffusion process
$q(x_{1:T} ∣x_0 )$ : forward diffusion process
Diffusion 모델이 다른 latent variable 모델들과 다른 점은 forward process, diffusion process라고 불리는 근사 posterior $q(x_{1:T} ∣x_0)$ 가 고정된 마르코프 체인이다. forward, diffusion process는 variance schedule $β_1,⋯,β_T$에 따라 가우시안 노이즈를 점진적으로 추가한다.
\[\begin{aligned} q (x_{1:T}|x_0) &:= \prod_{t=1}^T q (x_{t}|x_{t-1}) \\ q (x_{t}|x_{t-1}) &:= \mathcal{N} (x_{t} ; \sqrt{1-\beta_t} x_{t-1}, \beta_t I) \end{aligned}\]이미지에 노이즈를 추가하는 forward process는 신경망이 학습하는 것이 아니라 미리 정해둔 규칙으로 자동으로 진행되는 것이다.
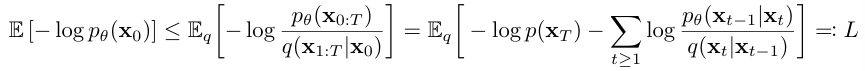
학습은 negative log likelihood 의 variational bound를 최적화하는 것으로 진행된다. log likelihood 계산이 복잡하니 variational bound를 대신 최소화하며 학습하는 것이다.
모델 파라미터 θ 를 조정하면서 모델이 주어진 데이터 $x_0$ 에 대해 최선의 예측을 하도록 한다. variational bound 값을 낮추기 위해 신경망 가중치를 계속 업데이트한다.
forward process의 분산 β_T 는 reparameterization 을 통해 학습하거나 하이퍼 파라미터로 설정할 수 있다.
$β_T$가 충분히 작으면 reverse process와 forward process 가 같은 함수 형태로 everse process의 expressiveness는 $p*θ(x_{t−1}|x_t)$ 에서 가우시안 conditionals를 선택해 부분적으로 보장된다. revese process에서 상태를 예측하는 과정이 수학적으로 잘 정의되고 계산이 간단해지며 모델의 표현력이 어느정도 보장된다.
β_T 가 작으면(한단계에서 조금씩 노이즈 추가) 복잡한 역방향 과정을 간단한 가우시안으로 근사할 수 있어 모델의 표현력을 유지하면서 계산을 쉽게 만든다.
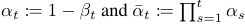
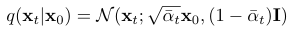
forward process 의 주목할 특징 중 하나는 임의의 시간 t에서 x_t를 특정 수식으로 명확하게 계산할 수 있다.
x_t: forward process에서 t시점의 데이터. 원본 데이터 x_0에 노이즈 추가된 상태
임의의 시점 t의 x_t를 x_0와 t를 이용해 명확한 수식으로 바로 계산할 수 있다. 효율성을 극대화한다.
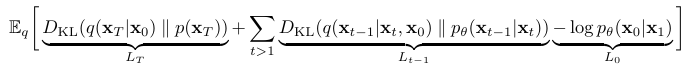
모델 훈련은 L 을 stochastic gradient descent로 최적화하면서 이루어진다. L을 다시 쓰면 분산을 줄여 개선할 수 있다.
| KL Divergence로 $pθ(x{t-1} | x_t)$와 forward process의 posteriors(사후확률)를 비교한다. |
Diffusion model이 어떻게 안정적이고 노이즈 제거 능력을 학습하는지. 최적화 방법과 학습 목표
KL Divergence: 두 확률 분포가 서로 얼마나 다른지 측정하는 척도. 모델 예측과 수학적인 정답 사이의 차이를 계산하는데 사용된다. 값을 최소화해 모델이 노이즈 제거 과정을 정확하게 학습하도록 한다.
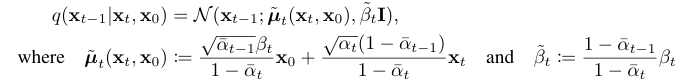
두 가우시안 분포에 대한 KL Divergence는 closed form으로 된 Rao-Blackwellized 방식으로 계산할 수 있다. $q(x{t−1}|x_t)$는 계산하기 어렵지만 $q(x{t−1}|x_t,x_0)$는 쉽게 계산할 수 있다.
계산 복잡도를 낮추고 학습할 정답을 단순화하는 수학적 특성
Rao-balckwellized: 기댓값의 variance를 줄여서 추정 정확도를 높이는 수학적 기법. 손실함수의 분산이 크면 학습이 불안정하다. 이 수식을 적용해 예측 오차 기반의 단순한 형태로 재구성해 분산을 줄여 모델을 빠르고 안정적으로 만든다.
3. Diffusionmodelsanddenoisingautoencoders
데이터를 노이즈로 바꾸는 순방향 과정에서 노이즈를 얼마나 점진적으로 추가할지 β*T를 결정해야 한다. 노이즈에서 이미지를 복원하는 역방향 과정을 수행할 신경망의 구조와 노이즈 제거 과정 p_θ에서 사용하는 가우시안 분포의 모수를 어떻게 예측하게 할지 선택해야 한다.
선택의 기준을 제시하기 위해 확산 모델과 Denoising Score Matching이라는 다른 분야의 모델 사이에 새로운 수학적 연관성을 확립했다.
Denoising Score Matching: 잡음이 섞인 데이터에서 잡음ϵ을 정확하게 예측하도록 학습하는 손실 함수
Forward process L_T
forward process의 분산 β_t을 상수로 고정할 것이기 때문에 approximate posterior q에는 학습되는 파라미터가 없다. 따라서 학습 중에 L_T는 상수이므로 무시 가능하다.
Reverse process L_{1:T-1}
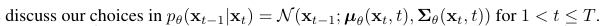
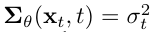
σ_t 는 학습하지 않는 t에 의존하는 상수이다.
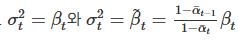
이렇게 두어도 비슷한 결과가 나온다.
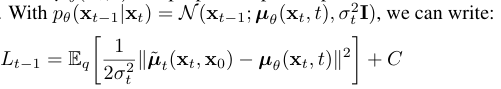
$μ_θ(x_t,t)$를 나타내기 위해 특정 parameterization을 제안한다.

C는 θ에 독립적인 상수다. μ_θ의 가장 간단한 parameterization은 forward process 사후 평균이다. $L_{t-1}$은 ground truth에 가까워지도록 학습한다.
ϵ_θ 는 x_t로 부터 ϵ를 예측하는 function approximator이다.


이는 t에 의해 인덱싱 되는 multiple noise scales에 걸친 enoising score matching과 유사하다. 12가 langvein 윳 역과정에 대한 Variational Bound의 한 항과 같으므로 denoising score matching과 유사한 목적함수를 최적화하는 것이 Lagvin dynamics 와 유사한 샘플링 체인의 유한 시간 분포에 맞추기 위한 변분 추론과 동일하다.
diffusion model의 reverse process 평균을 예측하는 parameterization. μ_θ를 직접 예측하는 대신 잡음 ϵ을 예측하는 ϵ_θ 를 사용하는 파라미터화가 Langevin dynamics와 유사하고 vaiational bound가 denoising score matching과 유사한 목적 함수로 단순화 된다.
Datascaling, reverse process decoder,and L_0
이미지는 0에서 255 사이의 값이고 -1 부터 1까지 실수로 선형적으로 스케일링되어 주어진다. reverse process가 이를 통해 표준정규 standard normal prior p(x_T)에서 시작해 스케일링된 이미지로 갈 수 있게 한다. discrete log likelihood를 얻기 위해 reverse process의 마지막 항 L_0 을 가우시안 분포에서 나온 독립적인 discrete decoder로 설정했다.
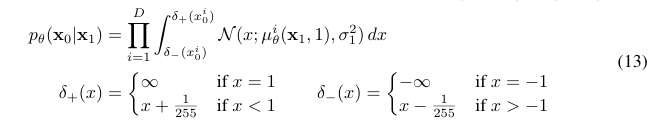
D는 데이터의 fimensionality이고 i는 각 좌표이다.
Simplified training objective
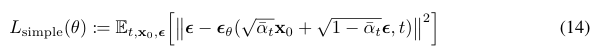
최종적으로 단순화된 training objective를 제안한다.
이 목표 함수는 이론적으로 vaiational bound에 포함된 복잡한 가중치 항들을 제거한 형태다. 이 단순화된 목표 함수를 사용했을 때 샘플 품질이 오히려 크게 향상된다. 이론적 목적 함수(12)에 포함된 가중치 항 $β²_t / (2σ²_t α_t (1-ᾱ_t))$은 t가 작을 때(잡음이 적을 때) 더 큰 값을 가진다. 이 가중치를 제거함으로써 Lsimple은 모든 t를 동등하게 취급하게 되고 결과적으로 t가 큰(잡음이 많은) 어려운 잡음 제거 작업에 상대적으로 더 많은 가중치를 부여하여 모델이 전체적인 생성 품질을 향상시키도록 유도합니다. 전체 훈련 절차는 알고리즘 1에 있다.
가중치를 제거했는데 왜 다시 가중치 부여라는 말이 나오는가?
이론적 variational bound의 각 시간 단계 손실 항 L_t는 (12) 와 같은 식을 가진다. 앞에 붙은 복잡한 가중치 항은 t가 작을 때(잡음이 적을 때)값이 커진다. 때문에 모델이 어려운 작업보다 쉬운 작업에 과하게 집중하게 한다.
단순화된 목적 함수는 위에 가중치 항을 제거하고 단순히 잡음 오차만 사용한다. 수학적으로 모든 시간 단계 t에 대해 손실을 동일하게 취급한다. 하면 작은 t의 영향력은 작아지고 큰 t의 영향력은 상대적으로 커진다.
가중치 항을 제거한 것은 작은 t에 대한 과도한 가중치를 없애는 것으로 결과적으로 큰 t에 대한 상대적인 가중치 부여 효과를 낳아 모델의 전반적인 생성 품질을 향상시킨다.
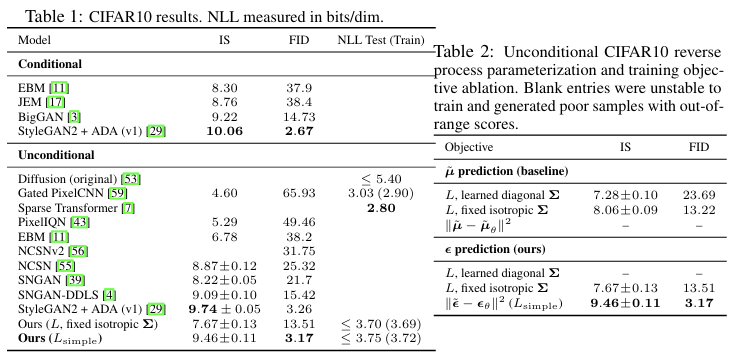
NLL (Negative Log Likelihood) (Test/Train): 모델이 데이터 분포를 얼마나 잘 학습했는지를 측정. 낮을수록 좋다
conditional: 특정 조건을 받아 그 조건에 맞는 이미지 생성
unconditional: 아무 조건 없이 자체적으로 다양한 이미지 생성
Fixed Isotropic Σ: 분산Σ을 고정된 상수값으로
Learned Diagonal Σ: 분산을 신경망마다 직접 학습하도록.
파라미터화의 중요성: 역과정 평균을 직접 예측하는 것보다 잡음을 예측하는 파라미터화가 더 안정적이고 우수한 성능을 보인다.
L_simple의 효과: 이론적인 변분 경계 L를 사용하는 대신 복잡한 가중치를 제거한 단순화된 목적 함수 L_simple을 사용하는 것이 FID를 13.51에서 3.17로 급격히 개선시키며 샘플 품질을 향상시킨다.
4. Experiments
실험 setting
모든 실험에서 T=1000을 설정하여 샘플링 중 필요한 신경망 평가 횟수가 이전 연구와 일치하도록 했다.
순방향 process 분산β_t을 로 선형적으로 증가하는 상수로 설정했다.
x_T에서 signal-to-noise-ratio는 최대한 작게
forward process를 통해 테이터 x_0 에 잡음이 점진적으로 추가되어 최종 상태인 x_T가 된다.
신경망은 group normalization을 사용하는 U-Net backbone
group normalization: 특징 맵(Feature Map)의 채널(Channel)을 여러 그룹으로 나눠 각 그룹 내에서 평균과 분산을 계산하여 정규화하는 기법.
U-Net backbone: 데이터를 압축(인코딩)하고 다시 복원(디코딩)하는 구조를 대칭적으로 연결하고 스킵 연결(Skip Connections)을 포함한 신경망 아키텍처
Transformer sinusoidal position embedding으로 모델에게 시간 t를 입력
Transformer sinusoidal position embedding: 시간 t와 같은 순서나 위치 정보를 모델이 이해할 수 있도록 사인(sin) 및 코사인(cos) 함수를 사용하여 고차원 벡터로 변환하는 인코딩 기법.
16x16 feature map에서 self-attention 사용
Self-Attention: 모델이 이미지의 한 부분(픽셀)을 처리할 때, 이미지의 다른 모든 부분과의 관계(가중치)를 학습하여 정보를 통합하는 메커니즘.
sample quality

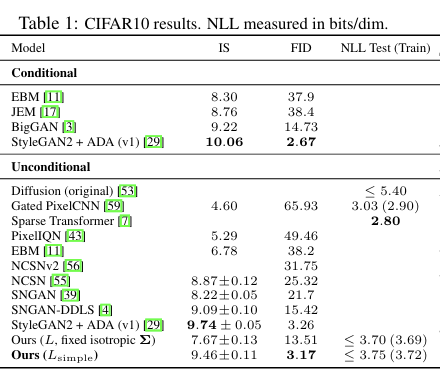
CIFAR10. FID 점수 3.17로 unconditional 모델은 더 나은 샘플 품질이다. 나와 있는 대부분의 모델, 클래스 conditional 모델을 포함한다. 단순화된 loss function은 복잡한 loss function 보다 NLL이 높지만 FID에서 앞선다.
Reverse process parameterization and training objective ablation
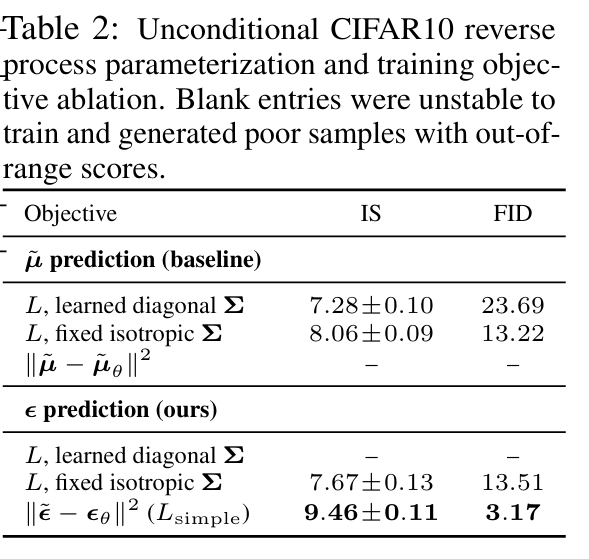
역방향 프로세스 분산을 학습하면 학습이 불안정해지고 고정된 분산에 비해 표본 품질이 저하된다.
고정된 분산을 사용하여 variational bound에서 학습했을 때 µ를 예측하는 것과 거의 같은 성능을 보이지만 단순화된 목표에서 학습했을 때는 훨씬 더 나은 성능 을 보인다.
progressive generation

t가 클 때 (초기 단계): reverse process가 처음 시작될 때는 큰 스케일의 이미지 특징이나 전반적인 형태만 나타난다.
t가 작을 때 (후기 단계): reverse process가 진행되면서 미세한 디테일과 세부적인 특징이 점차 추가되고 명확해진다.
fig6 원본 이미지가 어떻게 변화하는지 보여준다. 왼쪽부터 오른쪽으로 갈수록 시간 t가 감소하며 처음에는 노이즈에 가깝던 이미지가 점차 선명한 객체로 복원되는 과정을 시각화한다.
fig7 상단/하단 좌측 이미지: 잠재 변수 x_t에 조건을 걸어 생성된 이미지 x_0 샘플. 하단 우측 이미지: x_t
잠재 변수를 공유하는 샘플들이 얼굴의 포즈, 표정, 머리 모양과 같은 고수준 속성을 공유하고 있다. 잠재 공간에서 이미지의 특징이 잘 인코딩되어 있다.
5. Conclusion
diffusion model에서 발전된 DDPM 모델 제안한다. 기존 Diffusion Loss에서 Regularization Loss와 Reconstruction Loss를 제거하고 Denoising Process Loss를 재구성한다. 각 시점의 다양한 scale의 gaussian noise를 예측하는 Loss로 단순화시키면서 성능을 향상시킨다.