[논문정리] CAVIA: CAMERA-CONTROLLABLE MULTI-VIEW VIDEO : DIFFUSION WITH VIEW-INTEGRATED ATTENTION
Dejia Xu, Yifan Jiang, Chen Huang, Liangchen Song, Thorsten Gernoth, Liangliang Cao, Zhangyang Wang, Hao Tang University of Texas at Austin (2024.10.14)| Apple | Google . CAVIA: CAMERA-CONTROLLABLE MULTI-VIEW VIDEO : DIFFUSION WITH VIEW-INTEGRATED ATTENTION
카메라제어 가능한 다중 뷰 비디오 생성을 위한 프레임 워크 cavia
기존 확산 모델의 3D일관성 및 카메라 제어 한계를 극복하기 위해 View-integrated attention 모듈을 도입해 시점 및 시간적 일관성을 크게 향상 시킨다. 유연한 학습 전략으로 복잡한 장면에서도 사실적인 객체 움직임과 배경 보존을 한다. 사용자가 원하는 카메라 움직임을 정밀하게 지정해 공간-시각적으로 일관된 다중 비디오를 생성할 수 있도록 한다. 3D 재구성, 고품질 비디오 생성에 새로운 가능성을 제시한다. 정밀한 카메라 제어가 필요한 콘텐츠 제작자에게 실질적인 해결책 제안이 기대된다
1. CAVIA: 카메라 제어 가능한 다중 뷰 확산 모델
기존 비디오 생성 모델의 한계 및 CAVIA의 등장 배경
최근 확산 모델의 급속한 발전으로 이미지 비디오 생성 모델에서 상당한 진전이 있었다. 초기 연구들은 비디오 모델을 처음부터 훈련시키거나 사전 훈련된 이미지 생성 모델에 시간적 레이어를 추가하여 미세 조정하는 방식이었다. 생성된 비디오는 정확한 3D 일관성이 부족하거나 객체 움직임이 거의 없는 경우가 많았다.
이에 생성 과정에 카메라 제어를 통합하려고 시도했으나 단순한 움직임에 제한되었다. 서로 다른 카메라 궤적에서 동일한 장면에 대한 다중 뷰 일관성 비디오를 생성하는 데는 한계가 있다! 여러 시퀀스를 독립적으로 샘플링하면 장면의 일관성이 크게 떨어진다. 때문에 여러 비디오 시퀀스를 동시에! 생성하는 것이 바람직하다. 하지만 다중 뷰 비디오 데이터가 부족하여 다중 뷰 생성이 일관성 없는 거의 정적인 장면이나 합성 객체에 국한되는 문제가 존재한다.
그래서 CAVIA! 이러한 한계를 해결하기 위해 CAVIA는 카메라 제어 가능한 다중 뷰 비디오 생성을 위한 새로운 프레임워크를 도입했다 입력 이미지를 여러개의 시공간적으로 일관된 비디오로 변환한다. 사용자가 객체 움직임을 얻으면서 카메라 움직임을 정밀하게 지정할 수 있는 최초의 프레임워크다.
2. 관련 연구 및 CAVIA의 차별점
최근 생성된 프레임이 뷰포인트 지침을 따르도록 하여 일관성을 개선하기 위해 비디오 생성에 카메라 제어 가능성을 도입하려고 시도했다. 더 나은 조건화 신호, 명시적 3D표현과 같은 기하학적 사전 지식을 활용해 뷰포인트 제어를 강화한다.
조건화 신호: 모델이 생성할때 조건으로 주는 추가 입력, 랜덤으로 생성하는 것이 아닌 원하는 방향으로 결과를 제어하기 위해 주는 정보
기존 방법의 한계
단일 카메라 경로에서 동일한 장면에 대한 여러 일관된 비디오 시퀀스를 생성하는 능력이 제한적이다.
독립적으로 여러 시퀀스를 샘플링하면 장면이 크게 일관되지 않는 경우가 많으므로 여러 비디오 시퀀스를 동시에 생성해야한다. 그러나 실제 다중 뷰 비디오 데이터가 부족하다. 일관성 없는 거의 정적인 장면이나 합성 객체라는 한계가 있다
CVD는 다중 뷰 정적 비디오와 워핑 증강 단안 비디오를 기반으로 하지만 객체 움직임이 있을 때 일관성 없는 결과를 초래하며 제한된 베이스라인으로만 비디오를 생성할 수 있다 다중 뷰 비디오 생성으로 확장하지만 결과는 단순한 카메라 궤적에 국한된다
정적 비디오: 움직임이 거의 없는 장면을 담은 비디오
단안 비디오: 하나의 카메라로 찍은 비디오
해결책
- 단안 비디오 생성기 확장: 단안 비디오 생성기를 확장하여 정확한 카메라 제어로 다중 뷰 일관된 비디오를 생성한다
- 3D 어텐션 모듈: 공간 및 시간 어텐션 모듈을 각각 cross view 3D 어텐션 및 cross frame 3D 어텐션으로 강화하여 뷰포인트와 프레임 모두에서 일관성을 향상시킨다
- 장면 수준 정적 비디오, 객체 수준 합성 다중 뷰 동적 비디오, 실제 단안 동적 비디오를 포함한 다양한 데이터 소스와의 공동 학습을 가능하게 하는 유연한 설계를 한다. 기하학적 일관성, 고품질 객체 움직임 및 배경 보존을 보장한다.
- 뷰 포인트에 대한 보다 정확한 카메라 제어를 위해 뷰 통합 어텐션을 탐색하고 복잡한 장면에서 새로운 뷰성능을 향상시키기 위해 데이터 혼합을 하는 공동 학습을 수행한다
카메라 제어가 가능하고 3D 재구성을 가능하게 하는 다중 뷰 비디오 생성을 위한 새로운 프레임워크인 cavia를 제안한다 뷰포인트와 프레임 전반에 걸쳐 일관성을 강화하기 위해 view-integrated attentions 교차 뷰 및 교차 프레임 3d attention을 도입한다
유연한 프레임 워크는 4개의 뷰에서 작동할 수 있어 향상된 뷰 제어 가능성을 제공한다
다중 뷰 이미지 생성
초기 접근 방식
MVDiffusion은 대응 인식 어텐션 메커니즘으로 다중 뷰 이미지를 병렬로 생성하는데 중점! 텍스처가 있는 장면 meshes에 대한 효과적인 교차 뷰 정보 상호 작용을 가능하게 했다
최근 접근 방식
Zero123, direct2.5, instant3D, MVDream, MVDiffusion, CAT3D, Wonder3D 같은 최근 방식은 다중 뷰 자체 attention을 활용해 뷰 포인트 일관성을 개선하는 단일 패스 프레임워크를 도입했다
다른 연구들은 확산 모델 내에서 향상된 뷰포인트 융합을 촉진하기 위해 에피폴라 기반 기능을 통합했다.
에피폴라 기하학: 카메라가 두 대 이상 있을 때 같은 3차원 점을 두 카메라에서 어떻게 보는지를 설명하는 기하학 구조, 2D 영상 좌표와 3D공간 점 사이의 관계를 다루는 수학적 틀
비디오 확산 모델의 사전 지식을 활용하여 일관성이 향상된 다중 뷰 생성을 달성하기도 한다
cavia의 차별점
이러한 방법들은 주로 정적 3D 객체 또는 장면 생성에 중점을 두는 반면 cavia는 복잡한 장면에서 다중 뷰 동적 비디오 생성에 생생한 객체 움직임을 보인다
4D 생성
최근 비디오 확성 모델의 score distillation으로 텍스트 또는 이미지 조건부 장면에 대한 동적 NeRF또는 3D 가우시안 최적화하는 다양한 방법을 탐색했다. 비디오-4D 생성을 조사하여 단안 비디오에서 제어 가능한 4D장면 생성을 가능하게 했다. 비디오 확산 모델을 활용해 효율적인 4D 생성에 필요한 시공간 일관성을 해결할 수 있다
위는 주로 객체 중심 생성에 중점을 둔다. 복잡한 배겨으로 사실적 결과를 생성하는데 어려움을 겪는다. cavia는 복잡한 장면에 대한 다중뷰, 3D 일관된 비디오 생성에 중점을 둔다
3. CAVIA Method
overview
- 이미지-비디오 생성: 단일 이미지 I0을 입력으로 받아 비디오 시퀀스 O0,O1,…,On를 출력한다
- 카메라 제어: 모델은 추가적으로 카메라 정보 시퀀스 C0,C1,…,Cn를 입력으로 받아 출력 시퀀스에 대한 원하는 뷰포인트 반경을 지시한다.
- 다중 뷰 시나리오 확장: 다중 뷰 시나리오에서는 카메라 제어 신호와 출력 비디오 시퀀스의 각 배치를 v시퀀스로 확장한다
- 프레임워크 개요:
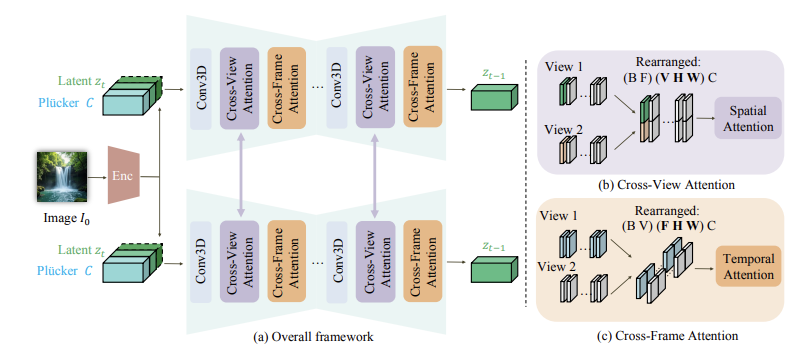
camera controllable video diffusion model
caiva 모델은 사전 훈련된 stabel bideo diffusion(SVD)을 기반으로 한다. SVD는 stavle diffusion 을 확장하여 시각적 컨볼류션 및 attention 레이어를 추가하며 videoLDM 아키텍처를 따른다 SVD는 연속 시간 노이즈 스케줄러로 훈련된다. 각 반복에서 훈련데이터는 가우시안 노이즈에 의해 교란되며 확산 모델은 클린 데이터 의 스코어 함수를 추정하도록 요청받는다.
Camera Conditioning
기존 SVD (Stable Video Diffusion)모델은 다양한 고품질 이미지와 비디오 데이터로 사전 학습되었지만, 정확한 카메라 제어(Camera Control) 기능을 직접적으로 지원하지 않는다.
이를 해결하기 위해 Plücker coordinates를 활용한 camera conditioning 방식을 도입한다.
Plücker Coordinates
- 광선(ray)을 표현하는 수학적 좌표계.
- 정의:
[ P = (d’, o \times d’) ]- ( d’ ): 정규화된(ray) 방향 벡터
- ( o ): 광선의 원점(origin)
- ( \times ): 벡터 외적(cross product)
Ray Direction 계산
카메라 외부 파라미터(Extrinsic matrix) E = [R T] 와 내부 파라미터(Intrinsic matrix) K 를 사용. - 2D 픽셀 좌표 (x,y) 에 대한 광선 방향은 다음과 같이 계산:
d = R K^{-1} \begin{pmatrix} x \ y \ 1 \end{pmatrix} + T
모델 적용 방식
이렇게 얻은 Plücker 좌표들을SVD의 원래 latent 입력에 채널 단위로 결합.
첫 번째 합성곱(convolution) 계층의 커널 크기를 확장하여 반영.
새로운 파라미터들은 0으로 초기화(zero initialization)하여 학습 안정성 유지.
상대 좌표계 (Relative Camera Coordinate System)
첫 번째 프레임을 월드 좌표계 원점에 두고, 회전은 단위 행렬(identity)로 설정.
이후 프레임들은 상대적으로 회전된 좌표계로 표현.
학습 안정화를 위해 multi-view 카메라 시퀀스를 unit scale로 정규화: 즉, 원점에서 가장 먼 거리(max distance-to-origin)를 1로 리사이즈.
Cross-frame Attention for Temporal Consistency
뷰포인트와 프레임 전반에 걸쳐 일관성을 강화하기 위해 교차 뷰 어텐션과 교차 프레임 어텐션을 도입한다
SVD 백본의 바닐라 1D 시간 어텐션은 뷰포인트가 변경될 때 큰 픽셀 변위를 모델링하는데 부족하다 어텐션 행렬이 프레임 번호 차원에 걸쳐 계산되며 잠재 특지은 동일한 공간 위치의 특징과만 상호 작용한다 이는 다른 시공간 위치 간의 정보 흐름을 제한한다
이 문제를 해결하기 위해 SVD 네트워크의 원래 1D 시간 어텐션 모듈을 3D 교차 프레임 시간 어텐션 모듈로 확장해 시공간 특징 릴관성의 공동 모델링을 가능하게 한다
시공간 특징의 유사성을 동시에 계산해 시간적 일관서을 유지하면서 더 큰 픽셀 변위를 수용한다
시간적 일관성: 비디오의 프레임들이 시간 순서에 따라 자연스럽게 연결되는 것
잠재 특징의 형태를 $(BV F C H W)$에서 $((BV)(F H W)C)$로 재배열하여 공간 특징을 어텐션 행렬에 통합한다. 이는 입력 시퀀스 길이만 변경하고 특징 차원은 수정하지 않으므로 SVD 백본의 사전 훈련된 가중치를 원활하게 상속할 수 있다
CONSISTENT MULTI-VIEW VIDEO DIFFUSION MODEL
다중 뷰 일관성 문제: Plücker 좌표를 카메라 제어에 도입하고 개선된 시간 어텐션을 도입하면 비디오 확산 모델이 합리적으로 일관된 단안 비디오를 생성할 수 있다. 그러나 다주뷰 생성은 샘플을 독립적으로 생성하는 단안 비디오 확산 모델은 여러 시퀀스에 걸쳐 뷰 일관성을 보장할 수 없다
Plücker 좌표: 3차원 공간에서 직선을 표현하는 방법 중 하나. 직선의 주소를 나타내는 특별한 코드.
Cross-view Attention for Multi-view consistency
다중 뷰 비디오에서 교차 뷰 일관성을 개선하기 위해 생성 과정에서 정보 교환을 장려한다. MVDream에서의 3D 교차 뷰 어텐션 모듈을 도입한다.
각 해당 시간 단계의 프레임이 어텐션 모듈로 보내지기 전에 연결되도록 $V$ 뷰를 재배열한다. (Fig.1(b))
두번째에서 마지막 차원만 확장되고 다른 차원은 변경되지 않으므로 확장된 공간 어텐션은 단안 설저에서 모델 가중치를 상속할 수 있다
유연성은 모델이 다양한 수의 뷰를 가진 훈련 데이터를 활용하고 추론 시 추가 뷰로 예측할 수 있게 한다
워크플로우 단순성을 유지하기 위해 다른 블록 처리 주에는 뷰 차원을 배치 차원에 흡수한다
4. 공동 학습 전략 및 데이터 혼합
데이터 혼합에 대한 공동 학습
뷰 통합 어텐션 메커니즘으로 cavia는 정적, 다중 뷰 동적, 단안 비디어를 포함한 다양한 데이터 소스를 완전히 활용하는 새로운 공동 학습 전략을 가능하게 한다
원래 비디오에서 길이 $(F-1) \times V + 1$의 임의의 하위 시퀀스는 공유 시작 프레임과 $V$-뷰 $F$ 시퀀스로 재구성될 수 있다. 정적 장면은 프레임 순서 반전도 허용하여 추가 증강도 가능하다. 약 50만 반복(static stage) 학습으로 기하학적 일관성이 생긴다
다중 뷰 동적 객체
모델이 합리적인 객체 움직임을 생성하도록 가르치기 위해 애니메이션 가능한 객체에서 렌더링된 합성 다중 뷰 비디오를 통합한다. 다양한 고도 및 방위각 변화를 가진 무작위 부드러운 궤적을 설계한다. 이러한 궤적은 공유된 무작위 전방 시작점에서 시작하여 총 $n \times v$ 프레임을 생성한다.
단안 동적 비디오
InternVid, OpenVid 등 실제 단안 비디오에 SfM 기반 카메라 포즈 주석을(Particle-SfM) 추가한다 노이즈 제거를 위해 품질을 필터링한다. 최종적으로 약 39만 개의 고품질 단안 동적 비디오 데이터셋 확보된다. 합성 데이터 과적합을 방지하고 복잡한 배경에서 사실적 객체 움직임이 표현 가능하다
데이터 큐레이션
정적 3D 객체 (Objaverse·XL 등)
40만 개 고품질 3D 자산 필터링 → Blender로 다중 뷰 512x512 렌더링(84프레임 궤도)한다. 저품질(텍스처 없음·lowpoly·잘림 현상 등) 객체는 제거한다
동적 3D 객체
Objaverse 내 애니메이션 가능한 객체를 선별한다. 지나치게 빠르거나 거의 움직이지 않는 객체는 제외한다 lpips(프레임 차이) 및 알파 마스크로 움직임 품질을 검증할 수 있다 최종 19,000개 객체 확보해 랜덤 카메라 궤적으로 렌더링한다
5. Experiments
정량적 비교


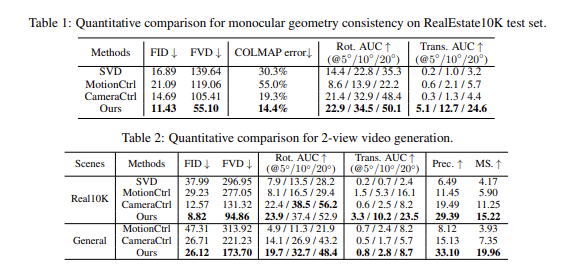
3D 일관성 평가: COLMAP을 이용해 생성된 비디오의 카메라 포즈와 3D 재구성 품질 비교, 오류율이 기존 방법 대비 낮다. CAVIA가 입력 이미지의 3D 구조 유지와 다중 뷰 일관성 면에서 우수하다.
기존 연구들과 동일하게, 추정된 카메라 포즈 시퀀스의 상대 변환·회전 누적 오류(AUC) 계산. 특정 임계값(5°,10°,20°) 내 프레임 비율에서 기존 대비 더 정확하다.
다중 뷰 교차 비디오 일관성 대응점 일치 점수(SuperGlue), 에피폴라 오류 평가지표에서 CAVIA가 기존보다 높은 정밀도와 일치 점수, 낮은 오류율
시각적 품질 평가 FID, FVD 등 이미지·비디오 지각 품질 측정에서 CAVIA가 최상위 성능을 보인다. 훈련에 쓰이지 않은 다양한 실제/합성 데이터셋에서 모두 뛰어난 결과다
정성적 비교
실제 장면(RealEstate10K) 및 텍스트-이미지 변환 샘플 기존 모델(MotionCtrl, CameraCtrl)은 카메라 궤적 단순화 혹은 왜곡, 객체 움직임의 부재 등 한계 → CAVIA는 정확한 카메라 궤적·생생한 객체 움직임을 모두 구현
보조선(overlay)이나 비디오 자료에서 생성품질의 차이를 시각적으로 보여주며, 복잡한 궤적, 동적인 내용에서도 아티팩트 없이 자연스럽다
제거 연구 및 응용
Plücker 좌표, 교차 프레임/뷰 어텐션, 단안 공동 학습 전략 각각의 포함/제외 실험 → 모듈이 제거될 때 3D 왜곡, 일관성 저해, 배경 단순화 등 문제가 명확히 나타나며 모든 구성요소가 CAVIA의 압도적 최종 성능 달성에 기여한다
6. Conclusion
Cavia는 일관된 다중 뷰 카메라 제어가능한 비디오 생성을 위한 새로운 프레임워크이다.
효과적인 카메라 제어가능성 및 뷰 일관성을 위해 교차 프레임 및 교차 뷰 어텐션을 통합한다.
정적 3D 장면 및 객체, 애니메이션 가능한 객체, 야생 단안 비디오를 사용한 공동 학습의 이점을 얻는다.
기하학적 일관성및 지각적 품질 측면에서 이전 연구보다 Cavia방법이 우수하다.