[논문정리] Lavender: Diffusion Instruction Tuning
Chen Jin, Ryutaro Tanno, Amrutha Saseendran, Tom Diethe, Philip Teare(2025).Diffusion Instruction Tuning.ICML
diffusion model의 시각적 전문성을 활용하여 비전-언어모델(VLM)의 성능을 혁신적으로 향상시키는 Lavender라는 새로운 미세 조정 프레임워크를 소개한다. 기존 VLM이 겪는 데이터 부족 문제를 해결하고 이미지 생서 모델의 정확한 텍스트-영역 정렬을 VLM에 전이시켜 복잡한 시각적 추론 및 질의응답 작업에서 최대 68% 성능 향상을 보인다. 작은 학습 데이터와 제한된 컴퓨팅 자원으로 모델의 견고성과 일반화 능력을 크게 높여 의료 QA와 같은 OOD환경에서도 뛰어난 성과를 보여준다. 이는 멀티모달 AI 연구자들이 데이터 효율적인 VLM 학습과 정밀한 시각-텍스트 정렬을 구현하는데 필요한 실용적인 통찰.과 방법을 제공한다.
diffusion model: 데이터를 생성하는 모델 중 하나로 노이즈를 추가하여 완전한 노이즈 이미지로 만든 다음 노이즈를 복원하면서 데이터를 생성하는 모델이다
Vision-Language Model: 이미지와 텍스트를 동시에 이해하고 처리하는 인공지능 모델. 이미지 내용을 파악하고 그에 대한 텍스트를 생성하거나 텍스트를 통해 이미지를 검색할 수 있다.
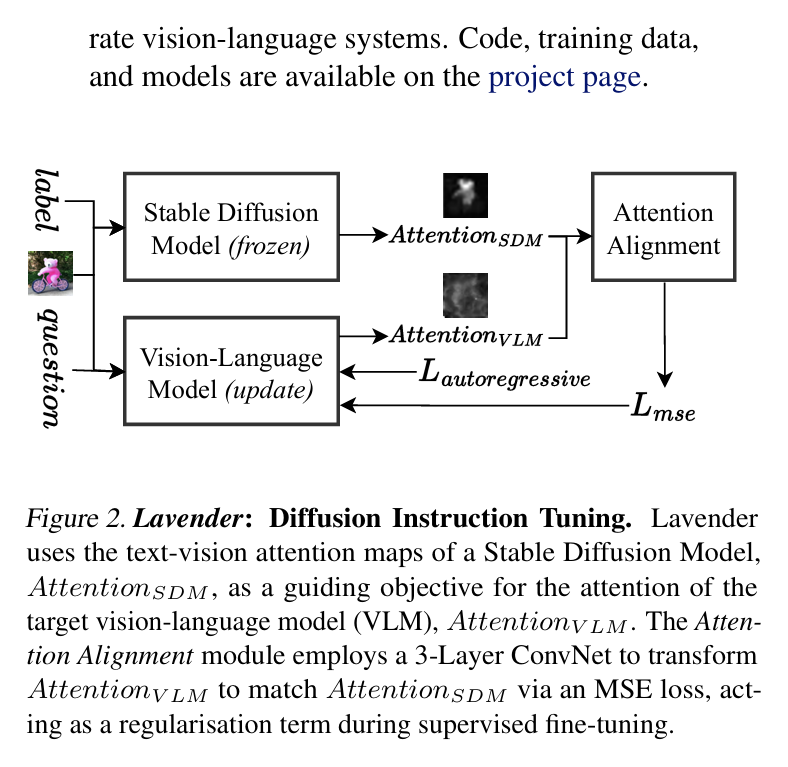
VLM 학습의 어려움 및 해결책
기본 VLM 학습은 높은 비용, 데이터 부족문제, 어텐션 정렬의 한계가 있다. 어텐션 정렬 한계로 기존 방법들은 제한된 이미지-텍스트 쌍으로 사전 훈련된 LM에 지도 미세 조정을 적용하지만 LLM 코어 내 트랜스포머 수준 어텐션 정렬의 중요성을 간과하는 경향이 있다. 정혹한 시각-텍스트 정렬이 필수적이다.
정확한 텍스트-시각 어텐션 맵으로 Stable Diffusion과 같은 DM은 픽셀 수준에서 이미지를 재구성하기 때문에 텍스트 토큰 생성에만 최적화된 VLM보다 더 저혹한 텍스트-시각 어텐션 맵을 학습한다.
DM의 어텐션 맵은 이미지 영역과 텍스트 토큰을 상관시키는 이상적인 분포에 더 가깝다.
Stable Diffusion: 사용자가 입력한 텍스트 설명을 기반으로 고품질 이미지를 생성하는 인공지능 모델.
Lavender에서 DM의 고품질 교차 어텐션 맵을 VLM의 텍스트-시각 어텐션을 안내하는 것을 목표로 확용해 단어-영역 정렬 및 전반적인 성능을 향상시킨다.
lavender는 기존 VLM 의 역량을 보존하는 여러 어텐션 집계 방법고 훈련 전략을 제안하여 모델의 견고성과 일반화 능력을 높인다. 마지막으로 데이터의 효율성이 높다.
Lavender의 핵심 원리와 작동 방식
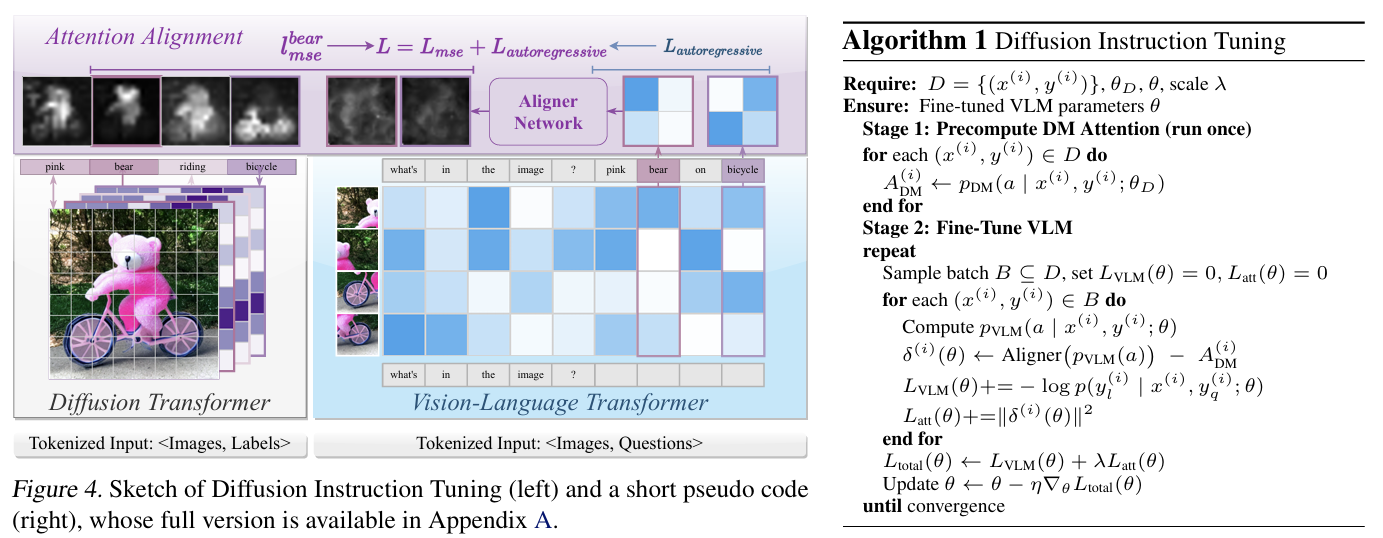
Stable Diffusion의 attention맵을 이용하여 텍스트와 이미지 간의 연관성을 강화한다. transformer 의 attention레이어를 정렬하는 방식으로 텍스트 토큰과 이미지 영역간의 관계를 더 정확히 맞춘다. Diffusion모델의 높은 품질의 attention 맵이 VLM의 텍스트-비전 attention을 안내하는 목표로 사용된다. supervised fine-tuning 동안 VLM의 tranformer attention을 stable diffusion과 직접 정렬하는 과정이 수행된다.
Lavender 의 기술적 구성 요소
VLM과 Diffusion Model의 attentino분포를 비교하고 정렬한다.
θ: VLM 파라미터
θ_D: 고정된 Diffusion Model 파라미터
p(a|x,y;θ): VLM의 attention 분포
p_D(a|x,y;θ_D): DM의 attention 분포
목표: p(a|x,y;θ)가 p*(a|x,y)라는 이상적(최적) attention 분포에 가깝게 만든다.
attention 정렬 방법
diffusion model의 attention 맵은 픽셀 수준에서 매우 정밀하며 텍스트 토큰과 이미지 영역 간의 강한 연관성을 보여준다.
VLM의 attention 맵은 여러 헤드와 레이어를 통해 텍스트와 이미지 패치 간의 관계를 포착
attention 맵을 정렬하는 방법으로 간단한 방법은 attention 가중치를 평균 또는 최대값으로 pooling 방법이 있다. 더 정교한 방법은 attention flow또는 학습된 가중치를 이용한 학습 기반 정렬이다.
attention aggregation은 여러 레이어와 헤드의 attention을 통합하는 다양한 기법을 사용한다. 학습된 attention 가중치가 뛰어난 성능을 보인다.
attention 정렬을 위한 네트워크 전략
aligner 네트워크는 가벼운 MLP또는 컨볼루션 네트워크로 구성된다. attention 맵을 정제하여 DM의 attention과 비교 가능하게 만들었다.
attention차이 δ(i)(θ)를 최소화하는 방향으로 학습한다. 정렬 손실은 MSE 손실로 계산하여 attention분포를 정렬하는데 사용된다.
parallel attention은 일부 레이어는 기존 attention 과 병렬로 학습하여 기존 지식을 유지하면서 새로운 패턴을 학습 가능하다.
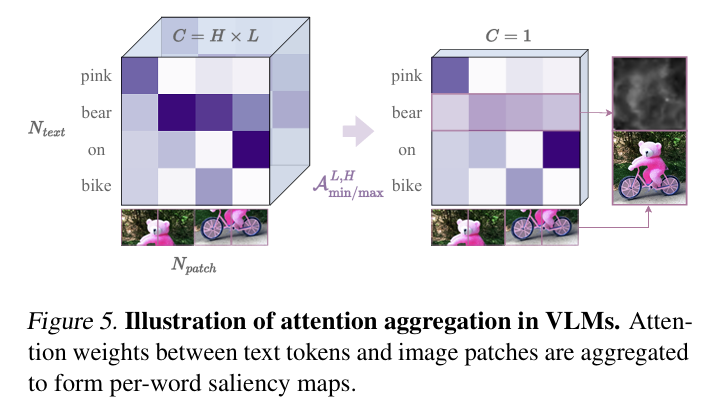
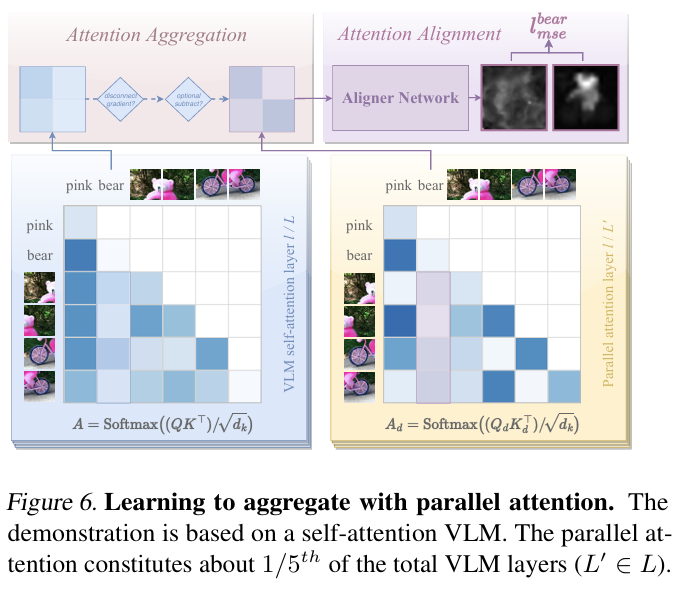
lavender 의 적용 대상과 실험
적용 대상: OpenFlamingo, Llama3.2-11B-VisionInstruct, MiniCPM-Llama3-v2.5 등 다양한 VLM.
Stable Diffusionv1.4를 기반으로 하여 per-word attention target 생성.
실험 방법:
attention 맵 추출: Stable Diffusion에서 이미지-질문 쌍의 attention 맵을 얻음.
attention 정렬: VLM의 cross- 또는 Self-Attention레이어를 wrapping하여 attention 맵을 추출.
attention 정렬 손실을 통해, 모델이 DM의 attention 분포를 따르도록 학습.
Lavender의 성능 향상 효과
작은 데이터셋(Flickr30k)에서 attention entropy 낮추기, attention 정렬 성공했다. 다양한 벤치마크에서 최대 72%의 zero-shot 성능 향상했다. Llama3.2-11B-VisionInstruct 모델은 최대 30% 성능 향상했다.
텍스트-이미지 영역 정렬이 강화되어, 더 정밀한 비전-언어 이해 가능하다. 이미지 내 세부 요소 인식, 정답률 향상하고 오답 및 hallucination이 감소한다.
Lavender의 장점과 특징
데이터 계산 자원 절약했다. 적은 수의 이미지-텍스트쌍만으로도 성능 향상 가능하다. 계산 비용이 적고 다양한 모델에 적용 가능하다.
attention 또는 self-attention 모델 모두에 적용 가능하다. RL 후처리, 강호학습과 결합 가능하다.
언어와 비전 모델의 통합가능하다. 데이터 효율적 학습, 프라이버시 보호 가능하다. 다양한 멀티모달 태스크에도 확장 가능하다.
결론 및 미래 방향
Lavender는 Diffusion Models의 정밀 attention 맵을 활용하여 기존 VLM의 성능과 신뢰도를 크게 향상시킨다.
계속된 연구와 확장을 통해, 더 높은 해상도, 더 정밀한 attention 맵, 다양한 멀티모달 태스크에 적용 가능성 기대한다.
이 방법은 데이터와 계산 자원 절약, 모델의 일반화 능력 향상, 그리고 멀티모달 AI의 발전에 중요한 기여를 할 것임.