[논문정리] GAN
Jean Pouget-Abadie, Ian J. Goodfellow, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Yoshua Bengio, Aaron Courville (2014).Generative Adversarial Nets.
1. Introduction
Generative Adversarial Nets (GANs)라는 새로운 프레임워크를 제안하며 이는 생성 모델(G)과 판별 모델(D)을 경쟁시키는 방식으로 작동한다. 마치 위조범과 경찰처럼 두 모델이 서로를 상대로 훈련하며 데이터 분포를 정확하게 복제하는 방법을 제시하는데 이는 기존의 복잡한 확률 계산 없이 backpropagation 알고리즘만으로 훈련이 가능하다.
생성 모델 (G): 데이터 분포를 학습한다.
판별 모델 (D): 샘플이 실제 훈련 데이터에서 왔는지 아니면 G에서 생성되었는지 확률을 추정한다.
G는 D가 실수할 확률을 최대화하도록 훈련된다.
복잡한 확률 계산 없이 backpropagation 알고리즘, 드롭아웃 알고리즘만으로 훈련이 가능하다.
샘플 생성이나 훈련 시 Markov chains이나 근사 추론 네트워크가 필요 없다.
기존 생성 모델들은 샘플 생성, 훈련에 복잡한 과정이 필요했는데 GAN은 단순한 순전파만으로 해결한다
기존 생성 모델:
샘플 생성: Markov chain으로 여러 단계 샘플링이 필요하다
훈련: 근사 추론 네트워크로 확률 밀도 계산 → 복잡
GAN:
샘플 생성: G(z) 한 번 순전파 → 즉시 샘플 생성
훈련: V(D,G) 미분 → backprop만으로 끝
기존 딥러닝의 성공은 주로 discriminative models에서 두드러졌다.
최대 우도 추정 등에서 발생하는 복잡한 확률 계산 때문에 영향력이 적었다.
전통적 생성 모델이 데이터 전체 분포를 수학적 수식으로 직접 정의하려고 했기 때문이다. 이미지와 같은 복잡한 데이터에서는 이 계산을 컴퓨터가 처리하기에 너무 방대하고 복잡했다.
G는 위조지폐를 만드는 위조범, D는 이를 탐지하는 경찰에 비유되며 경쟁을 통해 위조품이 진짜와 구별 불가능해질 때까지 발전한다.
3. Adversarial nets
G는 입력 노이즈 $z \sim p_z(z)$를 데이터 공간으로 매핑하는 미분 가능한 다층 퍼셉트론 $G(z; \theta_g)$이다.
D는 단일 스칼라를 출력하는 다층 퍼셉트론 $D(x; \theta_d)$이다.
D와 G는 $V(G, D)$를 minmax game을 한다.
\[V(D,G) = E_{x \sim p_{data}(x)}[\log D(x)] + E_{z \sim p_z(z)}[\log(1 - D(G(z)))]\]판별자는 값을 최대화 하려고 하고 생성자는 최소화하려는 게임
첫번째 항: 실제 데이터 x를 판별자에게 주었을 때의 기댓값. D는 진짜를 진짜로 맞춰야하므로
두번째 항: 생성자가 만든 가짜 데이터 G(x)를 판별자에게 줬을 때 기댓값.
판별자($D$) 는 가짜를 0으로 판별해야 하므로 $D(G(z))=0$이 되어 $\log(1)=0$이 되도록 이 값을 최대화하려 합니다.
생성자($G$) 는 판별자를 속여 $D(G(z))=1$이 되게 함으로써 $\log(1-1)=-\infty$가 되도록 이 값을 최소화하려 합니다.
0과 $-\infty$ 중에서 더 큰값은 0이다. 판별자 입장에서 0으로 끌어올리기 위해 D(G(z))를 0으로 만들려고 하는것이다. : 최대화
G가 고정되었을 때 최적의 판별자 $D^*(x)$는 다음과 같다.
\[D^*(x) = \frac{p_{data}(x)}{p_{data}(x) + p_g(x)}\]학습이 완벽하게 진행되어 생성자가 실제 데이터를 완벽히 복제하면 $p_g = p_{data}$가 된다. 이 경우 $D^*(x)$는 0.5가 된다. 이는 판별자가 진짜와 가짜를 전혀 구분하지 못하고 반반의 확률로 찍는 상태에 도달했음을 의미한다

Algorithm 1: D와 G를 번갈아 업데이트한다.
D 업데이트:
D를 최대화하기 위해 $k$ 스텝 동안 gradient ascent을 수행한다.
G 업데이트:
G를 최소화하기 위해 1 스텝 동안 gradient descent을 수행한다.
G가 초기에 나쁠 경우 $\log(1 - D(G(z)))$ 항이 포화될 수 있다. 이 경우 G는 $\log D(G(z))$를 최대화하도록 훈련하여 더 강력한 기울기를 얻는다.
학습 초기에는 G의 성능이 매우 낮아 D가 가짜를 거의 100%로 잡아낸다. D(G(z)) 값은 0에 가까워지는데 원래 수식인 $\log(1 - D(G(z)))$는 이 지점에서 그래프가 매우 완만하다. 기울기가 너무 작아지면 생성자는 어떻게 매개변수를 수정해야 할지 힌트를 얻지 못해 학습이 정체되는데 이를 포화되었다고 한다.
수식을 $\log D(G(z))$를 최대화하는 방향으로 바꾸면 $D(G(z))$가 0 근처일 때 기울기가 매우 급격해진다. 판별자가 가짜라고 강력하게 확신할수록 생성자에게 더 강한 피드백을 전달하여 초기의 나쁜 성능을 빠르게 탈출할 수 있도록 돕는다
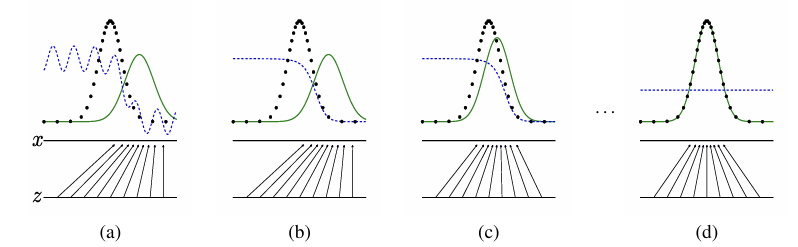 검은색: 복제하고자 하는 실제 데이터 확률 분포
검은색: 복제하고자 하는 실제 데이터 확률 분포
초록색: 생성자가 만들어내고 있는 가짜 데이터 확률 분포
파란색: 판별자 판단 기준. 선이 위로 갈수록 진짜, 아래로 갈수록 가짜라고 판단한다.
화살표: 어떻게 매핑하고 있는지
생성자와 판별자가 서로 경쟁하며 데이터 분포를 맞춰가는 과정
맨처음에 요동치듯이 있는 이유?
판별자도 처음에는 가중치가 랜덤하게 설정되기 때문. 아직 무엇이 진짜이고 가짜인지 판단할 기준이 없다.
b는 그래도 판단 기준이 있는 상태
4. Theoretical Results
G와 D가 충분한 capacity을 가질 경우 minmax game은 글로벌 최적점을 가지며 이때 $p_g = p_{data}$가 된다.
목적함수 글로벌 최적점($p_g = p_{data}$)에서 $C(G)$ 값은 $-\log 4$이다.
\[C(G) = -\log(4) + 2 \cdot JSD(p_{data} || p_g)\]JSD
두 확률 분포가 서로 얼마나 다른지 측정하는 거리 측정기
JSD는 두 분포가 같을 때만 0이 되므로 $C(G)$의 글로벌 최솟값은 $p_g$가 $p_{data}$를 완벽하게 복제할 때 달성된다.
5. Experiments
 Table 1. Parzen window-based log-likelihood estimates.
Table 1. Parzen window-based log-likelihood estimates.
실험 데이터셋:
MNIST, TFD(Toronto Face Database), CIFAR-10을 사용했다.
평가 방법:
생성된 샘플에 대해 Parzen window를 피팅하여 log-likelihood를 추정했다.
Parzen window
데이터의 정확한 확률 분포 수식을 모를 때 가지고 있는 샘플을 바탕으로 분포의 모양을 추정하는 방법
생성된 데이터 점 하나하나에 가우시안 커널을 올린다. 모두 더하면 데이터가 밀집된 곳은 높고 없는 곳은 낮다. 이게 모델이 학습한 확률 분포 근사치가 된다.
왜 FID는 안했을까?
GAN은 2014년에 발표 되었다. FID는 2017년.
2014년에는 생성 모델의 성능을 정량적으로 측정할 마땅한 기준이 없었다. 그래서 당시 통계적으로 많이 쓰이던 parzen window 방식을 사용했다.
GANs는 DBN, StackedCAE, DeepGSN과 비교하여 경쟁적인 로그 우도 추정치를 보였다.

노란색 상자:
생성된 바로 옆 이미지와 가장 유사한 실제 훈련 데이터. 생성된 이미지와 실제 데이터가 서로 다르다는 점을 통해 모델이 데이터를 그대로 복사하지 않고 데이터의 특징을 배워 새로운 이미지를 만들었다는 것을 알 수 있다
생성된 샘플은 훈련 세트를 암기하지 않았으며 마르코프 체인 기반 샘플링과 달리 상관관계가 없다.
a) MNIST: 손글씨 숫자를 매우 선명하게 생성했다.
b) TFD: 토론토 얼굴 데이터베이스의 특징을 살려 다양한 사람의 얼굴 형태를 생성했다.
c) & d) CIFAR-10:
c)는 일반적인 Fully connected 모델의 결과이다.
d)는 합성곱 구조를 사용한 결과로, 더 복잡한 사물의 형태를 더 잘 포착하고 있음을 보여준다.
c & d
합성곱 구조가 Fully Connected 모델보다 시각적 데이터를 처리하는 데 훨씬 더 효율적이기 때문이다.
이미지는 단순히 픽셀의 나열이 아니라 픽셀 간의 공간적 관계가 핵심인데 합성곱 구조는 이 관계를 아주 잘 포착한다.
6. Advantages and disadvantages
GANs의 장점:
마르코프 체인이 필요 없다.
역전파만으로 훈련이 가능하다.
sharp distributions 표현이 가능하다.
VAE!를 불러오자
기존 생성 모델은 데이터를 생성할 때 MSE를 사용하여 평균적인 값을 찾으려는 경향이 있어서 결과물이 다소 흐릿하게 나오는 경우를 봤다. 반면 GAN은 판별자가 아주 미세한 차이에도 가짜를 잡아내려 하기 때문에 생성자는 실제 데이터같은 선명한 경계와 디테일을 만든다.
GANs의 단점:
G와 D의 synchronization가 중요하다.
D가 너무 많이 훈련되면 G의 학습이 어려워질 수 있다.
GAN은 생성자가 판별자가 경쟁하며 학습된다. D가 G를 처음부터 완벽하게 잡아내면 G는 어떤 부분이 부족해서 걸렸는지 파악할 수 없다.
원래 얻던 힌트: 기울기
반대로 G가 너무 많이 훈련된다면? 그런 경우도 있는지
7. Conclusions and future work
조건부 생성 모델:
G와 D 모두에 조건 입력 $c$를 추가하여 $p(x|c)$를 얻을 수 있다.
학습된 근사 추론(Learned approximate inference):
G와 D 외에 추론 네트워크를 학습할 수 있다.
학습된 근사 추론:
GAN에 인코더 기능을 추가하여 이미지에서 특징을 역으로 추출하겠다
GAN은 노이즈z를 이미지 x로 변환하는 과정으로 작동한다. 근사 추론 네트워크는 이 반대 방향을 수행하는 추가로 학습시켜 모델이 데이터를 양방향으로 이해하게 만드는 것을 말한다
VAE: 인코더가 있어 이미지 $x$로부터 잠재 변수 $z$를 추출하는 과정이 자연스럽게 포함된다.
GAN (2014): 노이즈 $z$에서 이미지 $x$를 만드는 단방향 모델이다. 이미지에서 특징을 뽑아내려면 학습된 근사 추론 같은 추가 구조가 필요하다.
준지도 학습(Semi-supervised learning):
D의 features을 분류기 성능 향상에 활용할 수 있다.
D를 확장된 분류기로 사용
효율성 개선:
훈련 가속화를 위한 더 나은 방법론을 찾는다.
- 이해하고
2. Related work
RBMs/DBMs: 잠재 변수를 가진 비방향성 그래프 모델로 전역 합계(partition function) 계산이 어려워 Markov chain Monte Carlo에 의존한다.
NCE (Noise-Contrastive Estimation): 판별 훈련 기준을 사용하지만, G 자체가 노이즈 분포 샘플과 G 생성 데이터를 구별하는 데 사용되어 학습이 느려지는 한계가 있다.
GSN (Generative Stochastic Network): 파라미터화된 마르코프 체인을 정의하지만 GANs는 샘플링을 위해 마르코프 체인을 요구하지 않아 feedback loops 사용에 유리하다.