[논문정리] StyleSDF
Xuan Luo, Mengyi Shan, Eli Shechtman, Roy Jeong, Joon Park, Ira Kemelmacher-Shlizerman(2022).StyleSDF: High-Resolution 3D-Consistent Image and Geometry Generation.CVPR2022

abstract
StyleSDF는 단일 시점 이미지만을 학습하여 고해상도의 3D 일관성 있는 이미지를 생성하는 기술이다. 보잡한 3D데이터나 다중 시점 데이터 없이도 실감나는 3D 형상과 디테일한 텍스처를 구현하며 기존 방식의 한계를 뛰어넘는 시각적 품질을 제공한다.
1. Introduction
StyleSDF는 단일 시점 이미지 학습만으로 고해상도의 3D 일관성 있는 이미지를 생성하는 기술이다.
기존 styleGAN 아키텍처를 기반으로 하지만 3D 일관성있는 이미지 생성에 특화되어있다.
고해상도 3D 일관성 이미지 생성의 어려움을 해결한다. 단일 RGB 이미지 학습만으로 상세한 3D 형상과 외형을 생성한다.
SDF 기반 3D 표현과 스틸 기반 2D 생성 네트워크를 결합한다.
기존 연구들은 저해상도를 출력하거나 다중 시점 데이터 또는 복잡한 렌더링 과정이 필요했는데 이는 이를 극복하고 높은 시각적 품질을 달성한다.
2. Related Work
3. Algorithm
3.1. Overview
3D 형상을 SDF로 표현하여 표면을 정의한다.

SDF는 3D 공간 내 각 지점까지 거리를 나타낸다. 부호로 표면 바깥과 안을 나타낸다.
StyleGAN 아키텍처를 활용하여 고해상도 이미지를 생성한다.
학습된 latent code를 통해 이미지의 스타일을 제어한다.
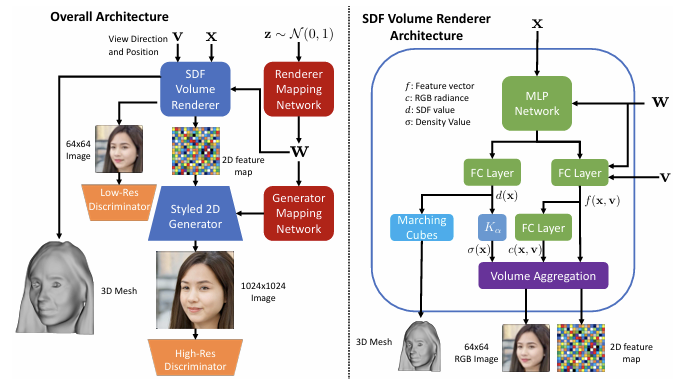
overall architecture
잠재 코드 z가 어떻게 최종 1024x1024 고해상도 이미지가 되는지 보여준다.
Latent Space ($z \to W$):
$z \sim \mathcal{N}(0, 1)$: 무작위 노이즈이다.
Renderer/Generator Mapping Network: StyleGAN처럼 이 노이즈를 더 정교한 스타일 공간인 $W$ 로 변환한다. 여기서 $W$는 3D 형태(코 높이 등)와 2D 스타일(머리카락 질감 등)을 동시에 조절하는 통제 센터 역할을 한다.
SDF Volume Renderer:
$W$와 카메라 정보($V, X$)를 받아 저해상도(64x64) 이미지와 2D Feature Map을 만든다.동시에 내부의 SDF 정보를 이용해 3D Mesh를 직접 뽑아낼 수도 있다.
Styled 2D Generator (Refinement Network):
Renderer가 만든 64x64 결과물은 기하학적으로는 정확하지만 해상도가 낮다.이 2D Generator가 Feature Map을 넘겨받아 StyleGAN의 업샘플링 방식을 통해 1024x1024의 실사 같은 고해상도로 Refine한다.
Dual Discriminators (Low-Res & High-Res):
판별자가 두 개다. 하나는 3D 구조가 올바른지(64x64), 다른 하나는 눈에 보이는 화질이 실사 같은지(1024x1024)를 각각 감시하여 학습의 안정성을 높인다.
SDF Volume Renderer Architecture
입력된 좌표 X가 어떻게 색상과 밀도로 변하는지 보여준다.
MLP Network & FC Layers:
공간 좌표 $X$와 스타일 $W$를 입력받아 처리하는 심층 신경망이다.
$d(x)$ (SDF value): 특정 좌표에서 표면까지의 최단 거리를 계산한다.
$f(x, v)$ (Feature vector): 단순히 색상뿐만 아니라 빛의 방향($V$)에 따른 특징을 담은 벡터다.
$K_{\alpha} \to \sigma(x)$ (Density 변환):
SDF 값($d$)을 앞서 배운 라플라스 분포 기반 수식($K_{\alpha}$)을 통해 밀도($\sigma$) 로 변환한다. 표면($d=0$) 근처에서 밀도를 높여 물체의 경계를 확실히 한다.
$c(x, v)$ (RGB radiance):
해당 지점의 실제 색상(RGB)을 결정한다.
Marching Cubes:
SDF 값들 중 0인 지점만 연결해서 3D Mesh을 만드는 알고리즘이다. 여기서 우리가 아는 3D 형태가 나온다.
Volume Aggregation (적분):
카메라에서 쏜 빛의 경로 위에 있는 모든 샘플($\sigma, c, f$)을 합쳐서 최종적으로 픽셀 하나하나의 RGB 이미지와 2D Feature Map을 만들어낸다.
3.2. SDF-based Volume Rendering
SDF필드와 카메라 정보(위치, 방향)를 입력받아 2D 이미지를 생성한다. 볼륨 렌더링 기법으로 3D 표면의 가시적인 정보를 2D 뷰로 투영한다.
일관된 결과를 얻게 된다.
3.3. High-Resolution Image Generation
3.4. Training
3.4.1 Volume Renderer training
3.4.2 Styled Generator Training
훈련 과정
SDF 기반 볼륨 renderer을 먼저 훈련하고 StyleGAN의 가중치는 고정한다.
SDF 볼륨 렌더러의 가중치를 고정하고 styleGAN generator을 훈련한다.
손실함수
adversarial loss: 생성된 이미지가 실제 이미지처럼 보이도록 한다.
view consistency loss: 다른 시점에서 보더라도 동일한 객체가 일관되게 보이도록 한다.
eikonal loss: SDF가 물리적으로 유효한 값을 갖도록 보장한다.
minimal surface loss: 불필요한 표면 생성을 억제하고 명확한 표면을 유도한다.
4. Experiments
4.1. Datasets & Baselines
FFHQ: 고해상도 얼굴 데이터셋
AFHQ: 동물 얼굴 데이터셋
4.2. Qualitative Evaluations
기존 방법론들은 저해상도 출력을 생성하거나 눈에 띄는 artifact가 발생했다.
StyleSDF는 고해상도 이미지와 상세한 3D 형상을 생성하며 객체의 정체성을 유지한다.
novel view synthesis:
styleSDF는 학습 데이터에 없던 새로운 시점에서도 사실적인 이미지를 생성할 수 잇다. 일관성 있는 표현 덕에 가능하다.
4.3. Quantitative Image Evaluations
평가지표: FID, KID
평가 결과:
StyleSDF는 FFHQ 및 AFHQ 데이터셋에서 FID 및 KID 점수 면에서 기존 방법론보다 우수한 성능을 보였다.
styleSDF가 생성하는 이미지의 시각적 품질과 다양성이 뛰어나다.
depth consistency:
styleSDF는 깊이 맵의 일관성 측면에서도 기존 방법론 대비 크게 향상된 성능을 보인다. 3D 형상이 다양한 시점에서 일관되게 표현된다.
4.4. Volume Rendering Consistency
5. Limitations & Future Work
고해상도 디테일(머리카락)에서 약간의 깜빡임 현상이 나타날 수 있다. styleGAN2의 아키텍처 기반으로 인한 것으로 추정된다
반사광이나 복잡한 표면 상호작용 효과를 표현이 어렵다. 카메라 움직임에 따른 반사광 표현이 부자연스러울 수 있다.
현재 구현은 고정된 전면 카메라 방향을 가정한다. 동적인 카메라 제어에 제약을 줄 수 있다.
6. Conclusions
StyleSDF는 단일 뷰 RGB 이미지 데이터셋만으로도 고해상도, 3D 일관성을 갖는 이미지를 생성할 수 있는 효과적인 프레임워크이다.
3D-aware 생성 모델이 단일 뷰 데이터만으로도 상세한 3D 형상과 고품질 이미지를 생성할 수 있음을 입증했다.
기존 3D aware GAN들이 주로 저해상도 출력을 생성하거나 다중 뷰 데이터가 필요한 것과 달리 StyleSDF는 고해상도와 단일 뷰 학습을 동시에 진행한다.