DeepSDF
나중에 논문을 읽으면서 다시 정리할 예정이다. 그 전에 개념적인 부분을 알아두고자 한다.
DeepSDF
3D형상을 좌표와 수치로 구성된 연속적인 함수로 정의하고 이를 신경망으로 학습하는 기술이다.
SDF Signed Distance Function
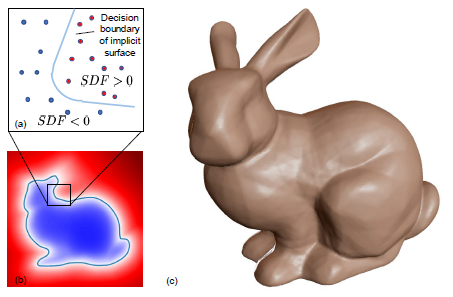
3D 딥러닝에서는 mesh 데이터를 그대로 모델에 넣기 어렵다. 메쉬는 vertex와 face로 구성된 비정형 구조이다. 개체마다 topology가 다르기 때문에 텐서 형태로 고정하기 어렵다. 이를 해결하기 위해 SDF가 활용된다.
3D 공간의 각 좌표에 대해 해당 점이 어떤 표면으로부터 얼마나 떨어져있는지를 실수값으로 나타내는 함수이다. 표면 내부의 점은 음수, 표면 위는 0, 표면 외부는 양수값이다.
voxel 방식과 달리 공간의 모든 좌표에 대해 거리 값을 정의할 수 있으므로 이론적으로 무한한 해상도를 가진다.
DeepSDF
특정 사물의 SDF를 직접 계산하는 대신 딥러닝 모델이 함수를 흉내내도록 학습한다.
SDF를 표현하는 방식이 전통적인 grid 방식에서 딥러닝 방식으로 바꾼 것이다.
SDF는 3D공간을 잘게 쪼갠 voxel에 각 점의 거리 값을 저장한다. DeepSDF는 거리 값을 격자에 일일이 저장하지 않고 신경망이 거리 값을 계산하는 공식 자체를 학습하게 한다.
SDF는 단순 3D 데이터를 표현하는 것이고 DeepSDF는 데이터 생성, 형태 보간, 예측 등을 한다.
기존 SDF가 가진 메모리 효율성과 해상도 제한 문제를 해결하고 여러 개체의 형상을 학습하기 위해 DeepSDF가 생겼다
기존의 3D 표현 방법들은 보잡한 위상 구조를 처리하고 고해상도로 확장하는데 한계가 있다. 연속적인 표면을 비효율적으로 표현하여 생성 모델링, 재구성을 위한 충실도 한계가 있었다.
다양한 형태를 표현하고 이를 저차원 latent space에 내장할 수 있는 효율적이고 표현력이 풍부하며 완전히 연속적인 generative 3D 모델링 접근 방식을 개발하는 것을 목표로 한다.
DeepSDF는 학습된 Signed Distance Function 으로 표현되는 연속적인 implicit surface를 사용하여 생성적 형상 조건부 3D 모델링을 공식화한다.
잠재 벡터와 디코더 가중치를 공동으로 최적화하는 확률적 auto-decoder를 기반으로 하는 3D 형상 학습 방법이 도입되어 효율적이고 고품질의 형상 생성을 가능하게 한다.
DeepSDF는 3D 형상 표현 및 완성에서 최첨단 성능을 보여주며 복잡한 토폴로지를 가진 고품질의 연속적인 표면을 생성하는 동시에 모델 크기를 크게 줄인다.
GAN, VAE처럼 이미지를 입력받아 특징을 추출하는 Encoder가 없다.
auto-decoder 기반 DeepSDF 공식은 인코더 없이 Maximum-a-Posterior estimation을 통해 최적의 latent vector를 추정함으로써 부분적인 관측으로부터 형상 완성을 한다.
Maximum-a-Posterior estimation MAP 최대 사후 확률 추정으로 주어진 데이터와 기존의 지식을 결합해 가장 정답일 가능성이 높은 값을 찾는 통계적 방법이다.
학습 데이터셋에 있는 각 3D 모델마다 임의의 latent code z를 할당한다. 학습 과정에서 신경망의 가중치와 각 모델의 z값을 동시에 업데이트한다. 출력된 SDF값과 실제 데이터의 SDF 값 사이의 차이를 줄이는 방향으로 학습한다. 이때 z가 너무 커지지 않도록 정규화를 거친다.
DeepSDF는 부드럽고 완전한 형상 임베딩 공간을 학습하여 서로 다른 형상 간의 의미 있는 latent space 보간을 가능하게 한다.
inference & 복원 과정
학습이 끝나고 새로운 3D 형태를 생성하거나 복원할때 방법이다.
관측된 일부 좌표 데이터만 가지고 해당 물체에 가장 적합한 z값을 역으로 찾아낸다. 결정된 z값을 고정한 채로 공간 전체의 좌표를 모델에 통과시킨다. f(z,x)=0인 지점들을 연결하면 매끄러운 3D mesh가 추출된다.
의의
latent 공가나에서 두 코드 z1, z2사이를 이동하면 형태가 끊어지지 않고 자연스럽게 변하는 3D 모델을 생성할 수 있다.
수백만 개의 점이나 폴리곤 대신 작은 신경망 가중치와 짧은 벡터 z만으로 복잡한 형태를 저장할 수 있다.
물체에 구멍이 생기거나 두 물체가 합쳐지는 등 복잡한 위상 변화를 수식적으로 자연스럽게 처리한다.
VolSDF와 차이
DeepSDF는 3D 형상 그 자체를 표현하는 방식이고 VolSDF는 그 형상을 찍어내기 위해 렌더링 기술과 결합한 방식이다.
DeepSDF는 3D geometry의 효율적 표현으로 학습데이터는 3D 데이터이다.
VolSDF는 2D 이미지를 통한 3D 형상 rendering으로 학습 데이터가 2D 이미지, 여러 각도에서 찍은 사진이다.