[논문정리] Adaptive Keyframe Sampling for Long Video Understanding
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, Qixiang Ye(2025).Adaptive Keyframe Sampling for Long Video Understanding.CVPR2025
긴 영상의 핵심 정보를 놓치지 않고 AI 가 정확하게 이해하도록 돕는 기술이다. 방대한 영상 데이터 속에서 중요한 순간만을 선별하여 AI의 이해도를 높여준다. 더 정확하고 풍부한 영상 결과를 제공할 수 있다.
MLLM은 시각적 입력을 LLM에 컨텍스트로서 추가 토큰을 주입함으로써 오픈 월드 시각 이해를 가능하게 했다. 시각적 입력이 단일 이미지에서 긴 비디오로 변경될 때 방대한 양의 비디오 토큰이 MLLM의 최대 용량을 훨씬 초과하기 때문에 어려움이 있다. 기존 비디오 기반 MLLM은 입력 데이터에서 소량 토큰을 샘플링 하는 방식이라 잘못된 대답을 할 수 있다.
이 논문은 Adaptive Keyframe Sampling AKS라는 간단하면서도 효과적인 알고리즘을 제안한다. 고정된 수의 비디오 토큰으로 유용한 정보를 최대화하는 것을 목표로 하는 키프레임 선택이라는 플러그앤 플레이 모듈을 삽입한다. 키프레임 선택을
1) 키프레임과 프롬포트 간의 관련성
2) 비디오에 대한 키프레임의 커버리지를 포함하는 최적화 문제
로 공식화하고 최적의 해를 근사하기 위한 알고리즘을 제안한다.
AKS가 정보성 키프레임을 선택함으로써 비디오 QA 정확도를 향상시킨다는 것을 검증한다
QA 정확도
AI 모델이 비디오 내용을 보고 주어진 질문에 대해 얼마나 올바른 정답을 내놓았는지를 수치로 나타낸 성공률이다.
진정으로 검증한 것인지 이건 나중에 다 하고 확인
오픈월드?
AI가 학습 과정에서 명시적으로 배우지 않은 새로운 사물이나 복잡한 상황도 유연하게 인식하고 이해할 수 있는 능력을 의미한다.
추가 토큰 주입?
이미지나 비디오 같은 시각적인 LLM이 이해할 수 있는 형태인 토큰으로 변환하여 사용자 질문과 함께 문맥으로 밀어넣는 과정을 말한다.

1. Introduction

비디오 기반 MLLM의 정확도는 키프레임의 품질에 의존한다. VideoMME의 긴 비디오에서 녹색 별표로 표시된 키프레임을 보여준다. LLaVA-Video 같은 동일한 MLLM이 질문에 답변하는데 사용되었다. 통일 샘플링은 관련 없는 프레임을 찾으며 이 논문의 AKS는 키 프레임을 찾고 올바른 답변을 생성한다.
영상 이해 AI(MLLM)가 긴 비디오의 모든 장면을 다 볼 수 없기 때문에 질문에 답하는 데 꼭 필요한 핵심 장면(키프레임)을 똑똑하게 골라내는 것이 중요하다
키프레임?
비디오 전체 데이터 중 모델이 처리할 수 있는 용량 한계에 맞춰 선택된 일부 장면이다. AI가 영상 전체를 보지 않고도 질문에 답할 수 있도록 핵심적인 시각적 단서를 제공하는 역하를 한다.
MLLM?
시각적 입력을 텍스트와 같은 토큰 형태로 변환하여 함께 처리하는 LLM이다. 스트만 처리하던 기존 모델이 영상이나 이미지를 직접 보고 이해하며 추론할 수 있다.
최근 멀티모달 대규모 언어 모델(MLLM)은 이미지 이해를 넘어 영상 이해로 확장되고 있다.
하지만 긴 영상의 경우 영상의 모든 토큰을 MLLM의 제한된 용량에 담기 어렵다.
기존 방식은 영상의 일부 프레임만 샘플링하여 핵심 정보가 손실될 수 있다. MLLM이 부정확한 답변을 생성하는 주요 원인이 된다. 영상 이해의 정확도는 키프레임의 품질에 크게 의존한다. 기존의 균일 샘플링 방식은 중요한 정보를 놓치기 쉽다.
본 논문은 이러한 문제를 해결하기 위해 Adaptive Keyframe Sampling(AKS)이라는 간단하면서도 효과적인 알고리즘을 제안한다
키프레임 선택을 MLM의 비주얼 인코더 앞단에 플러그 앤 플레이 모듈로 공식화하며 그 목표는 비디오 이해에서 키 프레임의 유용성을 극대화하는 것.이라는 말이 뒷부분에도 나오는지 확인
2. Related Work
Large language models(LLMs) and multimodal LLMs(MLLMs)
내부 적응 방식: MLLM 내부에 교차 주의 메커니즘을 통합하여 영상 정보를 처리한다.
외부 적응 방식: 영상 이해를 위해 추가적인 모듈을 학습시킨다.
비전 기반 모델: CLIP과 같은 모델을 활용하여 영상과 언어를 정렬한다
내부? 외부?
내부: LLM의 내부 신경망 구조를 직접 수정하는 방식이다. 모델 레이어 사이사이에 영상 정보를 처리할 수 있는 기능을 끼워 넣어 통합한다
외부: 원래 LLM은 건드리지 않고 그 외부에 별도의 모듈을 추가하는 방식이다. LLM 은 그대로 둔 채 영상 정보를 언어로 번역해서 전달해주는 외부 통역사를 붙이는 것과 같다
CLIP?
인터넷 상의 수억 개의 이미지와 그를 설명하는 텍스트 쌍을 대조하며 학습된 비전 기반 모델
정렬?
시각적 데이터와 언어 데이터를 한의 통일된 특징 공간으로 모으는 과정이다.
Video-based MLLMs.
초기 연구들은 영상 프레임을 샘플링하여 MLLM에 입력했다.
VideoChat, Video-ChatGPT, LLaVA-Video 등 다양한 모델이 개발되었다.
일부 모델은 더 효율적인 영상 특징을 사용하거나 인스턴스 수준의 영상 이해를 위한 연구도 진행되었다.
MLLMsfor Long Video Understanding.
긴 영상은 더 큰 도전 과제를 제시하며 정보 손실이 심화된다.
Kangaroo, LLaVA-Video 등은 더 큰 컨텍스트 용량을 활용한다.
MovieChat은 단기 및 장기 메모리 뱅크를 사용하고 MA-LMM, VideoStreaming은 Q-former와 소형 언어 모델을 사용하여 영상 데이터를 압축한다.
LongVLM은 토큰 병합을 사용하고, Goldfish는 짧은 영상 이해를 통합한다.
이러한 접근 방식들은 영상 토큰 수를 줄이는 데 초점을 맞추지만 핵심 정보 보존을 보장하지는 못한다
3. Method
3.1. Preliminaries
AKS는 고정된 수의 영상 토큰으로 유용한 정보를 최대화하는 것을 목표로 한다.
키프레임 선택을 최적화 문제로 공식화한다.
두 가지 주요 원칙을 고려:
관련성 (Relevance):
키프레임이 프롬프트(질문)와 얼마나 관련 있는지
커버리지 (Coverage):
키프레임이 영상 전체의 유용한 정보를 얼마나 포괄하는지
이 두 가지 원칙을 최대화하는 적응형 알고리즘을 제안한다
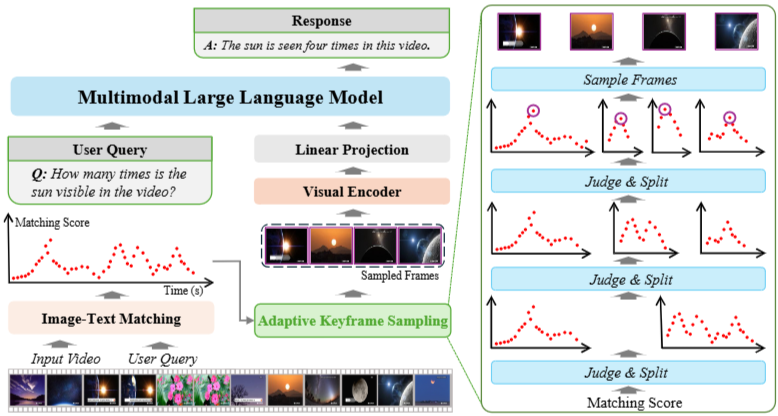
전체 프레임워크로 샘플링된 키프레임의 품질을 향상시키기 위해 플러그 앤 플레이 모듈인 AKS(녹색)을 MLLM에 넣는다. 각 빨간 점은 프롬포트-프레임 매칭 점수이다. AKS는 키프레임 선택을 위한 재귀적, 판별 및 분할 최적화를 따른다.
그림은 입력 비디오와 사용자 질의로부터 프레임별 relevance(매칭 점수)를 계산하고 이를 기반으로 재귀적(분할,판단)으로 키프레임을 선택해 MLLM에 넣어 답변을 얻는 Adaptive Keyframe Sampling(AKS)의 전체 흐름을 보여준다. 핵심은 “relevance(질의와 프레임의 연관성)”과 “temporal coverage(시간적 커버리지)”를 함께 고려해 제한된 수의 토큰 안에서 가장 유용한 프레임들을 뽑는 것이다.
입력과 초기 처리
Input Video: 원본 영상(아래 타임라인에 프레임들).
User Query: 사용자의 질문(텍스트).
Image-Text Matching: BLIP/CLIP 같은 VL 모델로 각 프레임 Ft에 대해 s(Q, Ft)라는 질의-프레임 매칭 점수를 계산 → 시간 축에 따른 점수 플롯(빨간 점들).
Adaptive Keyframe Sampling 모듈(중심)
역할: 제한된 수 M의 키프레임을 뽑아 downstream MLLM에 전달.
입력: 프레임별 매칭 점수 s(Q, Ft) + 타임스탬프 정보.
출력: 선택된 M개의 frame indices → 해당 프레임들만 Visual Encoder에 보냄.
MLLM 처리 Visual Encoder → Linear Projection → Multimodal Large Language Model에 시각 토큰과 텍스트(질의)를 주입하여 Response 생성.
이때 MLLM의 컨텍스트(토큰) 용량이 제한되어 있으므로 AKS가 사전 필터링 역할을 함.
AKS가 근사하려는 선택 문제는
$\displaystyle \operatorname{arg\,max}{|I|=M}\sum{t\in I} s(Q,F_t) + \lambda\cdot c(I)$
각 항의 의미:
$s(Q,F_t)$: 프레임 t가 질문 Q에 대해 얼마나 관련 있는지를 나타내는 학습된 매칭 점수(첫 번째 항: relevance).
$c(I)$: 선택된 인덱스 집합 I의 시간적 커버리지(중복을 줄이고 비디오 전반을 포괄하는지 측정).
$\lambda$: relevance와 coverage 사이의 균형 계수(실제 구현에서는 s_{thr} 같은 판단 기준으로 대체).
특수 전략
TOP: λ=0에 해당—단순히 s가 큰 top-M 프레임 선택(peak 잡기 좋지만 시간적으로 편중될 위험).
BIN/UNI: λ→∞에 해당—시간 구간별로 고르게 뽑음(coverage 보장되나 local peak 놓칠 수 있음).
ADA(Adaptive): 위 둘의 절충. 재귀적 분할과 판단으로 각 구간에 몇 개를 배분할지 동적으로 결정.
우측 확대(재귀적 Judge & Split) 동작 원리
단계적 처리(예시 그림의 오른쪽)
전체 타임라인을 레벨 0에서 시작해 bin으로 나눔(초기 2분할).
각 bin 내부의 매칭 점수 분포를 보고, “상위 M 평균(stop)와 전체 평균(sall)의 차이 m = stop − sall”을 계산.
만약 m ≥ s_thr(임계값)이면: 해당 bin에서 top-k(= 할당된 프레임 수)를 바로 선택(즉, 강한 피크가 있으므로 relevance 우선).
그렇지 않으면: bin을 더 세분화(split)하여 각 sub-bin에 균등하게(또는 비례하여) 프레임 할당하고 재귀 반복(coverage 우선).
최종적으로 각 segment에서 할당된 수 mi 만큼 상위 점수 프레임을 뽑아 합쳐서 M개를 완성.
설계 의도: 질문 유형에 따라 (단일 순간에 답이 모여있는 경우 vs 여러 시점의 집계가 필요한 경우) 동적으로 TOP 성향 혹은 BIN 성향으로 동작.
구현·튜닝 핵심 포인트
매칭 스코어 산출기: BLIP, CLIP, Sevila 등 사용할 수 있으며 데이터 특성에 따라 성능 차이 있음(예: 객체 중심 질문에는 BLIP 우수).
후보 프레임 샘플링 빈도: 실험에서는 1 fps로 후보를 만들었지만, 더 낮은 fps에서도 성능 유지되는 경향(속도-정확도 트레이드오프).
하이퍼파라미터: max depth L(재귀 깊이), s_thr(판단 임계값), 그리고 M(MLLM이 허용하는 프레임 수). L, s_thr는 데이터셋 특성(집중된 순간 vs 분산된 사건)에 맞춰 조정.
계산 비용: AKS는 VL scorer를 한 번만 후보 프레임들에 대해 돌리는 전처리 단계이므로 전체 MLLM 파이프라인에 비해 비용이 상대적으로 작음.
왜 성능이 좋아지는가(직관적 이유)
중요 정보(질의 관련 프레임)를 놓치지 않으면서 시간적으로도 넓게 분포된 증거를 확보 → MLLM이 질문에 필요한 모든 컨텍스트를 받게 됨.
동일한 M 제한 내에서 중복(비슷한 프레임들) 선택을 줄여 정보 효율을 높임.
질문에 따라 다른 키프레임 세트를 선택하므로(프롬프트-의존적) 고정 샘플링보다 유연함.
실전 예시: 단일 순간 질문 vs 집계형 질문 단일 순간(예: “남자가 무엇을 하고 있는가?”) → ADA는 TOP 성향으로 피크를 우선 선택.
집계형(예: “태양이 몇 번 보이는가?”) → ADA는 BIN 성향으로 여러 시간구간에서 균형 있게 샘플링.
확장성 및 한계(간단히) 장점: 플러그앤플레이, 다양한 MLLM에 적용 가능, 다른 비디오 태스크(리퍼링·캡셔닝)에도 유용.
한계: VL scorer 품질에 의존, 후보 프레임 샘플링 빈도가 너무 낮으면 정보 손실 가능, 매우 복잡한 시간적 관계(예: 긴 인과 관계)는 단순 점수+분할로는 한계가 있을 수 있음.
여기 나중에 확인하기
플러그 앤 플레이 모듈?
기존 시스템(MLLM)의 내부 구조를 수정하거나 모델을 다시 학습시킬 필요 없이 필요한 위치에 끼워 넣기만 하면 바로 성능을 높여주는 독립적인 장치를 의미한다
AKS는 MLLM의 비전 인코더 앞에 플러그 앤 플레이 모듈로 삽입된다.
MLLM은 영상 토큰과 텍스트 지침을 동일한 특징 공간으로 투영하여 처리한다.
동일한 특징공간? 어떻게?
동일한 특징 공간은 이미지와 텍스트라는 서로 다른 형태의 데이터를 AI가 동시에 이해할 수 있도록 한데 묶은 공통의 수학적 영역을 의미한다
Vision Encoder를 사용하여 영상의 각 프레임을 수치화된 비주얼 토큰으로 변환한다.
추출된 비주얼 토큰을 MLP(Multi-Layer Perceptron)라는 연결망에 통과시켜 텍스트 토큰과 규격을 맞춘다.
이 과정을 거치면 시각 정보가 LLM의 문맥에 자연스럽게 삽입되어 모델이 영상과 질문을 하나의 문장처럼 처리할 수 있게 된다.
긴 영상의 경우 모든 영상 내용을 MLLM이 처리할 수 없다는 문제가 있다.
AKS는 이러한 문제를 해결하기 위해 영상에서 최적의 키프레임을 선택한다.
3.2. Principles of Keyframe Selection
관련성 측정:
프롬프트와 각 후보 프레임 간의 관련성을 비전-언어(VL) 모델을 사용하여 계산한다.
비전 언어 모델?
이미지(시각)와 텍스트(언어)라는 서로 다른 형태의 데이터를 동시에 처리하고 두 정보 사이의 관계를 파악하도록 설계된 AI 모델이다
키프레임의 품질이 영상 이해에 매우 중요하다.
커버리지 측정:
영상 전체를 여러 구간으로 나누어 키프레임이 얼마나 잘 분포되어 있는지 평가한다.
이는 중복되는 프레임을 방지하고 정보 손실을 줄이는 데 도움이 된다.
최적화 목표:
관련성과 커버리지의 균형을 맞추는 것을 목표로 한다.
$s(Q,F_t)$: 프롬프트와 프레임 간의 관련성
$c(I)$: 키프레임 세트의 커버리지
$\lambda$: 관련성과 커버리지 간의 균형을 조절하는 하이퍼파라미터
수식 더 자세하게.
3.3. Aaptive Keyframe Sampling
최적화 방식:
단순히 관련성이나 커버리지만을 최대화하는 것은 최적의 결과를 보장하지 않는다.
AKS는 관련성과 커버리지 간의 적절한 균형을 통해 최적의 키프레임 선택을 달성한다.
재귀적 분할 및 최적화 방식을 사용한다.
커버리지 측정:
균일성(homogeneity)을 측정하는 Ripley’s K-함수를 활용한다.
시간 축을 구간으로 나누어 각 구간의 키프레임 수를 고려한다.
근사 최적화:
수학적으로 복잡한 최적화 문제를 해결하기 위해 휴리스틱 방법을 사용한다.
계층적 최적화 방법을 통해 관련성과 커버리지의 균형을 맞춘다.
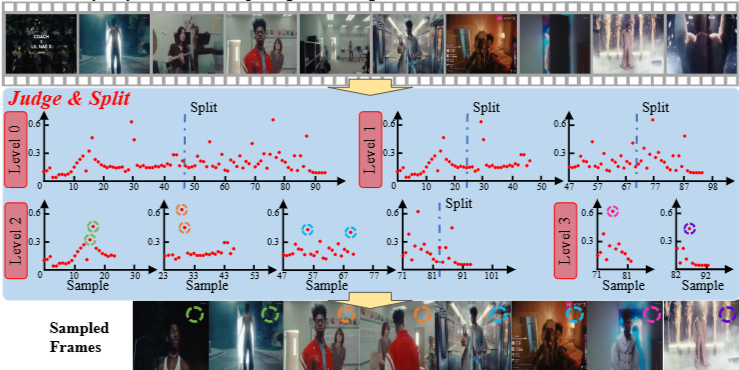
세 가지 샘플링 전략:
TOP: 관련성 점수가 가장 높은 프레임을 선택한다.
BIN: 각 구간에서 가장 높은 점수의 프레임을 선택한다.
ADA (Adaptive Sampling): TOP과 BIN 전략의 장점을 결합하여 최적의 결과를 달성한다.
적응형 샘플링(ADA)의 예시이다. 입력 비디오에서 8개의 키프레임이 선택된다. 각 빨간 점은 프롬프트-프레임 매칭 점수, $s(Q, F_t)$를 나타낸다. Level 0 및 Level 1에서는 모든 구간이 두 개의 하위 구간으로 분할된다. Level 2에서는 가장 오른쪽 구간만 추가로 분할되며 상위 2개의 점수는 나머지 세 구간에서 샘플링됩니다. Level 3는 최대 깊이에 도달했다.
프롬포트-프레임 관련 점수 $s(Q, F_t)$ 를 기반으로 비디오 타임라인을 재귀적으로 분할하여 relevance 와 coverage를 균형있게 확보한 키프레임을 선택하는 과정을 보여준다.
상단 필름스트립
입력 비디오의 타임라인을 단순히 나열한 것. 전체 후보 프레임 집합의 시각적 맥락을 보여준다.
중앙의 여러 레벨(Level 0 → Level 3)
각 작은 플롯은 시간축(가로축, 샘플 인덱스) 대비 프롬프트-프레임 매칭 점수(세로축, 빨간 점들)를 표시한다.
Level 0: 전체 타임라인의 스코어 분포를 한 번에 보고, 첫 판단(Judge)에서 분할(Split) 여부를 결정합니다.
분할 기준: 전체에서 상위 M 프레임의 평균 점수 stop과 전체 평균 sall의 차이 m = stop − sall이 사전정한 임계값 sthr보다 크면(= 특정 순간에 강한 피크가 존재하면) 전체에서 상위 프레임(TOP)들을 바로 선택. 그렇지 않으면 구간을 균등히 쪼개어 커버리지를 확보하기 위해 재귀적으로 분할한다.
Level 1, 2, 3: 상위 레벨에서 분할된 서브-구간들 각각에 대해 동일한 판정을 반복 — 어떤 구간은 더 쪼개지고(coverage 강화), 어떤 구간은 쪼개지지 않고 상위 점수 프레임을 뽑는다(relevance 보장).
색 원형/마커의 의미
각 레벨에서 강조된 피크(색 원)들은 해당 서브-구간에서 최종적으로 선택된 후보(또는 선택 우선순위)를 나타낸다. 동일 색상은 같은 분할 경로(같은 서브-구간)에서 선택된 프레임을 연결한다.
하단의 Sampled Frames
최종 선택된 키프레임들을 실제 이미지로 보여준다. 위의 각 색 마커는 하단의 선택 프레임에 대응되어 어느 타임구간의 어떤 피크가 선택되었는지 한눈에 알 수 있게 한다.
무슨말인지 잘 풀어서 이해하기
4. Experiments
4.1. Experimental Setup and Details
데이터셋: LongVideoBench (LVB) 및 VideoMME 를 사용했다.
기반 모델: Qwen2-VL, LLaVA-OV, LLaVA-Video 세 가지 영상 기반 MLLM을 사용했다.
평가 방식: AKS를 각 기반 모델에 적용하여 영상 질의응답(Video QA) 정확도를 측정했다.
프레임 샘플링 빈도: 1초당 1개의 프레임을 샘플링했다.
4.2.Comparison to the State-of-the-Art
실험에서 기본적으로 ADA(adaptive) 샘플링을 사용했고 AKS(Adaptive Keyframe Sampling)를 세 가지 기존 비디오 기반 MLLM에 플러그인하여 일관되게 성능 향상을 얻었다는 정량, 정성 결과를 보여준다.
We use ADA sampling unless otherwise specified.
실험 전반에서 키프레임을 뽑을 때 기본 전략으로 ADA(Adaptive Sampling)를 사용했다는 뜻이다. ADA는 논문에서 제안한 방법으로 각 프레임과 질문 간의 relevance(s(Q,Ft))와 시간적 coverage를 균형 있게 고려해 키프레임을 적응적으로 배분한다.
별도 표기나 ablation에서 다른 샘플링(TOP, BIN, UNI)을 쓴 경우를 제외하면 모든 실험 결과는 ADA 기반이다.
ADA랑 AKS랑 같은거? 포함관계 AKS가 전체 알고리즘의 이름이라면 ADA는 그 안에서 실제로 장면을 골라내는 핵심적인 방법이다.
AKS는 다음과 같이 여러 가지 샘플링 전략들을 하위 개념으로 포함하고 있다.
TOP (Top Sampling): 질문과 가장 관련 있는 장면만 순서대로 뽑는 방식 (커버리지 무시).
BIN (Binned Sampling): 영상을 구간별로 나누어 각 구간에서 대표 장면을 하나씩 뽑는 방식 (커버리지 보장).
ADA (Adaptive Sampling): 상황에 맞춰 TOP과 BIN의 장점을 섞은 방식 (논문에서 권장하는 베스트 프랙티스).
Quantitative results.
사용한 벤치마크: LongVideoBench와 VideoMME (긴 비디오 QA에 적합한 데이터셋).
베이스라인 MLLMs: Qwen2-VL, LLaVA-OV, LLaVA-Video (모델 파라미터는 주로 7B급).
비교 방식: 기존 MLLM들의 내부 파라미터나 LLM은 그대로 유지하고, 입력으로 넣는 프레임 집합만 AKS로 교체(plug-and-play).
부가 정보 차단: 실험에서 자막(subtitles) 등 텍스트 보조 정보를 사용하지 않아 시각 정보만으로 성능 차이를 평가.
후보 프레임 전처리: 원본 영상에서 1 fps로 후보 프레임을 샘플링하고, BLIP ITM(vision-language scorer)으로 s(Q,Ft)를 계산해 AKS에 입력.
입력 프레임 수: 모델별로 16/32/64 등 제한에 맞춰 M 프레임을 사용.
후보 프레임 전처리: 원본에서 1 fps로 후보 추출 → 각 후보에 대해 VL 모델(BLIP 기본)을 이용해 prompt-frame relevance s(Q, F_t) 계산 → AKS(ADA)로 M개 선택.
평가: MLLMs는 그대로 두고, AKS로 선택한 키프레임을 입력해 QA 정확도 비교. 자막(subtitles)은 사용하지 않음(시각 정보에 집중).
BLIP
시각과 언어를 통합적으로 이해하고 생성하기 위해 개발된 비전-언어 모델이다. 이미지 내용을 설명하거나 반대로 텍스트 설명을 듣고 그에 맞는 이미지를 찾아내는 멀티모달 작업을 한다.
MLLM을 직접 사용하면 연산 비용이 너무 높기 때문에 각 프레임의 중요도를 빠르게 매길수 있는 가벼운 scorer로 BLIP을 활용했다.
ITM
이미지-텍스트 매칭. 이미지와 텍스트가 서로 관련이 있는지 그 유사도 점수를 매기는 작업이다. 이미지 토큰과 텍스트 토큰을 비교하여 두 데ㅣ터가 얼마나 의미적으로 가까운지 확률이나 점수로 출력한다.
BLIP ITM BLIP 모델의 매칭 기능을 사용하여 비디오의 각 장면이 질문에 답하는 데 얼마나 핵심적인 정보인지 수치화하는 도구이다. BLIP ITM 점수가 높은 장면을 우선적으로 골라내어 모델의 정답률을 높인다.

LongVideoBench (LVB) val 및 VideoMME (V-MME)에서의 다양한 접근 방식별 비디오 기반 질의응답 정확도 (%). AKS는 세 가지 기본 접근 방식에 적용되었다. Frames와 LLM은 각각 MLLM에 공급되는 비디오 프레임 수와 LLM 부분의 파라미터 수를 나타낸다.
다양한 모델과 샘플링 방식에서 긴 비디오 질문답변 성능(정확도, %)을 비교한 것으로 AKS(Adaptive Keyframe Sampling)를 기존 7B급 MLLM에 적용하면 프레임 수를 늘리지 않고도 일관되게 성능이 향상됨을 보여준다.
의의: 같은 모델-파라미터 조건(7B, 64 frames)에서 AKS를 적용한 모델이 외부의 더 큰 모델에 근접하거나 더 좋은 성능을 기록한 사례가 있어 시각적 전처리(키프레임 선택)만으로도 실효성 있는 성능 향상이 가능함을 보여준다.
주목할 점: LLaVA-Video-7B + AKS(62.7% on LVB) 성능은 더 큰/긴 컨텍스트를 쓰지 않은 일부 대형 모델(예: LLaVA-Video-72B, GPT-4V, Gemini-1.5-Flash)과 비슷하거나 더 좋게 비교됨 — 즉, 동일한 컨텍스트 예산 하에서 더 좋은 키프레임 선택만으로 경쟁력 확보 가능.
표 상단의 GPT-4V/GPT-4o/Gemini 등은 256 프레임을 사용한 강력한(대개 내부·상업용) 모델들로, 프레임 수가 많아 비교적 높은 성능을 보임.
하단의 Qwen2‑VL, LLaVA‑OV, LLaVA‑Video 등은 공개/연구용 모델(주로 7B)이며, AKS를 적용한 경우와 비교해 성능 향상을 보고함.
7B LLM? 밑에 있는 LLaVA 프레임을 늘리면 안되는건가?
70억(7 billion)개의 대형 언어모델
LLM은 동시 처리할 수 있는 토큰 수(4k, 8k, 32k 등)에 제한이 있음. 비디오에서 프레임을 늘리면 시각 토큰 수가 급격히 늘어 컨텍스트 한계를 넘기기 쉽다.
그렇다면 GPT 256?
대부분은 “프레임 → 시각 인코더 → 임베딩”의 흐름을 택함. 각 프레임이 1개(혹은 소수)의 벡터로 요약되면 256개의 벡터(토큰)는 LLM이 다룰 수 있음.
일부 상용/대형 모델은 32k, 64k 등 매우 긴 토큰 창을 지원하도록 설계/학습되었음. 이 경우 더 많은 토큰을 한 번에 처리 가능.
V-MME보다 LVB에서 왜 상승 폭이 더 큰가?
VideoMME는 전반적인 맥락을 묻는 질문이 많아 균등 샘플링도 어느 정도 방어하지만 LongVideoBench는 특정 찰나를 놓치면 절대 풀 수 없는 질문이 많다. AKS의 Relevance(연관성) 기반 추출 영향이다
Qualitative results.

AKS는 기본 MLLM의 비디오 이해 능력을 향상시킨다. 왼쪽 세 개의 예시는 LongVideoBench에서 가져왔으며 오른쪽 세 개는 VideoMME에서 가져왔다. 녹색 별표는 AKS에 의해 선택된 키프레임을 나타낸다 (각 비디오마다 64개의 키프레임이 선택된다).
구성: 2열×3행(총 6개 사례). 각 사례는 영화 필름처럼 연속 프레임들을 보여주고 초록 별★은 AKS가 선택한 키프레임 위치를 표시한다.
각 사례 아래에는 두 줄의 결과가 있음:
첫 줄: baseline(기본 샘플링) 모델 답변(빨간 × 는 오답)
둘째 줄: 같은 모델에 AKS를 적용했을 때의 답변(초록 ✓ 는 정답)
목적: 같은 모델, 같은 비디오에서 입력되는 프레임만 바뀌었을 때 답이 어떻게 달라지는지 시각적으로 비교.
relevance: VL 모델(BLIP 등)을 이용해 각 프레임과 질문 Q 간 유사도 s(Q, Ft)를 계산 → 질문 관련성이 높은 프레임 우선 고려.
coverage: 비디오를 재귀적으로 분할(bin)해 각 시간구간에 키프레임이 고르게 분포하도록 유도 → 중복/밀집 선택 방지.
ADA(Adaptive Sampling): relevance와 coverage 사이의 균형을 동적으로 조절해 TOP(단순 상위 선택)과 BIN(구간별 챔피언) 장점 모두 흡수.
결과: 같은 MLLM, 같은 토큰 예산 하에서 더 정보성 높은 입력을 제공하여 답 정확도 향상.
bin
영상을 시간 순서대로 쪼갠 것
100프레임짜리 영상을 2개로 나누었다면 $0{\sim}50$번 프레임이 들어있는 구간이 첫 번째 bin, $51{\sim}100$번이 들어있는 구간이 두 번째 bin
AKS가 선택한 키프레임은 질문과 관련된 순간을 더 잘 포착 → 제한된 컨텍스트 안에서 질문에 필요한 정보 집중 제공 → MLLM이 올바른 답을 생성할 확률 증가.
LongVideoBench 문제들은 종종 특정 순간에 집중된 질문(단일 모먼트 중요) → TOP(상위 점수 선택)이 유리한 경우 많음.
VideoMME는 여러 시점에서 정보를 모아야 하는 문제(멀티-모먼트) 비중이 높아 BIN(시간적 분포 보장)이 유리한 경우 많음.
ADA는 이 둘의 장점을 적응적으로 결합해 양쪽에서 우수한 성능을 냄.
그림에서 AKS가 질문 관련성이 높은 프레임을 더 잘 찾아내며 이에 따라 MLLM의 답변 질이 개선되는 장면이 다수 제시된다.
LongVideoBench는 단일 순간 집중형 질문이 많아 고점(top peaks)을 잡는 전략이 도움되는 경우가 많고 VideoMME는 다중 순간을 집계해야 하는 질문이 많아 시간적 분포를 보장하는 편이 유리함. ADA는 두 특성 사이를 적응적으로 균형시켜 전체적으로 우수한 성능을 낸다.
AKS는 모델 구조 변경이나 대규모 파라미터 증강 없이도 유한한 컨텍스트(capacity) 내에서 더 유용한 시각 토큰을 제공함으로써 MLLM의 긴 비디오 이해 능력을 향상시킨다. 따라서 긴 비디오 및 고차원 시각 데이터 처리에서는 pre-filtering—질문 관련성과 시간적 커버리지를 고려한 키프레임 선택—이 매우 중요한 설계 요소임을 시사한다.
4.2 제대로
4.3.Diagnostic on Keyframe Selection
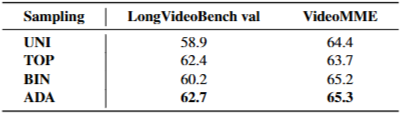
다양한 샘플링 전략별 비디오 기반 질의응답 정확도 (%). LLaVA-Video-7B에 AKS를 적용하여 테스트했습니다. 이 약어들에 대한 설명은 섹션 3.3을, 결과 분석은 섹션 4.3을 참고.
정성적 결과: AKS로 선택된 키프레임은 질문과 밀접하게 관련되어 있어 MLLM이 정확한 답변을 생성하는 데 도움을 준다.
네 가지 키프레임 샘플링 전략(UNI, TOP, BIN, ADA)을 LLaVA-Video-7B에 적용했을 때 LongVideoBench(val)와 VideoMME에서의 QA 정확도(%)를 비교한 결과입니다. 결론적으로 ADA(Adaptive Sampling)가 두 데이터셋 모두에서 가장 높은 성능을 보여, relevance와 coverage를 균형있게 고려하는 방법이 효과적임을 보인다
샘플링 전략 비교:
AKS의 기본 선택 방식인 ADA가 가장 좋은 성능을 보였다.
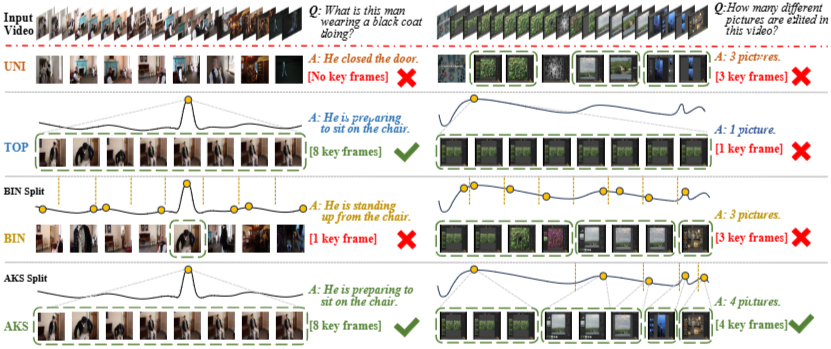
샘플링 전략이 비디오 이해에 미치는 두 가지 예시. 왼쪽 경우는 LongVideoBench(한 순간에 집중)에서, 오른쪽 경우는 VideoMME(여러 순간에 의존)에서 가져왔습니다. 각 곡선은 시간 경과에 따른 s(Q, F_t)s(Q,Ft)s(Q, F_t)s(Q,Ft) 점수를 보여주며 노란색 원은 샘플링된 키프레임의 위치를 나타낸다. 또한 답변 아래에 실제 키프레임 수와 각 실패 사례의 이유를 주석으로 달았다.
그림은 서로 다른 키프레임 샘플링 전략(UNI, TOP, BIN, AKS)이 같은 긴 비디오와 질문에 대해 어떻게 다른 프레임을 골라내고 그에 따라 MLLM의 정답 여부가 어떻게 달라지는지 한눈에 보여준다. 결론적으로 AKS는 relevance(프롬프트-프레임 유사도)와 temporal coverage(시간적 분포)를 동시에 고려해 두 사례 모두에서 올바른 프레임을 골라 정답을 얻는다
TOP과 BIN 전략은 특정 벤치마크에서 더 나은 성능을 보이기도 했다.
질문 유형에 따른 키프레임 선택:
LongVideoBench의 질문은 특정 순간에 초점을 맞추는 경향이 있어 TOP 샘플링이 효과적이다.
VideoMME의 질문은 여러 순간의 정보를 종합해야 하므로 BIN 샘플링이 안전한 선택이다.

AKS는 질문에 따라 다른 키프레임 세트를 선택하여 유연성을 높인다
이 그림은 같은 긴 영상(Input Video)에 대해 서로 다른 질문(Q)에 따라 AKS(Adaptive Keyframe Sampling)가 각기 다른 키프레임 집합을 골라 MLLM이 정확한 답을 하도록 돕는 정성적 사례이다.
4.4.Ablative Studies
AKS의 실용성(연산 비용 절감)과 설계 선택(프레임 후보 빈도, VL scorer, ADA 하이퍼파라미터)이 성능에 미치는 영향을 실험적으로 검증해, AKS가 다양한 환경에서 유연하게 이득을 준다는 것을 보인다.
실험 항목(세 가지)
프레임 후보 샘플링 빈도: 후보 프레임을 얼마나 촘촘히 뽑아야 하는지 비교.
VL scorer 선택: s(Q, F_t) 점수를 계산할 때 쓸 비전-언어 모델에 따른 차이.
ADA 하이퍼파라미터(L, sthr): 재귀 분할 깊이 L과 top-frame 우선 결정을 내리는 임계값 sthr에 따른 민감도.
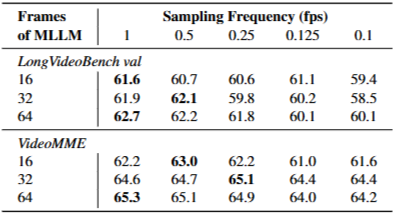
다양한 샘플링 빈도에 따른 질의응답 정확도(%). LLaVA-Video-7B가 MLLM으로 사용된다.
프레임 후보 빈도 결과 요약
목적: AKS가 추가 계산(프레임별 VL 매칭)을 요구하므로 후보 개수를 줄여 효율성-성능 균형을 찾음.
주요 관찰
LongVideoBench에서는 매우 낮은 빈도(0.1 fps)에서도 기존 균일 샘플링보다 성능이 높게 유지됨. 즉, 후보를 드라마틱하게 줄여도 AKS는 유의미한 이득을 제공. VideoMME에서는 0.25 fps 정도가 실용적으로 보임.
의미: 후보 빈도를 낮춰도 AKS의 relevance+coverage 전략이 핵심 프레임을 잘 찾아내므로 연산 부담을 상당히 줄일 수 있음.
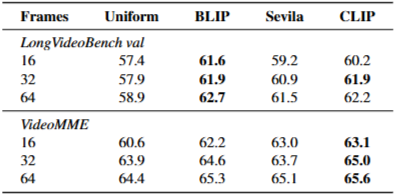
다양한 VL 스코어러에 따른 질문 답변 정확도 (%). LLaVA-Video-7B는 MLLM으로 사용된다.
VL scorer(점수 계산기) 영향
실험 결과: BLIP가 LongVideoBench에서 더 좋고 CLIP이 VideoMME에서 더 좋은 경향을 보임(Sevila는 중간 수준).
이유 해석
BLIP은 object/세부 묘사에 강한 학습 특성을 가짐 → LongVideoBench의 질문들이 객체 중심이거나 특정 순간에 집중되는 특성과 잘 맞음. CLIP은 대규모 일반 이미지-텍스트 쌍으로 학습되어 전반적/글로벌 장면 관련성 측정에 강함 → VideoMME의 다중 순간·전반 인지 문제와 시너지가 있음.
Sevila?
vision–language 모델로, 이미지-문장 매칭(ITM) 및 비디오 내 localization 관련 작업에 초점을 둔 scorer이다. AKS에서는 이 모델을 s(Q, F_t)를 계산하는 VL scorer로 사용해 프롬프트-프레임 관련성을 측정했다.
BLIP/CLIP보다 항상 최고는 아니었지만 보통 중간 이상의 성능을 보였다.
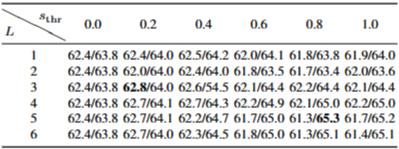
L과 sthr 동시 제거. 왼쪽: LVB, 오른쪽: V-MME
ADA 하이퍼파라미터(L, sthr) 영향
파라미터 설명
L: 재귀로 분할하는 최대 레벨(깊이). 깊을수록 더 세밀하게 시간축을 쪼개어 coverage를 보장하려 함.
sthr: “stop-and-take-top-M” 결정을 내리는 임계값. stop − sall(상위 M 평균 − 전체 평균)이 sthr 이상이면 top-M를 바로 선택.
결과 요약
LongVideoBench는 작은 L, 작은 sthr를 선호(정보가 한두 순간에 집중되어 있어 너무 많은 분할이 오히려 손해).
VideoMME는 비교적 큰 L, 큰 sthr가 유리(정보가 여러 시점에 걸쳐 흩어져 있어 coverage 확보가 중요).
해석: ADA는 TOP(점수 우선)과 BIN(시간 균등) 사이를 적응적으로 조절하는데, L과 sthr로 그 균형을 제어함. 데이터 특성에 맞춰 튜닝하면 성능 최적화 가능.
밑에 포함할지 말지 보기 AKS는 후보 프레임 수를 줄여도(연산 절감) 장점 유지: 실무에서 0.25 fps 정도로 낮춰도 좋은 균형을 기대할 수 있음(데이터셋 성질에 따름).
VL scorer는 데이터셋 특성에 맞춰 선택: 객체·단일 순간 중심이면 BLIP, 전반적/다중 순간이면 CLIP 권장.
ADA 파라미터는 데이터 특성(집중된 사건 vs 분산된 사건)에 따라 L과 sthr를 조절하면 최적 성능 달성.
AKS의 하이퍼파라미터인 $\lambda$ (또는 $s_{thr}$)의 영향을 분석했다.
LongVideoBench는 VideoMME보다 더 작은 $\lambda$ 값을 선호하는 경향을 보였다.
이는 LongVideoBench의 정보가 특정 순간에 집중되어 있는 반면 VideoMME는 더 다양한 정보를 요구하기 때문이다.
LongVideoBench
영상 길이가 매우 길다. 사건이나 단서가 특정 순간에 몰려 있는 질문이 다수 존재
VideoMME
멀티모달 LLM이 비디오 전반의 복합적 정보를 얼마나 잘 종합하는지 포괄적으로 평가하기 위해 고안된 벤치. 복수 시점 정보를 요구하는 문제 포함
4.5.Generalization to Other Tasks

AKS의 비디오 참조 및 캡셔닝 확장. Baseline 결과는 uniform keyframe sampling을 통해 생성된다. 빨간색 및 녹색 텍스트는 잘못된 설명과 올바른 설명을 나타낸다.
AKS(Adaptive Keyframe Sampling)가 동일한 MLLM에 대해 uniform(또는 잘못된) 프레임 선택보다 질문(prompt)에 맞는 핵심 프레임을 골라서 referring(대상 지칭)과 captioning(요약)에서 더 정확한 답변을 유도함을 보여준다.
AKS는 video referring 및 captioning과 같은 다른 영상 이해 작업에도 쉽게 적용될 수 있다.
LLaVA-Video-7B 모델을 사용하여 프롬프트를 변경하고 옵션을 제거하여 실험했다.
정성적 결과는 AKS가 긴 영상에 대한 포괄적인 설명을 생성하는 데 중요한 역할을 함을 보여준다
5.Conclusions
MLLM의 긴 영상 이해 능력을 향상시키는 데 초점을 맞추었습니다.
제안된 AKS 알고리즘은 비전-언어 모델을 사용하여 관련성을 추정하고 적응형 최적화 알고리즘을 통해 키프레임의 커버리지를 관리한다.
정량적, 정성적 연구를 통해 AKS의 효과성을 입증했다.
AKS는 다양한 MLLM에 유연하게 적용될 수 있으며 더 나은 결과를 달성한다.
본 연구는 영상 이해를 위한 사전 필터링 단계의 중요성을 강조한다