[머신러닝] 3. 심화 | 다중회귀와 변수 관계
다중회귀분석
여러 개의 특성을 사용한 선형 회귀를 다중회귀라고 부릅니다.

적합한 변수가 누락되었을 때 다중회귀분석에 영향
중요한 변수가 회귀 모델에서 빠지게 되면 그 변수와 관련된 다른 변수들의 회귀계수 추정치가 왜곡될 수 있습니다. 모델이 실제 관계를 정확하게 반영하지 못하게 됩니다.
중요한 변수가 누락되면 상수항도 편향될 수 있습니다. 이는 모델의 예측값이 실제 값과 차이 나게 만듭니다.
누락된 변수로 인해 포함된 변수의 분산 추정치도 편향될 수 있습니다. 이는 가설 검정의 결과를 신뢰할 수 없게 만듭니다. 중요한 변수가 누락되면 모델의 신뢰성과 정확성이 떨어지게 됩니다. 예측 결과에 대한 신뢰도가 떨어지게 됩니다.
누락된 변수로 인해 오차가 증가할 수 있습니다. 이는 모델의 예측 정확도를 저하시킵니다.
중요한 변수가 누락되면 모델의 신뢰성과 정확성이 떨어지게 됩니다.
이러한 이유로 다중회귀분석을 수행할 때는 가능한 모든 중요한 변수를 포함하는 것이 중요합니다.
부적합한 변수가 추가되었을 때 영향
상관성이 낮은 변수
불필요한 변수가 추가되더라도 다른 변수들의 회귀계수 추정치는 여전히 정확합니다.
다른 변수들의 추정치는 크게 변하지 않습니다. 따라서 가설 검정은 여전히 유효합니다.
하지만 불필요한 변수가 추가되면, 불필요한 변수를 포함하지 않을 때부다 추정 계수가 커집니다. 즉, 모델의 효율성이 떨어집니다.
불필요한 변수가 많아지면 모델의 결과를 해석하는 데 어려움이 생길 수 있습니다. 이는 의사결정에 혼란을 초래할 수 있습니다.
불필요한 변수가 추가되면 모델의 효율성이 떨어지지만, 기본적인 추정치와 가설 검정의 유효성은 유지됩니다.
다중회귀분석을 수행할 때는 적절한 변수 선택이 매우 중요합니다.
상관성이 높은 변수
- 다중공선성은 입력변수들 간의 상관관계가 존재하므로, 회귀 계수의 분산을 크게 한다.
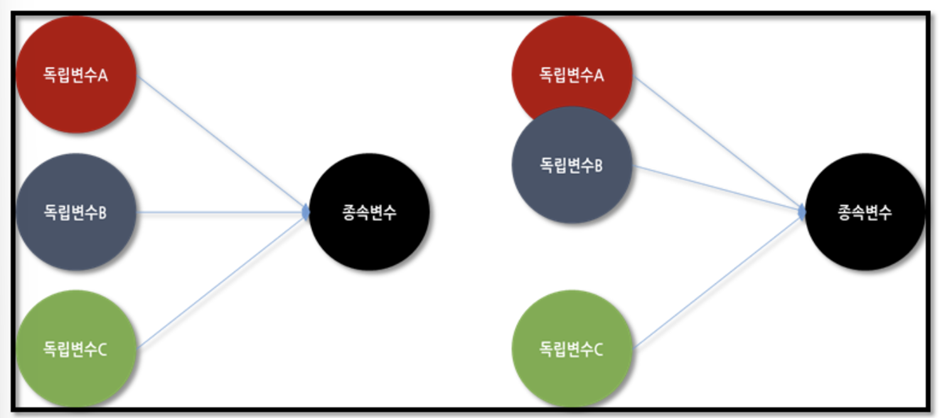
이는 회귀 분석으로 나온 추정 회귀 계수의 신용을 없앤다. 왼쪽은 변수들간의 독립성이 있는 모습을, 오른쪽은 A,B가 부분적으로 독립성이 훼손되었다고 판단할 수 있다.
다중공선성을 해결하기 위해 아래와 같은 과정을 거칠 수 있다.
- 제거 : 상관관계가 높은 독립변수나 그룹 중의 일부를 제거
- 변형 : 변수를 변형하거나 새로운 관측치를 이용한다.
- 이유 파악 : 자료를 수집하는 현장의 상황을 보아 상관관계의 이유를 파악한다.
- 변수 규제 or 선택: PCA(Principle Component Analysis)와 능형회귀분석(Ridge Regression)과 같은 추정 방법을 사용한다.
다중 회귀 모델에서 PolynomialFeatures를 사용하는 경우, 특히 degree가 2보다 큰 경우는 주로 다항 회귀 (Polynomial Regression)를 적용합니다.
복잡한 데이터 패턴 모델링 데이터가 직선이 아닌 곡선일 때 다항 회귀를 사용하면 더 정확한 모델을 만들 수 있습니다.
이 활용 예시를 더 자세하게 알아보도록 하겠습니다.
주택 가격 예측: 주택의 크기, 방의 개수, 위치 등 여러 변수를 고려하여 주택 가격을 예측할 때 변수들 간의 비선형 관계를 모델링하기 위해 사용할 수 있습니다.
주식 시장 예측: 주식 가격의 변동을 예측할 때 과거 데이터와 여러 경제 지표 간의 복잡한 관계를 모델링하기 위해 다항 회귀를 사용할 수 있습니다.
자동차 연비 예측: 엔진 크기, 차량 무게, 연료 유형 등 여러 변수를 사용하여 자동차의 연비를 예측할 때, 다항 회귀를 통해 복잡한 상호작용을 모델링할 수 있습니다.
의료 데이터 분석: 환자의 나이, 체중, 혈압 등 여러 변수를 사용하여 특정 질병의 발병 확률을 예측할 때, 다항 회귀를 사용하여 비선형 관계를 모델링할 수 있습니다.
마케팅 분석: 광고 비용, 프로모션, 계절성 등 여러 변수를 사용하여 판매량을 예측할 때, 다항 회귀를 통해 복잡한 상호작용을 모델링할 수 있습니다.
기후 데이터 분석: 온도, 습도, 바람 속도 등 여러 변수를 사용하여 기후 변화를 예측할 때, 다항 회귀를 사용하여 비선형 관계를 모델링할 수 있습니다.
다항 회귀는 다양한 분야에서 비선형 관계를 모델링하고 예측 성능을 향상시키기 위해 활용됩니다
예제 코드
변수간의 다중공선성을 살펴보기 위해 공차, VIF값으로 판단해야 합니다.
데이터 파악하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
from statsmodels.datasets.longley import load_pandas
import statsmodels.api as sm
from sklearn.model_selection import train_test_split
from statsmodels.stats.outliers_influence import variance_inflation_factor
plt.rc('font',family='NanumBarunGothic')##한글 폰트
dfy = load_pandas().endog
dfX = load_pandas().exog
df = pd.concat([dfy,dfX],axis=1)
sns.pairplot(dfX)
plt.show()
# 선형성을 띄는 것을 볼 수 있다.
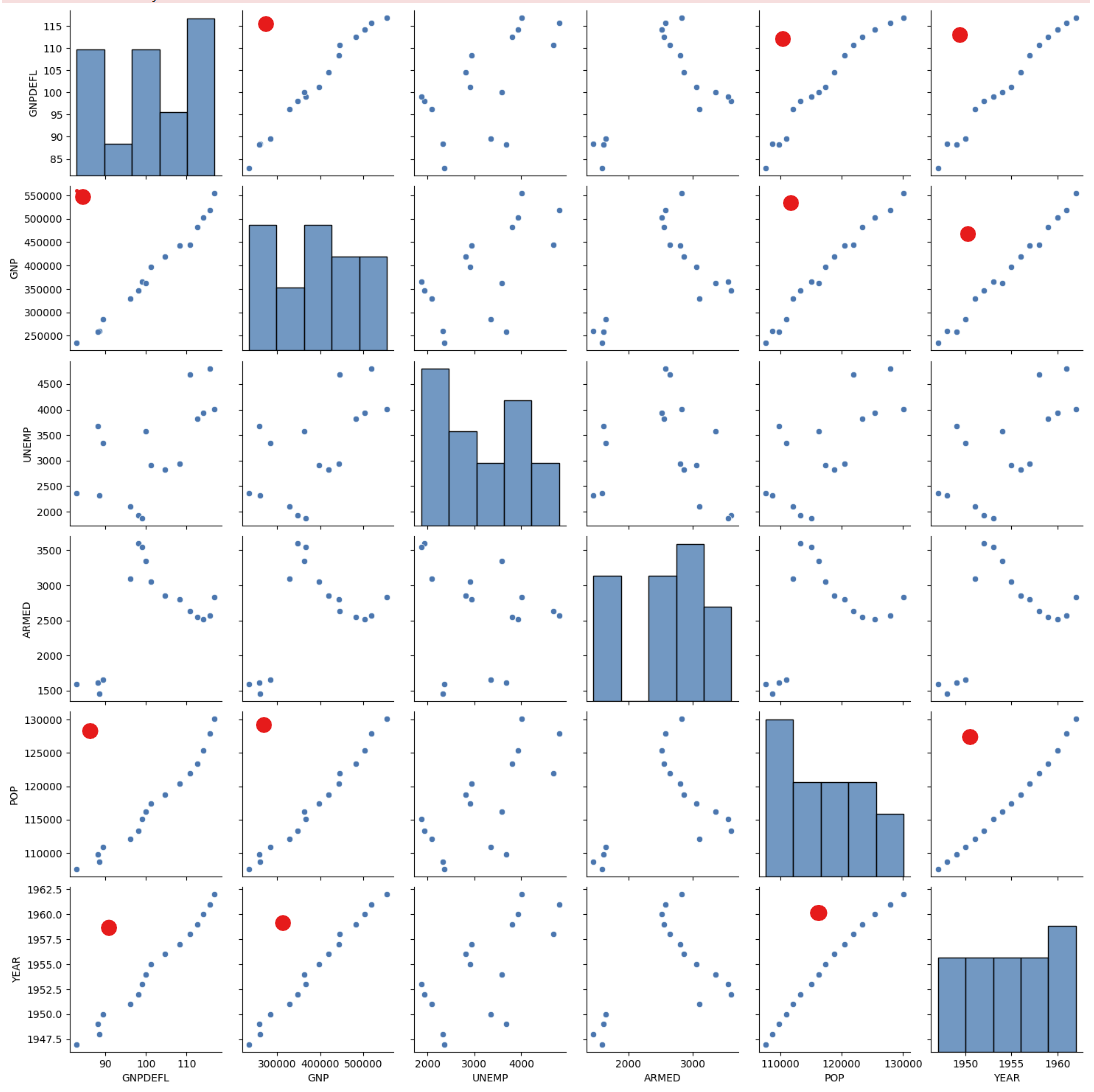
데이터 상관성 파악하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
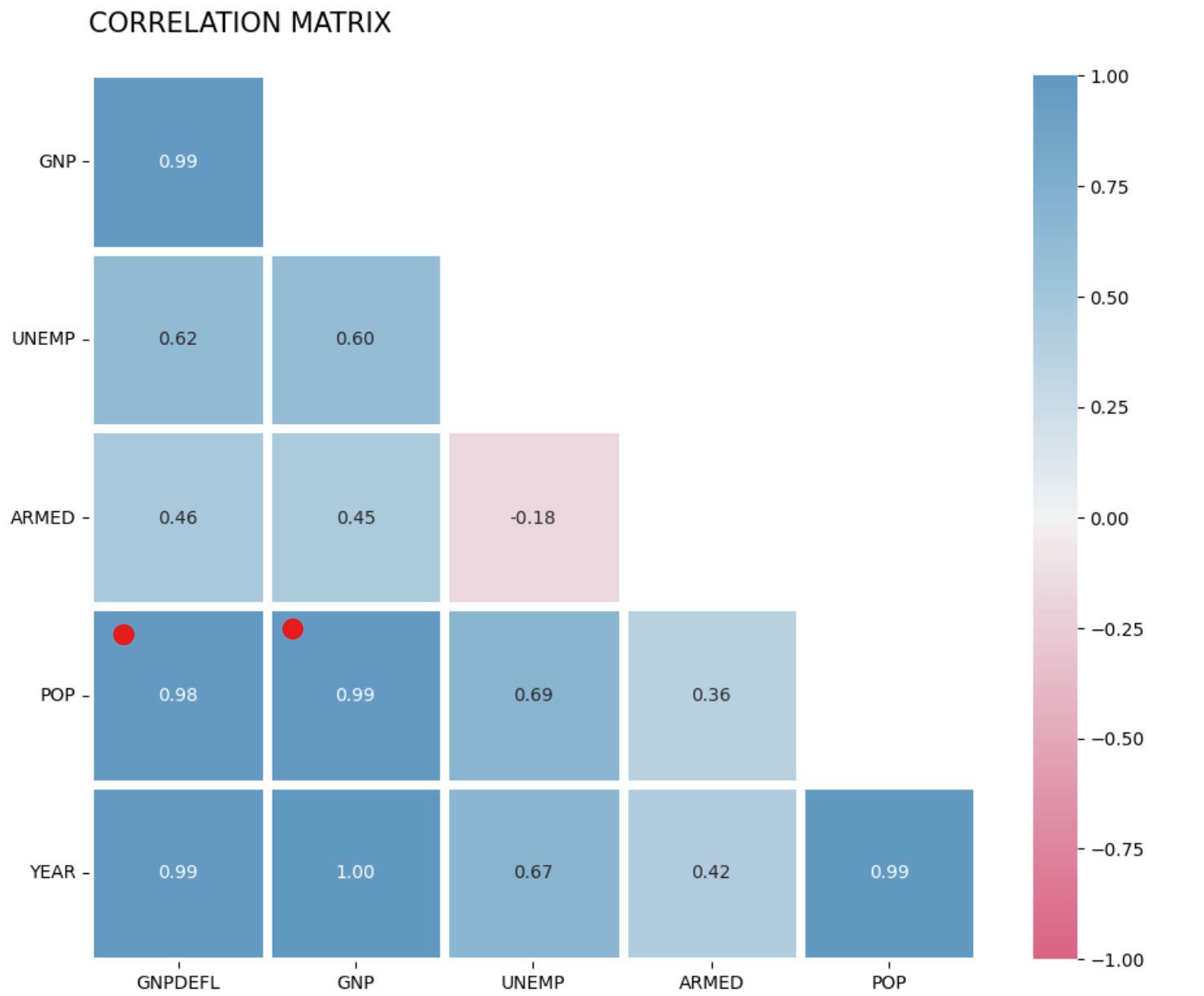
fig, ax = plt.subplots(figsize=(11,11))
df_corr=dfX.corr()
#mask
mask = np.triu(np.ones_like(df_corr,dtype=np.bool))
# adjust mask and df
mask = mask[1:,:-1]
corr = df_corr.iloc[1:,:-1].copy()
# color map
cmap = sns.diverging_palette(0,230,90,60,as_cmap=True)
# plot heatmap
sns.heatmap(corr, mask=mask, annot=True, fmt=".2f", linewidths=5, cmap=cmap, vmin=-1, vmax=1,cbar_kws={"shrink": .8}, square=True)
# ticks
yticks = [i.upper() for i in corr.index]
xticks = [i.upper() for i in corr.columns]
plt.yticks(plt.yticks()[0], labels=yticks,rotation=0)
plt.xticks(plt.xticks()[0], labels=xticks)
# title
title = 'CORRELATION MATRIX\n'
plt.title(title, loc='left', fontsize=15)
plt.show()
train_set
1
2
3
4
5
df_train, df_test = train_test_split(df, test_size=0.4, random_state=0)
model1 = sm.OLS.from_formula("TOTEMP ~ GNPDEFL + POP + GNP + YEAR + ARMED + UNEMP",data=df_train)
result1 = model1.fit()
print(result1.summary())
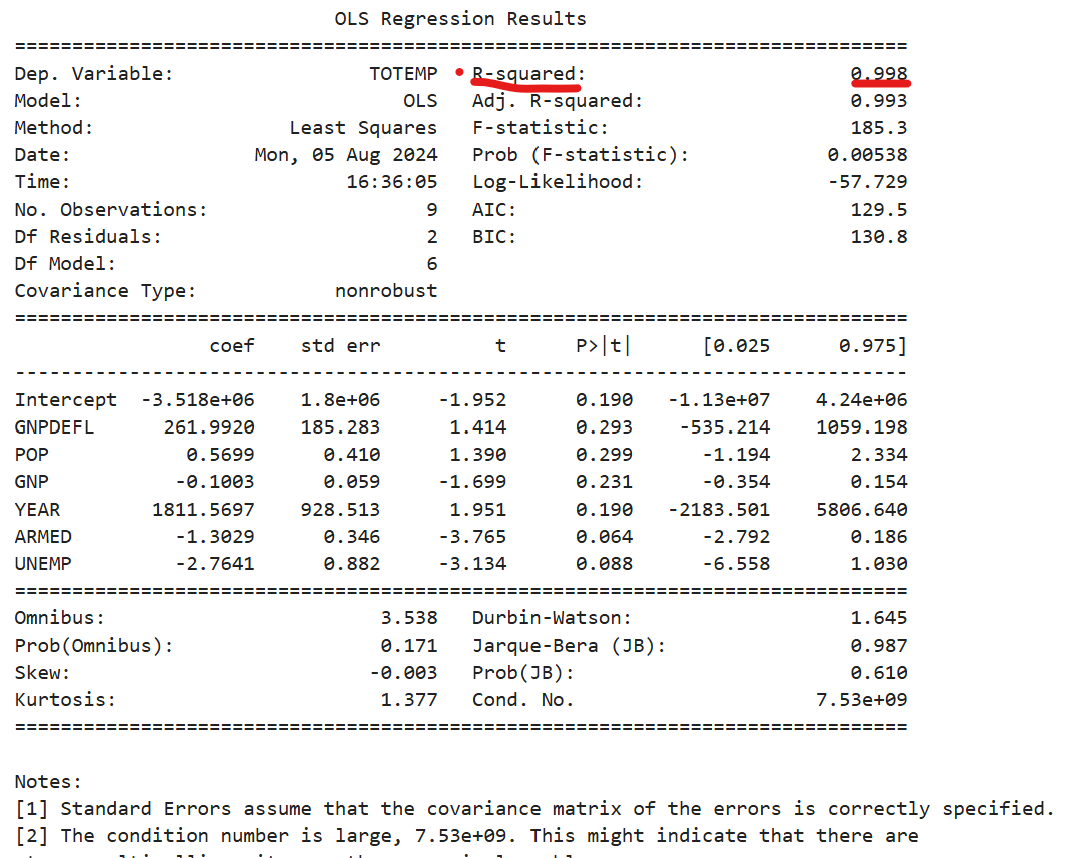 회귀 모형 구축 시, R-squared = 0.998로 나온 걸 알 수 있다.
회귀 모형 구축 시, R-squared = 0.998로 나온 걸 알 수 있다.
test_set
test set에 대한 R-squared를 구하는 함수
1
2
3
4
5
6
def calc_r2(df_test, result):
target = df.loc[df_test.index].TOTEMP
predict_test = result.predict(df_test)
RSS = ((predict_test - target)**2).sum()
TSS = ((target - target.mean())**2).sum()
return 1 - RSS / TSS
1
2
3
4
5
6
7
test1 = []
for i in range(10):
df_train, df_test = train_test_split(df, test_size=0.4, random_state=i)
model1 = sm.OLS.from_formula("TOTEMP ~ GNPDEFL + POP + GNP + YEAR + ARMED + UNEMP", data=df_train)
result1 = model1.fit()
test1.append(calc_r2(df_test, result1))
test1
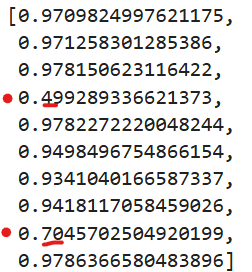
테스트의 결과로 나온 R-squared에는 “0.49”, “0.7” 낮게 나온 것이 있기에 과적합되었음을 알 수 있습니다.
다중 공선성 진단법
분산팽창계수(VIF, Variance Inflation Factor)
1
2
3
4
5
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(dfX.values, i) for i in range(dfX.shape[1])]
vif["features"] = dfX.columns
vif
#variance_inflation_factor의 설명을 넣으면 좋을 듯
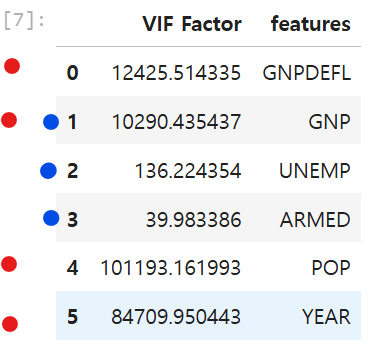
변수제거
1
2
3
4
model2 = sm.OLS.from_formula("TOTEMP ~ scale(GNP) + scale(ARMED) + scale(UNEMP)", data=df_train)
result2 = model2.fit()
print(result2.summary())
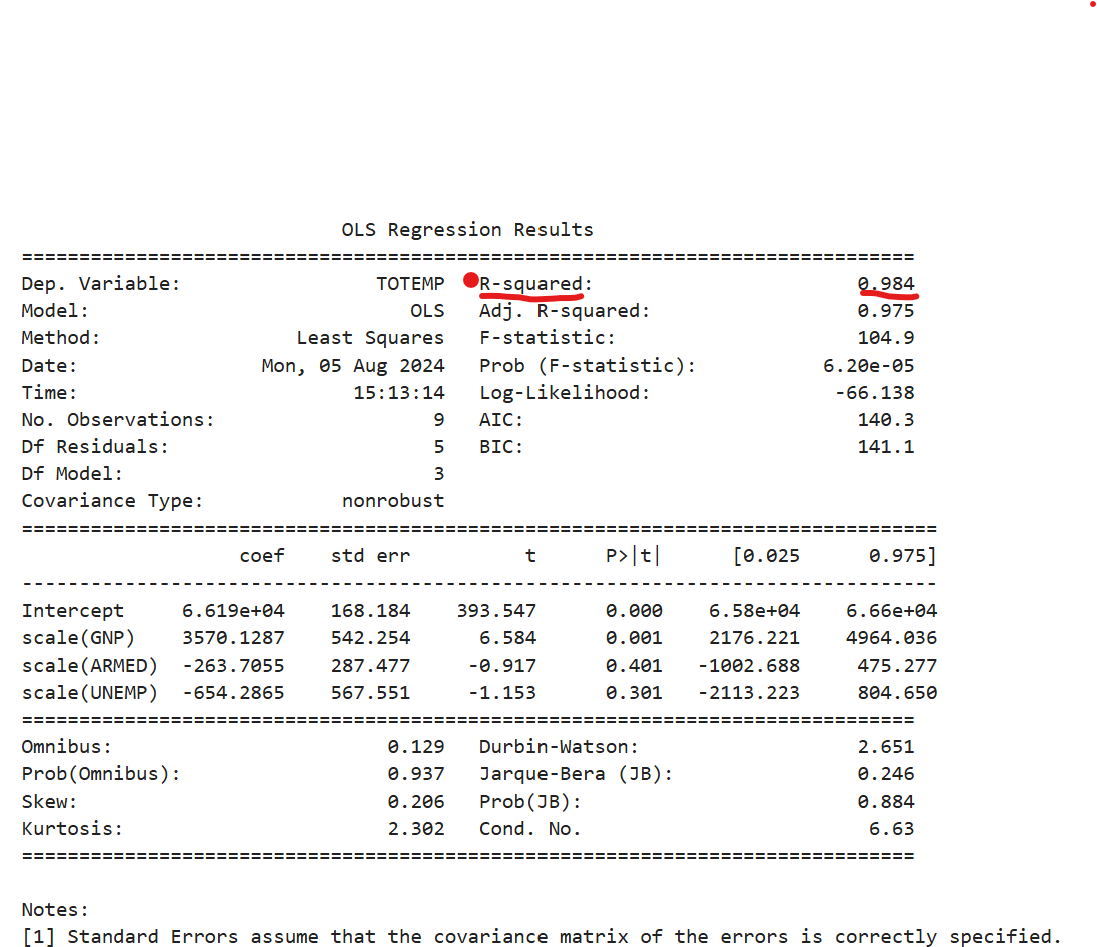
테스트 결과
1
2
3
4
5
6
7
8
test2 = []
for i in range(10):
df_train, df_test = train_test_split(df, test_size=0.4, random_state=i)
model2 = sm.OLS.from_formula("TOTEMP ~ GNPDEFL + POP + GNP + YEAR + ARMED + UNEMP", data=df_train)
result2 = model1.fit()
test2.append(calc_r2(df_test, result2))
test2
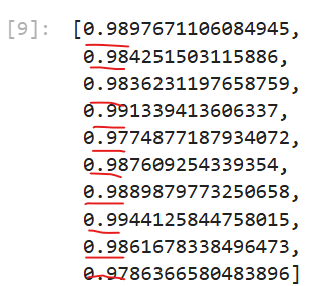
R-squared 가 0.97이상인 모습을 보여주고 있습니다.
참고 다중회귀분석