[CV] Week6. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scaled
Abstract
tranformer구조는 nlp분야에서 높은 성능을 보이며 표준으로 자리잡았지만 computer vision 분야에서는 제한적이다.
computer vision분야에서 attention은 cnn에 결합해서 쓰거나 cnn의 구성 요소를 대체하는 식으로 간접적으로만 사용된다.
cnn에 대한 의존을 끊고 transformer를 직접적으로 사용하기 위해 이미지를 patch로 잘라 sequence로 사용하는 방식으로 이미지 분류를 한다.
거대한 양의 데이터 셋으로 pre-train한 후 중간 사이즈 또는 적은 양의 이미지 데이터셋에 대해 transfer하는 방식으로 resnet기반의 sota모델보다 좋은 성능과 적은 계산량을 보인다.
Introduction
transformer는 self-attention을 사용한 구조로 자연어처리 분야에서 높은 성능을 보여 표준으로 사용되고 있다. 사전 학습 한 후 작은 task의 데이터셋에 대해서 fine-tune한다. Transformer의 적은 계산량과 높은 확장성으로 인해, 100B가 넘어가는 막대한 parameter를 가지는 모델도 학습이 가능하다.
NLP 분야에서의 성공에 힘입어, CNN 구조의 모델들에 Self-attention을 접목시키려했다. CNN 구조를 통째로 Transformer로 바꾸려했는데 이는 이론적으로는 괜찮아보이나 specialized된 attention 패턴을 보여서 계산상으로 비효율적이었다.
구글팀은 이런 상황에서 표준 그대로의 transformer를 이미지에 적용하려 했다.
이미지를 일정한 크기의 patch로 나눠서 이를 단어 배열처럼 sequence로 사용하는 것이다. 그러면 이미지 패치는 nlp분야에서 토큰처럼 처리하며 이를 통해 이미지 분류 작업에 적용한다.
그러나 ResNet과 같은 크기의 ImageNet 데이터 샛을 사용하여 학습했을 때 Transformer 기반 모델은 약간 떨어지는 성능을 보였다. 이는 CNN이 가지는 Translation equivariance와 locality 같은 본질적인 특성, 즉 inductive biases가 부족하기 때문이다.
inductive bias란 모든 모델이 지금까지 만나보지 못했던 상황에서 정확히 예측하기 위해 사용하는 추가적인 가정이다.
cnn에 내제된 inductive bias가 존재하지 않기 때문에 데이터가 적을때 성능 자체는 낮을 수 있지만 데이타기 많다면 상황이 달라진다. 큰 데이터셋에 사전학습을 시킨 다음 각각의 테스크에서 전이학습 시킬 경우 vit는 sota성능을 보인다.
Related work
Transformer는 2017년 기계 번역을 위해서 제안되었고 많은 NLP task에 있어서 SOTA의 성능을 보였다. 거대한 corpora로 학습하고 실제 task에 fine-tume하는 방식이다. 활용 예시로 BERT와 GPT가 있다.
Self-attention을 이미지에 적용하는 것을 간단하게 생각했을 때 각 픽셀이 각각의 픽셀에게 attend하는 것을 생각할 수 있다. 하지만 그렇게 된다면 pixel의 수에 따라 엄청나게 많은 cost가 소요될 수도 있어서 현실적이지 않다.
Method
ViT는 original Transformer(Attention is all you need 중)의 구조를 대부분 따릅니다.
vision transformer(ViT)
Step 1. 이미지 x∈R H×W×C 가 있을 때, 이미지를 (P×P) 크기의 패치 N(=H×W/P 2 )개로 분할하여 sequence x p ∈R N×(P 2 ×C) 를 구축함. 여기서 (H,W)는 원본 이미지의 해상도, C는 채널의 수, (P,P)는 이미지 패치의 해상도이다.
Step 2. Trainable linear projection을 통해 x p 의 각 패치를 flatten한 벡터 D차원으로 변환한 후, 이를 패치 임베딩으로 사용한다.
Step 3. Learnable class 임베딩과 패치 임베딩에 learnable position 임베딩을 더한다. 여기서 Learnable class는 BERT 모델의 [class] 토큰과 같이 classification 역할을 수행한다.
Step 4. 임베딩을 Transformer encoder에 input으로 넣어 마지막 layer에서 class embedding에 대한 output인 image representation을 도출한다. 여기서 image representation이란 L번의 encoder를 거친 후의 output 중 learnable class 임베딩과 관련된 부분을 의미한다.
Step 5. MLP에 image representation을 input으로 넣어 이미지의 class를 분류함.
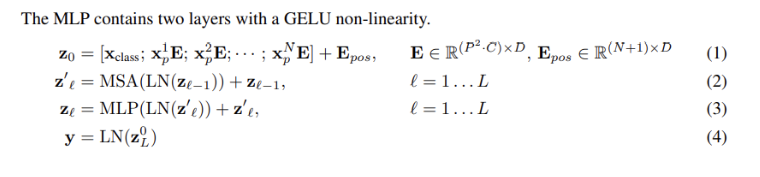
Fine-Tuning And Higher Resolution
논문의 저자는 ViT를 large dataset으로 pre-train하고 downstream task에 fine-tune하여 사용한다.
pre-trained prediction head를 제거하고 D×K zero-initialized feedforward layer로 대체한다. 대체하면 pre-training 보다 더 높은 해상도를 fine-tune하는 것에 도움이 된다.
높은 해상도의 이미지를 모델에 적용하면 patch size는 그대로 가젹고 그렇다면 큰 sequence length를 갖게 된다.
가변적 길이의 패치를 처리할 수는 있지만, pre-trained position embeddings는 의미를 잃게 됩니다. 이 경우 pre-trained position embedding을 원본 이미지의 위치에 따라 2D interpolation하면 된다.
Experiment
setup
아래와 같은 large-scael dataset에 pre-trained 한 다음
- ILSVRC-2012 ImageNet dataset (1.3M images)
- ImageNet-21k(14M images)
- JFT(303M images)
pre-trained 한 모델들을 아래와 같은 벤치마크 task에 transfer했다.
- ImageNet(오리지널 validation 라벨과 cleaned-up ReaL 라벨)
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
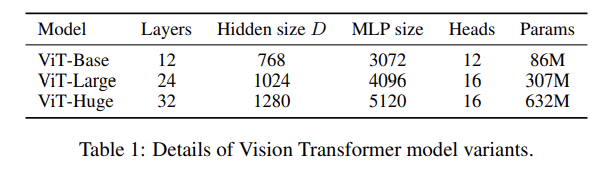
ViT는 총 3개의 volume에 대해서 실험을 진행했으며, 각 볼륨에서도 다양한 패치 크기에 대해 실험을 진행했다.
downstream dataset에 대해 아래와 같은 메트릭을 사용했다.
few-shot accuracy
- training images의 subset에 대한 (frozen) representation을 {−1,1}K 에 매핑하는, 최소제곱회귀문제
- closed form으로 구할 수 있어서, 간혹 fine-tuning accuracy의 연산량이 부담될 때만 사용했다.
fine-tuning accuracy
- 각 dataset에 fine-tuning한 다음 모델의 성능
Comparison To State Of The Art

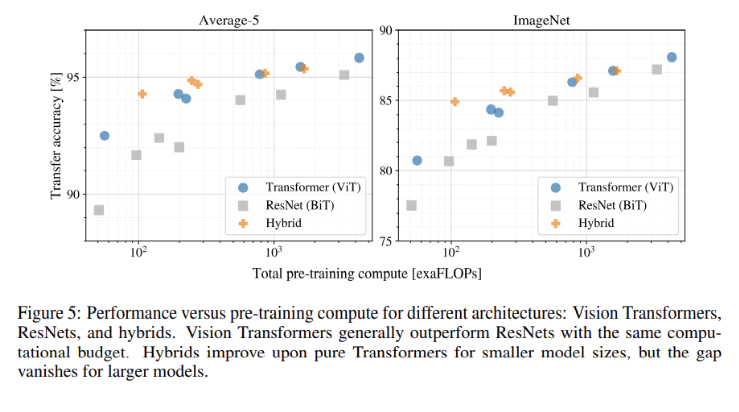
ViT-H/14 모델이 가장 높은 성능을 보였다. 기존 SOTA 모델인 BiT-L 보다도 높은 성능이며 더 적은 시간이 걸렸다. 또한 이보다 작은 모델인 ViT-L/16 또한 BiT-L보다 높은 성능을 보였으며 시간은 훨씬 적게 걸렸다.
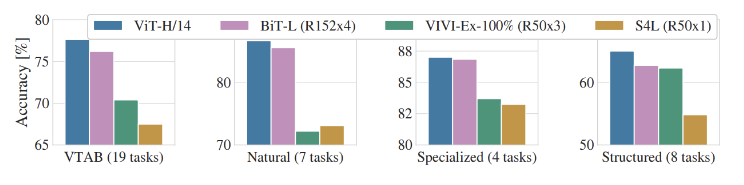
VTAB 데이터셋에서도 ViT-H/14 모델이 가장 좋은 성능을 보였습니다. 해당 실험은 데이터셋을 3개의 그룹으로 나누어 진행한 실험이다.
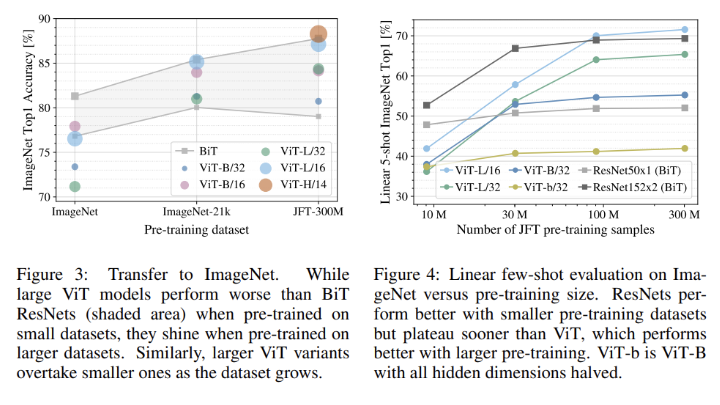
Pre-training Data Requirements
ViT가 CNN 모델들과 가장 다른 점은 바로 낮은 inductive bias를 가진다는 것이다.
데이터가 비교적 적어도 높은 indutive bias로 dataset의 표현을 잘 배우는 CNN보다 ViT는 데이터가 더 많이 필요하다.
Inspecting Vision Transformer
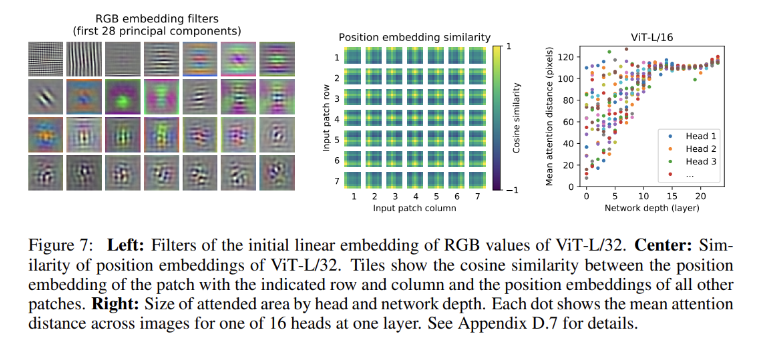
왼쪽부터 flatten된 패치를 팿 임베딩으로 변환하는 linear projection의 principal components를 분석한 모습이다. 이를 통해 저차원의 CNN filter 기능과 유사하다는 것을 알 수 있다.
가운데는 패치간 position embedding의 유사도를 통해 가까운 위치에 있는 패치들의 position embedding이 유사한지를 확인한다.
오른쪽은 이미지 공간에서 평균 거리를, attention weights를 기반으로 나타낸 모습이다. 이미지 전체 정보를 종합하여 사용한다.

attention을 사용한 만큼 task를 수행할 때 이미지의 어느 부분에 집중하는지를 파악할 수 있다.
Conclusion
image-specific inductive biases를 특별하게 사용하지 않고 이미지를 패치로 자른 sequence를 NLP에서 사용하는 Transformer encoder에 넣어서 self-attention을 사용한다.
large datasets으로 pre-train 시킴으로써 기존의 SOTA 모델들을 능가하는 성능과 더 적은 computational cost가 소요된다
Detection과 Segmentation 그리고 Self-Supervised Learning을 아직 해결해야한다.
https://velog.io/@kbm970709/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-An-Image-is-Worth-16x16-Words-Transformers-for-Image-Recognition-at-Scale
https://velog.io/@sjinu/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0AN-IMAGE-IS-WORTH-16X16-WORDS-TRANSFORMERS-FOR-IMAGE-RECOGNITION-AT-SCALE-Vi-TVision-Transformer
https://lcyking.tistory.com/entry/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-ViTVision-Transformer%EC%9D%98-%EC%9D%B4%ED%95%B4