[CV] Week4. 심화| ViT
vision transformer에 대해서 알아보았습니다.
원래 Transformer는 주로 자연어 처리(NLP)에서 텍스트를 분석하고 이해하는 데 사용되던 기술입니다. 문장 속 단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 신경망입니다. 이 방식을 이미지 분석에 적용한 것이 Vision Transformer(ViT)입니다. 이미지도 언어처럼 일정한 구조로 나눠서 분석할 수 있다는 생각에서 나온 것입니다.
Vision Transformer(ViT)는 컴퓨터가 이미지를 이해하고 처리하는 방법 중 하나입니다. ViT는 사람의 시각처럼 이미지를 조각내서 분석하고, 이 조각들을 조합해 전체 이미지를 이해하는 인공지능 모델입니다.
기존 방식(CNN)은 이미지를 전체적으로 훑는 것이라면, ViT는 이미지의 일부에 집중해서 순차적으로 분석하는 방식입니다.
이런 방식을 통해 컴퓨터는 이미지 안의 중요한 부분에 더 잘 집중하고, 더 복잡한 이미지도 잘 이해할 수 있습니다.
Vision Transformer는 처음에 아주 큰 데이터셋을 사용해 Pre-Train(사전 학습) 합니다. 이렇게 큰 데이터로 학습한 후, 작은 이미지 데이터셋에 이 학습된 모델을 Transfer Learning(전이 학습) 방식으로 적용하면, 적은 리소스로도 훨씬 좋은 성능을 낼 수 있습니다.
Transformer 도입
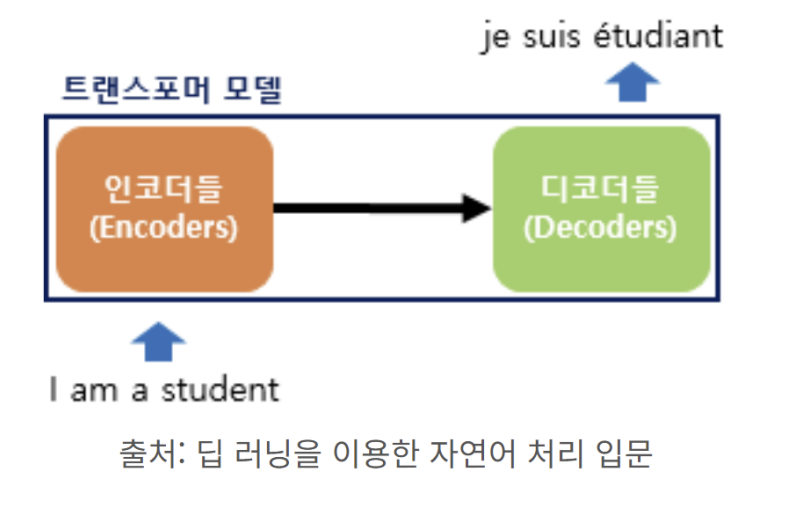
Transformer의 도입과정부터 살펴보도록 하겠습니다.
앞에서 말했듯이 Transformer는 자연어 처리(NLP)에서 유명해진 모델인데, 특히 “Attention is All You Need”라는 논문에서 나온 Self-Attention메커니즘을 사용했습니다. 입력으로 들어온 시퀀스 안에서 단어들 간의 관계를 고려하는 이 메커니즘을 기반으로 다양한 NLP 모델이 발전했습니다.
Transformer의 장점
Transformer의 큰 장점은 계산 효율성과 확장성입니다. 매우 큰 모델(1000억 개의 파라미터)도 학습이 가능합니다. 특히, 데이터셋이 크면 클수록 성능이 계속 향상됩니다. 일반적으로 모델은 어느 정도 커지면 성능이 한계에 도달하는데, Transformer는 데이터를 더 주고 모델을 더 크게 만들수록 성능이 계속 좋아지는 경향이 있습니다.
Transformer를 이미지에 적용하는 방법
이제 트렌스포머에 이미지를 적용하는 방법을 살펴보면
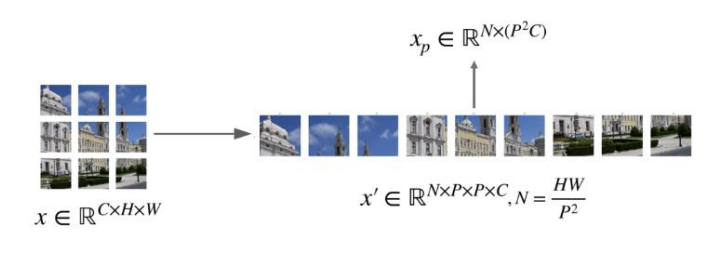
이미지를 작은 조각들(Patch)로 나눈 다음 이 조각들을 순서대로 입력합니다. 이 과정은 NLP에서 단어를 입력하는 방식과 매우 유사합니다. NLP에서 텍스트는 단어의 나열(Sequence)로 구성되는데, 이미지를 조각내면 이미지도 비슷한 방식으로 분석할 수 있다는 것이죠.
16x16 픽셀 크기의 이미지 조각 하나가 NLP에서 단어 하나처럼 작동한다고 생각할 수 있습니다. 이렇게 나눈 조각들을 Supervised Learning방식으로 Transformer로 학습시킵니다. 정답을 알려주고 그에 맞게 학습하는 방식으로 학습합니다.
Transformer의 특징
ImageNet과 같은 중간 크기의 데이터셋으로 학습하면 ResNet보다 성능이 낮을 수 있습니다. 하지만, JFT-300M과 같은 아주 큰 데이터셋으로 사전 학습(Pre-Train)을 하고, 그 후 전이학습하면, 기존 CNN 구조보다 훨씬 좋은 성능을 보여줍니다.
Self-Attention을 적용하려는 초기 시도 (Naive Application)
Self-Attention을 적용하려는 초기 시도를 살펴보도록 하겠습니다.
첫번째 파마르의 시도입니다. 이미지의 특정 픽셀 근처에만 집중해서 분석한 것입니다. 이는 전체 이미지에 적용하는 것보다 덜 복잡하지만, 전역적으로 적용하지는 않았기 때문에 제한이 있었습니다.
두번째 바이센보른은 이미지를 다양한 크기의 블록으로 나누고, 각 블록에 Scale Attention을 적용했습니다. 이 방식은 이미지의 크기에 따라 다르게 처리할 수 있지만, 효율적인 GPU 사용을 위해서는 복잡한 엔지니어링이 필요했습니다. 실제로 사용하기에는 기술적으로 구현하기가 쉽지 않았습니다.
세번째 코르도니어는 이미지를 2x2 크기의 패치로 나눠서 Self-Attention을 사용했습니다. 다만, 이미지 패치의 크기가 작았기 때문에 해상도가 작은 이미지에서만 잘 작동했습니다. 해상도가 높은 이미지에서는 적용하기 어려웠습니다.
마지막 이미지 지피티는 생성 모델처럼 이미지를 학습했습니다.
첫 번째로, 해상도와 컬러 공간을 줄여서 데이터를 간단하게 만들었습니다.
두 번째로, Transformer를 이미지의 픽셀에 직접 적용했습니다. 즉, 이미지를 픽셀 단위로 보고, 이를 NLP에서 단어를 처리하듯 분석했습니다.
Vision Transformer(ViT)의 핵심 목적
Vision Transformer의 첫 번째 목적은 대규모 데이터셋을 사용해 학습할 수 있는지 확인하는 것입니다. 이미지 데이터로도 Transformer 모델을 잘 훈련할 수 있는지 확인하려는 것입니다.
두 번째 목적은, 자연어 처리에서 쓰이는 Transformer 구조를 그대로 이미지 분석에 적용할 수 는지 확인하는 것이었습니다. 특별한 구조를 바꾸지 않고 텍스트 처리에 쓰이던 Transformer가 이미지 분석에 효과적인지 확인하려는 시도입니다.
마지막으로, ViT는 아주 고해상도 이미지만이 아니라, 일반적인 해상도의 이미지에서도 성능을 낼 수 있는지 확인하고자 했습니다. 일반적으로 해상도가 너무 낮으면 세밀한 정보가 부족하고, 너무 높으면 계산량이 많아지기 때문에, 중간 크기의 이미지에서 잘 작동하는 것이 중요합니다.
ViT (Vision Transformer) Method
ViT는 NLP에서 사용되는 Transformer 구조를 거의 변형 없이 이미지 분석에 적용할 수 있습니다. 이를 통해 복잡한 이미지 구조를 효율적으로 학습할 수 있게 됩니다.
ViT Architecture (ViT 구조)
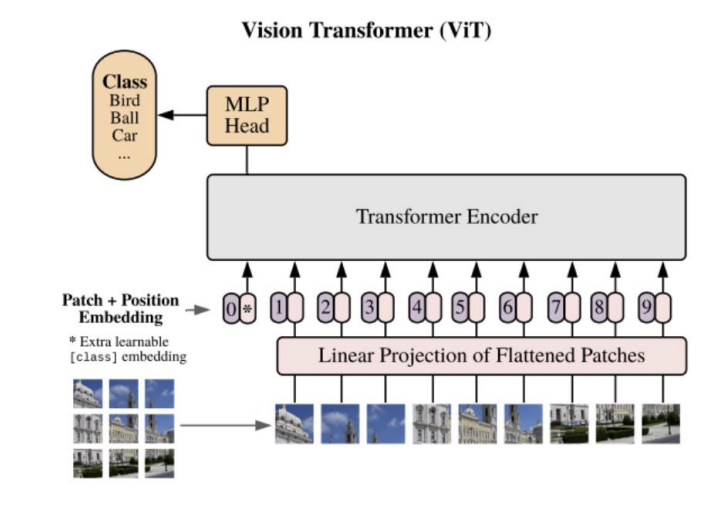
ViT구조를 살펴보도록 하겠습니다. 이미지를 작은 조각(패치, Patch)으로 나눈 후, 이 조각들을 1차원 시퀀스로 변환하여 Transformer에 입력합니다. 각 패치를 Flatten한 후, Linear Projection을 사용해 고정된 차원 D로 변환해서 Patch Embedding을 만듭니다.
이미지를 패치로 나누어 시퀀스로 처리할 때, 위치 정보(패치가 어디서 온 것인지)를 잃지 않기 위해 Position Embedding을 추가합니다.
분류 작업을 수행하기 위해 학습 가능한 “CLS 토큰”을 시퀀스에 추가합니다. 이 토큰은 Transformer 인코더를 통과하면서 전체 이미지에 대한 정보를 취합하게 됩니다.
![]()
앞 과정을 거쳐 만들어진 입력을 Encoder에 입력하여, Layer stack의 개수만큼 반복한다. Transformer Encoder의 출력 또한 클래스 토큰과 벡터로 이루어져있다. 이 중 클래스 토큰만 사용하여 위 구조의 MLP Head를 구성하고, 이를 이용하여 MLP를 거치면 최종적으로 클래스를 분류할 수 있다.
Hybrid Architecture (하이브리드 아키텍처)
ViT는 CNN을 대체할 수 도 있고, CNN의 Feature Map을 이용하여 ViT의 입력으로 사용해 CNN과 Vit를 결합할 수도 있습니다. CNN으로 이미지를 처리한 후, 그 Feature Map을 Flatten한 다음, ViT에서 사용하는 Embedding Projection으로 변환하여 학습할 수 있습니다.
Fine-Tuning & Higher Resolution (미세 조정과 높은 해상도)
Fine-Tuning 시, 사전 학습할 때보다 더 높은 해상도로 이미지를 처리하면 성능이 향상될 수 있습니다. 해상도가 높아지면 시퀀스 길이도 길어지지만, 이때 사전 학습한 Position Embedding이 더 이상 유효하지 않습니다. 그래서 2D 보간(Interpolation)을 통해 새로운 해상도에 맞게 Position Embedding을 조정합니다.