[CV] Week4. Sequence model and attention mechanism & Transformer Network
Sequence Models (Course 5 of the Deep Learning Specialization)
Basic Models
어떻게 새로운 network를 학습해서 시퀀스 x를 입력으로 하고 시퀀스 y를 출력할 수 있을까?
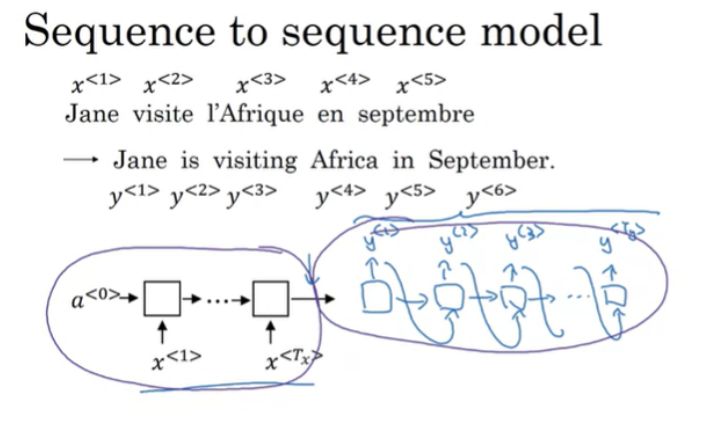
인코더 네트워크와 디코더 네트워크로 구성된다.
이와 비슷한 구조로 이미지 캡션도 수행할 수 있다.
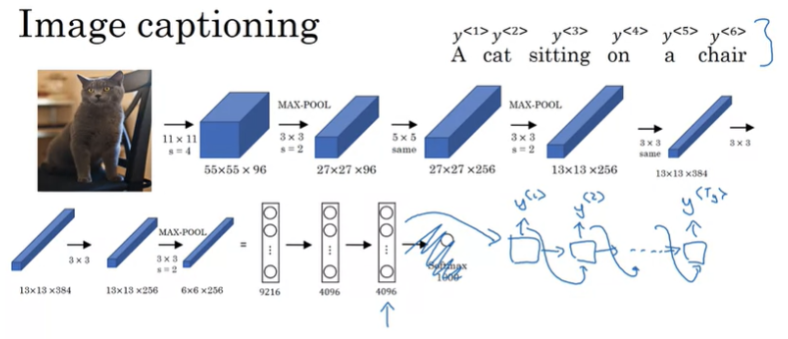
pre-trained된 Alexnet을 사용해서 마지막 softmax layer를 alex net으로 4096 차원의 특성 벡터를 출력하게 된다. 이 부분이 이미지의 인코더 네트워크라고 할 수 있다. 그리고 RNN 모델을 디코더 네트워크로 사용해서 4096 차원의 특성 벡터를 입력으로 사용해서 이미지를 설명하는 단어들이 출력으로 나오게 된다.
Picking the most likely sentence
Maching translation 은 조건부 언어모델로 생각할 수 있다. 디코더 네트워크가 language 모델고 윳한 것을 볼 수 있다.
![]()
language 모델은 0벡터에서 시작했지만 기계번역 모델에서는 인코더 네트워크를 통과한 출력이 language 모델로 입력되는 것이다.
모델은 입력 프랑스어 문장에 대해 영어 문장들의 조건부 화가률을 출력한다. 모델의 확률 분포를 얻어 샘플링했을 때 괜찮은 번역을 얻을 수도 있고 좋지 않은 번역을 얻을 수도 있다.
좋은 번역을 위해 조건부 확률을 최대로 하는 영어 문장을 찾아야 한다. 여기서 자주 사용되는 알고리즘 beam search이다.
greedy 알고리즘도 있는데 이는 별로 좋지 않다. 첫번째 단어를 예측할 때 가장 높은 확률의 단어 하나만 선택하고 가장 높은 확률 두번째 단어를 선택한다. 그 후 가장 높은 확률의 세번째 단어를 선택한다.
전체 시퀀스의 확률을 최대화하는 것으로 가장 높은 단어만을 선택하는 것은 효과가 없다.
voca size를 고려하면 모든 단어들을 평가하는 것은 불가능하다. heuristics 탐색 알고리즘을 사용해 최대치를 찾는다.
Beam Search
가장 확률이 높은 output을 찾기 위해 사용되는 알고리즘이다. greedy 알고리즘은 가장 확률이 높은 한의 단어만 선택하지만 이는 다양한 경우를 고려한다.
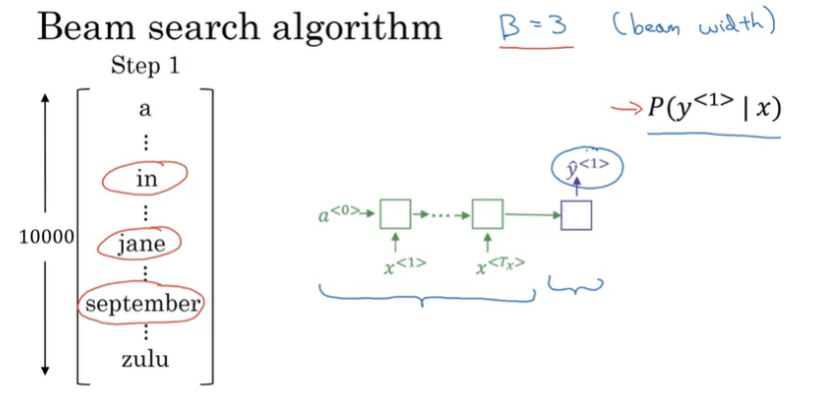
Beam search는 B라는 매개변수를 가지고 있다. 이는 Beam width라고 불린다. 여기에서 B=3으로 설정했는데, 이는 beam search가 3개의 가장 높은 가능성을 고려한다는 것을 의미한다.
Refinements to Beam Search
beam search는 조건부 확률이 최대가 되는 경우 찾는 경우를 찾는 것이다.
P는 확률로 모든 값이 1보다 작고 P를 계속 곱하면 그 값은 1보다 훨씬 작아진다. 단어가 많을 수록 그 수는 계속 작아지며 컴퓨턱 그 값을 정확하게 표현하기에는 너무 작아질 수도 있다.
너무 작아지면 짧은 번역을 선호하게 된다.
이 문제를 해결하기 위해 log를 취한다.
log함수도 마찬가지로 증가하는 함수로 최대가 되는 값을 찾는다.
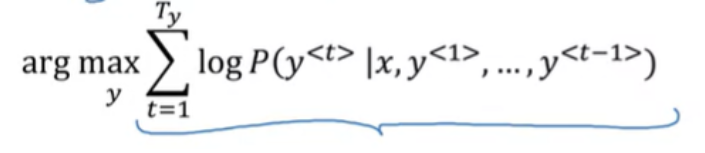
| og함수를 최대화하는 것은 P(y | x)를 최대화하는 것과 동일하며 log를 취해주게 되면 수치적으로 더 안정적으로 된다. |
이 경우에도 확률은 항상 1보다 작거나 같기에 더 많은 단어가 있을수록 음수가 점점 커지게 된다.
더 잘 작동하게 하려면 단어의 수 Ty로 normalization하면 된다
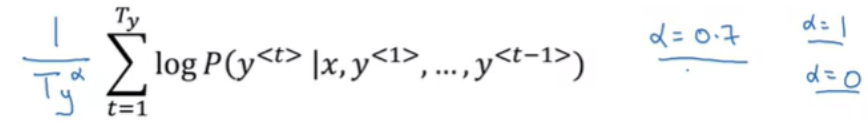
Ty가 너무 큰 경우 α승을 사용할 수도 있다.
B의 크기는 어떻게 선택할까? B의 크기가 아주 크다면 많은 가능성들을 고려하게 되고 더 좋은 결과를 얻는 경향이 있다. 하지만 더 느려지고 메모리도 많이 차지하게 된다.
반면 B의 크기가 너무 작다면 고려하는 경우가 적기 때문에 좋지 않은 결과를 얻게 된다. 하지만 속도는 더 빠르고 메모리 또한 덜 차지한다. 최고의 결과를 위해 1000에서 3000개를 사용하기도 한다.
BFS나 DFS와 같은 탐색 알고리즘과 다르게 Beam탐색은 훨씬 더 빠른 알고리즘이다. 하지만 정확한 최대값을 내지는 않는다.
Error analysis in beam search
beam search는 휴리스틱 탐색 알고리즘으로 항상 최고의 확률 문장을 출력하지는 않는다.
프랑스어 문장을 예시로, 아래에 인간이 번역한 것( y ⋆ )과 알고리즘 모델이 번역한 결과물( y
)이 있다.
가장 좋은 방법은 P(y ⋆ ∣x)와 P ( y
∣ x ) 를 계산하는 것이다. 그리고 둘 중의 어느 값이 더 큰 지 확인한다.
![]()
둘을 비교하는 것으로 모델의 오류를 명확하게 설명할 수 있다.
| P(y⋆ ∣x) > P( y^ ∣x) | P(y ⋆ ∣x) <= P(y^ ∣x) | |
|---|---|---|
| Beam Search가 더 높은 확률의 번역을 선택하지 못한 것이므로 Beam Search 알고리즘에 문제가 있다고 판단할 수 있다. | RNN 모델이 잘못된 번역을 더 높은 확률로 예측했으므로, RNN 모델에 문제가 있다고 판단할 수 있다. |
Bleu (Blingual Evaluation Understudy) Score
기계번역에서는 이미지 인식과는 달리 여러가지의 좋은 정답이 있다.
평가하기 위해서는 정확성을 측정하면 된다. 이때 Bleu Score이 사용된다
모델이 예측한 결과가 사람이 제공한 reference와 가깝다면 Bleu Score는 높게 된다.

Bleu Score는 직관적으로 기계가 생성하는 글의 유형을 최소한 인간이 만들어낸 reference에서 나타나는지 살펴보는 방법이다. 극단적인 기계번역(MT)의 결과를 가지고 어떻게 점수가 계산되는지 살펴보자.
MT output이 얼마나 괜찮은지 측정하는 한가지 방법은 출력된 각 단어를 보고 reference 안에 그 단어가 존재하는지 살펴보는 것이다. 이를 MT output의 Precision(정밀도)라고 부른다.
MT output : ‘the the the the the the the’
이 단어는 Ref1이나 Ref2에 모두 나타난다.
따라서 이 단어들은 꽤 괜찮은 단어처럼 보일 수 있고, 정밀도는 7/7이 된다. 결과만 봐선 아주 좋은 결과같아 보인다.
이 MT output이 정확하다는 것을 의미하지만 위에서 보듯 유용한 방법이 아니다.
대신, Modified Precision을 사용할 수 있다. 각 단어에 대해서 중복을 제거하고, reference 문장에 나타난 최대 횟수만큼 점수를 부여한다. Ref1에서는 ‘the’가 2번 나타나고, Ref2에서는 ‘the’가 1번 나타난다. 따라서, Modified precision은 2/7가 된다.
위에서 단어의 순서는 고려하지 않는다.

bigrams에서 Bleu score는 MT output의 각 단어들을 서로 근접한 두 개의 단어들로 묶어서, Reference에 얼마나 나타나는지 체크해서 Modificed Precision을 계산한다.
즉, MT output 에서 각 단어 쌍들의 Count와, MT output의 단어쌍들이 Reference에 얼마나 등장하는지 Count해서 계산하게 된다.
unigrams와 bigrams에서 bleu score를 구하는 방법을 살펴보았고, n-grams로 확장하면 다음과 같이 계산할 수 있다.

Attention Model
대부분 encoder-decoder architecture 를 사용하고 하나의 RNN에서 입력문장을 읽고 다른 RNN에서 문장을 출력한다. 짧은 문장에서는 잘 동작하지만 길이가 길어지면 성능이 낮아져 Bleu score 가 낮아진다.
attention model 을 사용해 긴 문장에서도 성능을 유지할 수 있게 된다. 사람이 문장을 통으로 한번에 번역하지 않고 중간중간 번역하는 것처럼 attnetion model도 사람과 유사하게 번역한다. 전체 입력 문장을 참고하는 것이 아닌 예측할 단어와 연관되는 부분만 집중해서 참조한다.
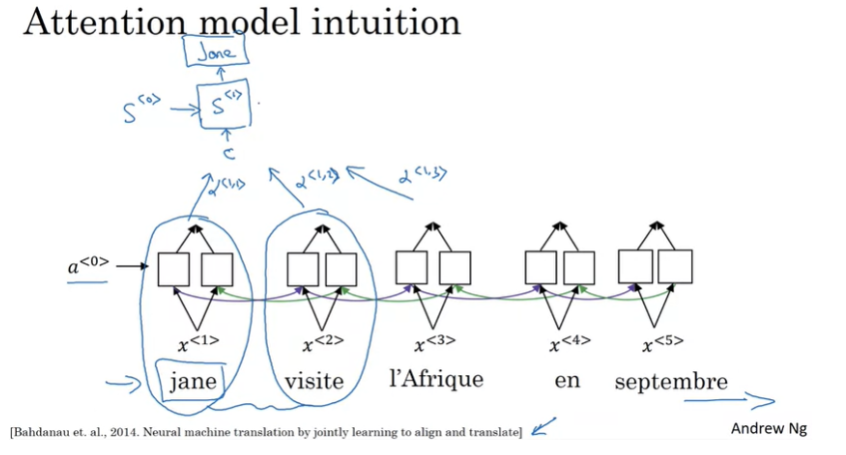
endoder에 해당하는 BRNN이 있다. 그리고 decoder에 해당하는 RNN model을 사용한다. 여기에 사용되는 activation을 s로 표기한다. BRNN을 통해서 계싼된 activation을 사용해 c를 구낳다. 이때 일부 activation만 참조한다. 다음 c를 decoder 입력으로 사용해 단어를 예측한다.
입력의 일부에 집중하도록 한다.
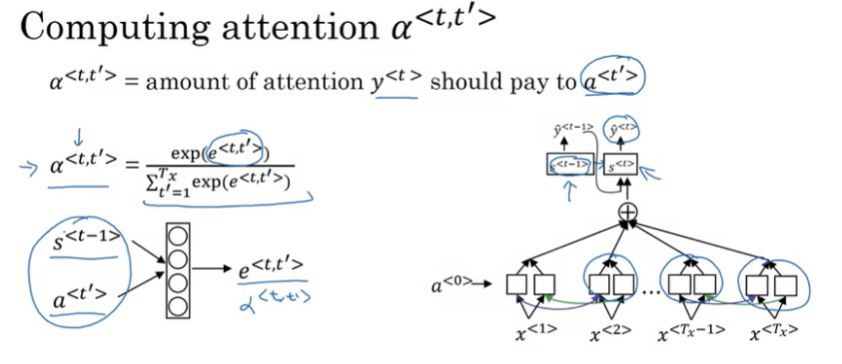
attention parameter을 softmax확률로 계산되며 총합은 1이 된다.
attention model은 image caption에도 적용된다.
Speech recognition
음성 인식은 오디오 클립 x를 통해서 transcript를 찾는다. 이 문제를 해결하기 위해 입력 데이터를 주파수별로 분리한다. 옫오 클립 아래 그래프 x축은 시간이다. y축은 주파수인 그래프를 나타낸다.
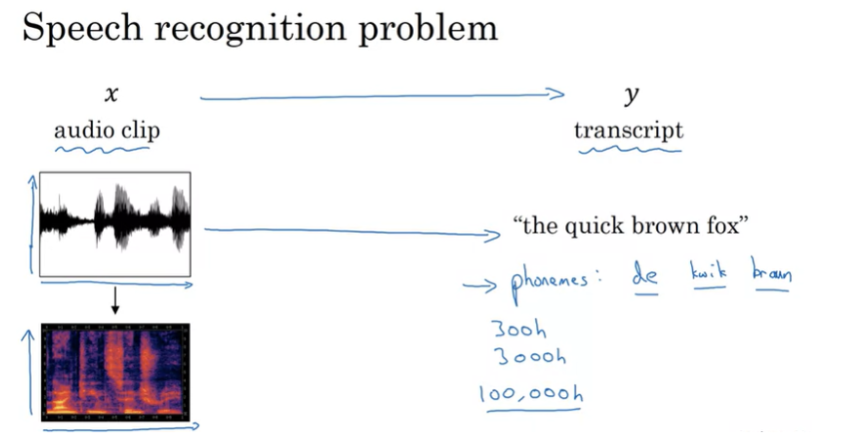
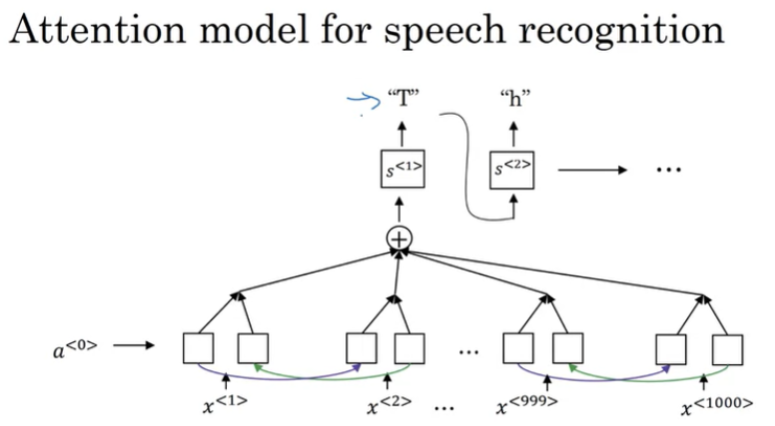
attention mode을 음성 인식 모델에 사용할 수 있다.
아니면 CTC(connectionist temporal classification) Cost를 사용할수도 있다.
Trigger Word Detection
기계를 깨울 수 있는 방법! 여전히 발전하고 있다.

RNN모델에서 오디오 클립 x가 입력으로 사용된다. label y를 정의한다. trigger word를 누군가가 말할때 trigger word를 말하기 전의 시점은 모두 label을 0으로 설정한다. 말하고 난 직후 시점을 1로 label한다. label의 불균형으로 1에 비해 0이 훨씬 많아 잘 동작하지 않는다.