[CV] Week3. recureent neural network & Natural Language Processing and Word Embedding
Sequence Models (Course 5 of the Deep Learning Specialization)
Why sequence model
시퀀트 모델 사용 예시
- 음성인식: 입력과 출력 모두 시퀀스 데이터인데 x는 시간에 따라 재생되는 음성이며 y는 단어 시퀀스이다.
- 음악 생성: 아웃풋만 시퀀스 데이터이고 입력은 빈 집합이거나 단일 정수, 또는 생성하려는 음악의 장르나 원하는 음악의 처음 몇 개 음일 수 있다.
- 감정분류: 인풋이 시퀀스, 주어진 문장에 대해 아웃풋은 별점이 될 수 있다
- DNA 분석: 염기서열 보고 어떤 부분이 일치하는지 라벨 붙이기
- 기계번역, 비디오 동작 인식, 이름 인식
Notation
이름 인식할 때 각 단어마다 아웃풋을 가지며 아웃풋은 이름인지 아닌지에 대한 1또는 0의 값을 가진다.
x<1>
순서를 나타내기 위해 위첨자로 나타낸다. 인풋과 아웃풋을 이런 식으로 나타낸다.
Tx=9
시퀀스 길이
x(i)<t>
여러개의 training data 에서 i번째 training data
Tx(i)
i번째 트레이닝 데이터 길이

표현된 인풋을 아웃풋으로 매핑하는 시퀀스 모델을 학습한다.
보카에 없는 단어가 나온다면 새로운 토큰ㅇ나 모르는 단어를 의미하는 가짜 단어를 만든다. <UNK>와 같이 표시해서 포카에 없는 단어를 만든다.
Recurrent Neural Network Model
9개 입력반는 모델에서 9개의 one-hot 벡터가 모델에 입력된다. hidden layer를 통해서 초종적으로 0또는 1의 값을 갖는 9개의 output이 나온다.
one-hot encoding
1. 각 단어에 고유한 인덱스를 부여한다.
2. 표현하고 싶은 단어 인덱스 위치에 1을 넣고 ㄷ른 단어 인덱스 위치에는 0을 넣는다.
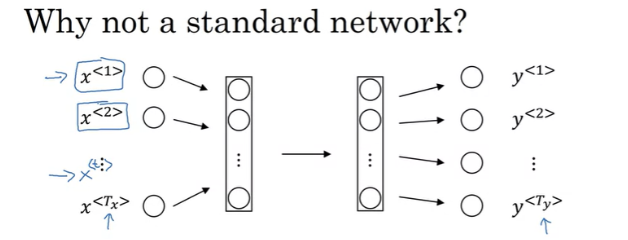
문제점
- 입력과 출력 데이터의 길이가 트레이닝 데이터마다 다르다. -> 입력에 임의의값이나 0으로 채워서 최대 길이로 동일하게 맞출 수는 있지만 좋지 않다.
- naive 신경망에서는 텍스트의 서로 다른 위치에 있는 동일한 feature단어가 공유되지 않는다. 이름이 첫번째 위치나 t번째 위치에서 나오거나 동일하게 사람 이름이라고 추론하는 것이 올바르다.
RNN?
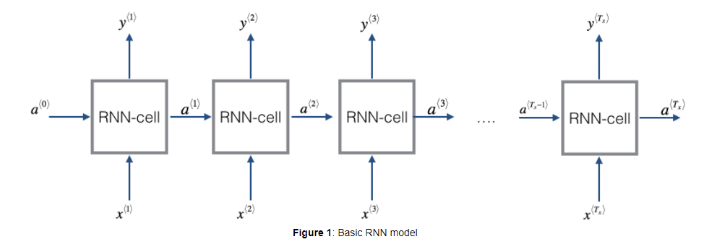
x<1> 를 신경망의 입력으로 사용한다. 내부 신경망(hidden layer, output layer)으로 사람 이름의 일부인지 예측한다.
y<2> 를 예측할 때,
x <2> 만 사용하는 것이 아니라, 첫번째 단어 정보의 일부를 사용하게 된다.
마지막으로 x<Tx> 로 y<Ty> 를 예측한다.
RNN단점: 앞서 나온 정보만을 사용해서 예측한다. 뒤에 정보는 사용하지 않는다.
이는 양방향으로 반복되는 BRNN을 통해서 해결할 수 있다.
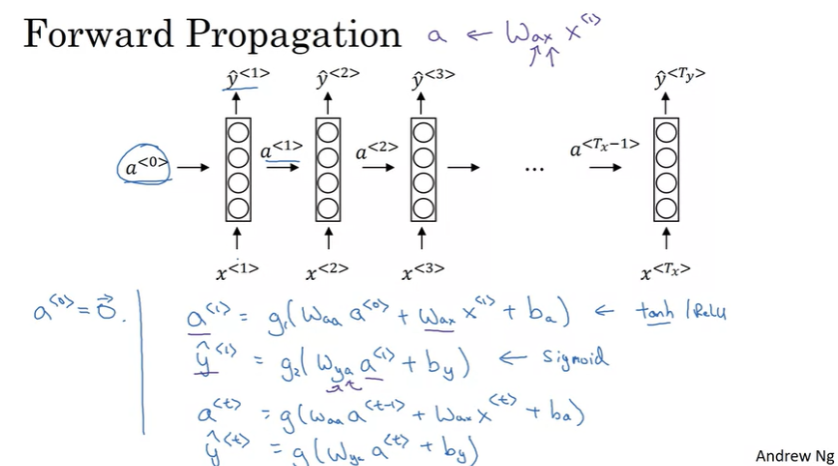
a<0>은 일반적으로 0벡터로 초기화 다음을 구하기 위해서 activation function을 적용한다. activation function으로는 tanh나 ReLU가 사용된다.
Backpropogation through time
BP를 계산하기 위해 Loss function을 통해서 실제 결과와 예측값의 loss를 계싼하고 총 loss값을 구한다.
BP는 오른쪽에서 왼쪽으로 향ㅎ는 계산이다. 시간이 거꾸로 가는 것고 같아서 Backpropagation through time 라고 부른다.
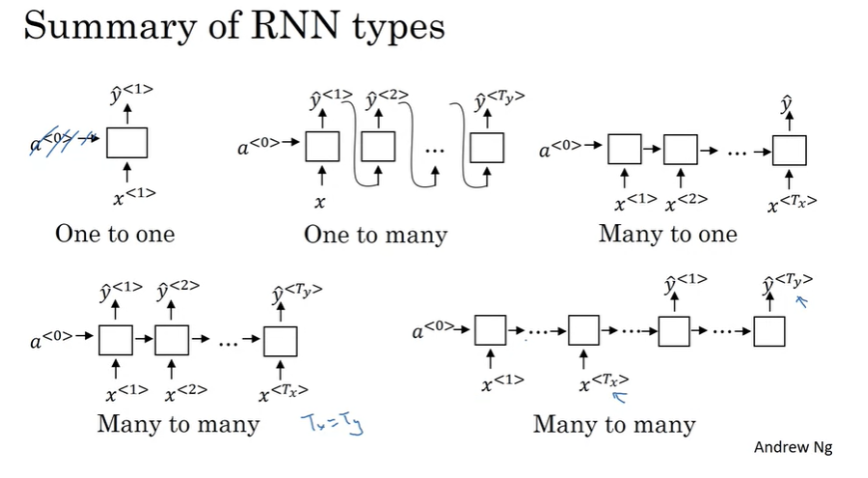
Difference types of RNNs
제일 처음에 x, y가 모두 시퀀스 데이터거나, x가 빈 집합일 수도 있거나, 하나의 입력일 수 있으며, y가 시퀀스가 아닐 수도 있다고 했다.
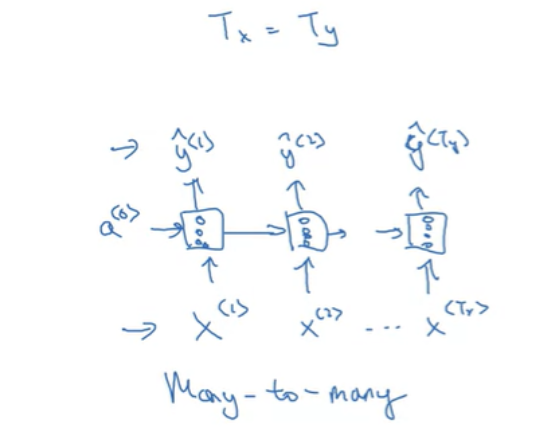
- many-to-many 아키텍처: 인풋 시퀀스와 아웃풋 시퀀스의 길이가 같다
- Many-to-one 아키텍처: 감정 분류처럼 x는 텍스트지만 y가 0또는 1의 값을 갖는다.
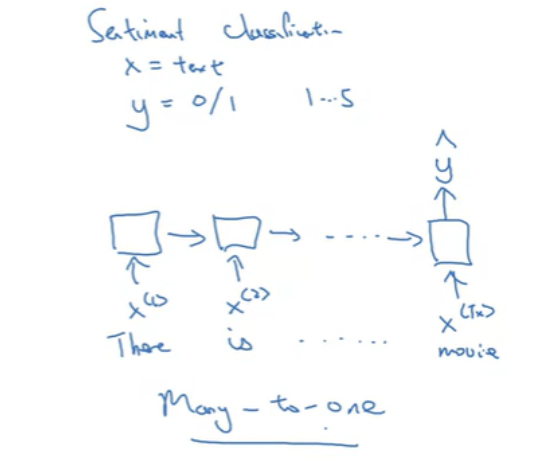
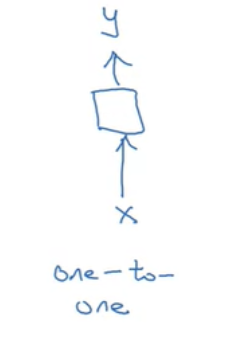
- one-to-one: 단순 신경망과 동일하다
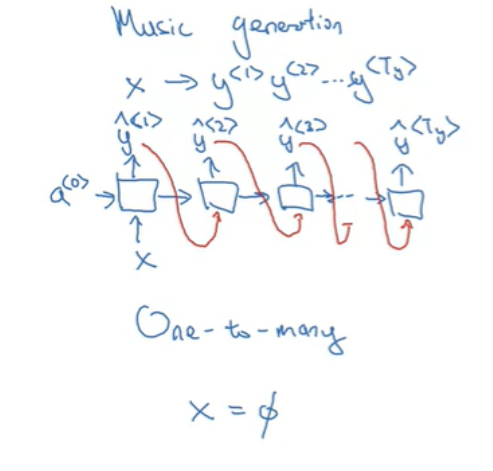
- one-to-many: 음악 생성 모델은 입력이 정수일 수도 있고 장르, 음표, 아무것도 입력하지 않을 수도 있다. 하나의 input과 sequence 아웃풋을 가질수도 있다.
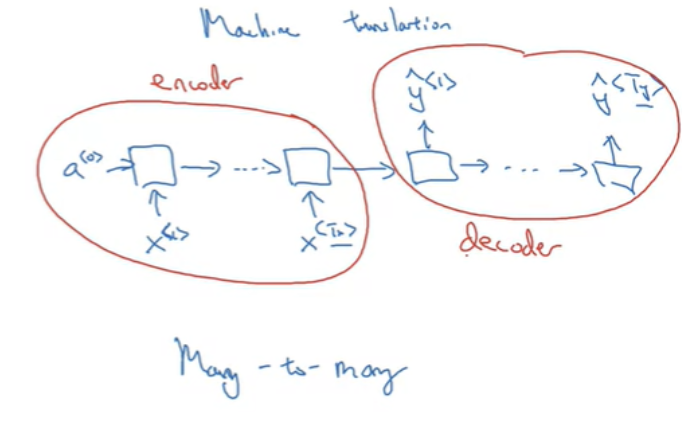
- Many-to-many: 입력과 출력의 길이가 다를 수 있다. 입력 부분을 encoder 출력 부분을 decoder라고 한다.
Language model and sequence generation
language modelling?

두 번째 문장이 더 가능성 있다. 확률이 얼마인지 알려주는 언어 모델을 사용해서 선택한다.

- 문장 토큰화
- 토큰화를 통해 단어들로 분리
- 단어들을 voca의 index를 통해 one-hot vector로 매핑
- +문장이 끝난다는 의미인 <EOS>라는 토큰을 추가한다.
- 없는 단어라면 <UNK>토큰으로 대체할 수 있다.
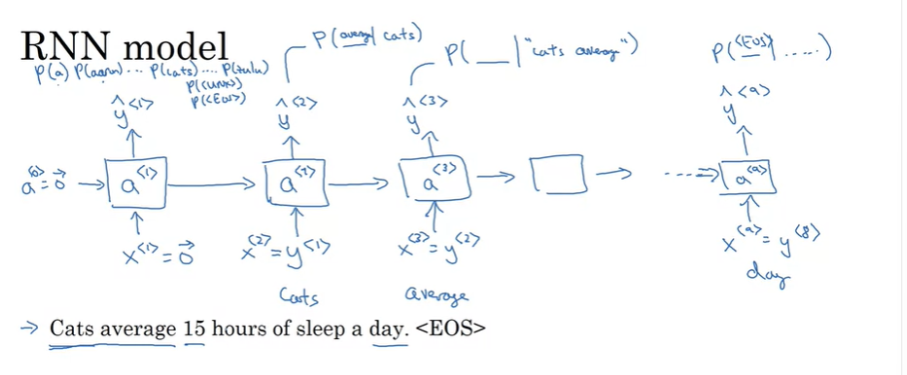
x<1> 와 a<0> 은 0 vector로 설정하고, a<1> 과 y^<1> 를 계산한다.
여기서 y^<1> 는 softmax output이며, 첫 번째 단어가 존재할 확률을 의미한다. 첫 번째 단어 cats가 될 것이다.
RNN step이 진행되고 a<1> 를 가지고 다음 단계를 진행한다. 여기서 x<2> 는 y<1> 가 되며, 이제 모델에 올바른 첫 단어인 cats를 입력하게 된다.
그리고 이 단계에서 softmax output에 의해서 다시 예측되고 그 결과는 첫 번째 단어가 cats일 때의 다른 Voca 단어들의 확률이 될 것이다.
Sampling a sequence from a trained RNN
학습한 내용을 비공식적으로 파악하는 방법!
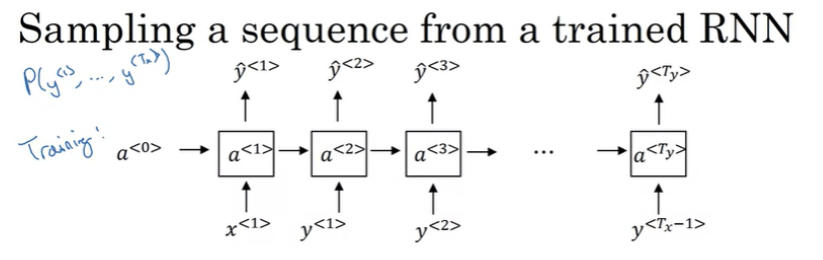
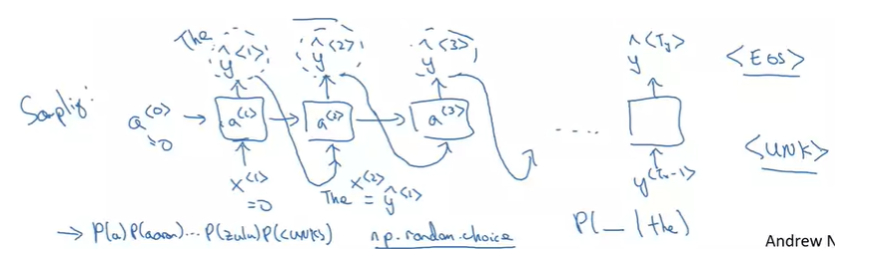
RNN모델에서 무작위로 선택된 문장을 생성하는 방법!
softmax output y<1>을 출력한다. 각 단어의 확률이 얼마나 되는지 알려준다. 샘플링한 값을 x<2>로 사용한다. 반복해서 EOS Token이 될 때까지나 정해진 샘플링 횟수를 정해서 도달할 때까지 계속한다.
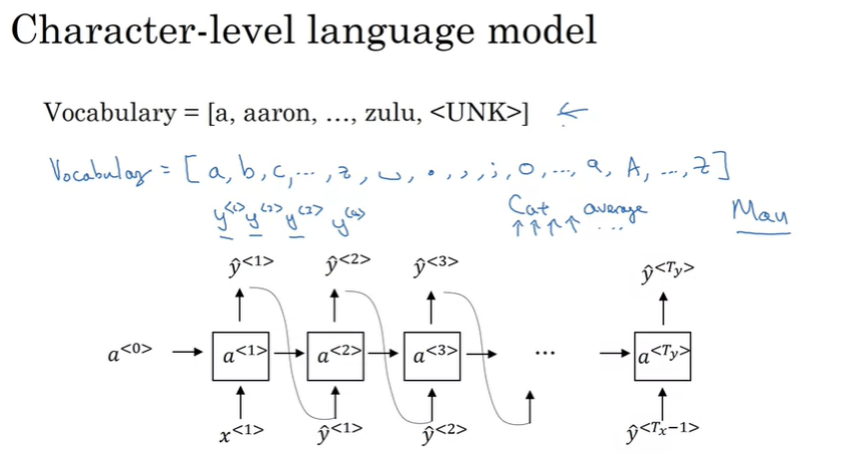
단어 대신 문자수준 모델 만들기 training set은 개별 묹로 토큰화된다. (a,b,c)
Vanishing gradients with RNNs
vanishing gradient 문제가 발생할 수 있다. 문장의 단어가 긴 시간동안 의존성을 갖고 있다. 문장의 초반부의 단어가 문장 후반부까지 영향을 미치는 것이다. RNN은 여기에 맞지 않다.
gradient가 기하급수적으로 감소해서는 안되고, 또한 기하급수적으로 증가해서도 안된다.
vanishing gradient보다 exploding gradient 가 더 큰 문제가 되고 있다. gradient가 너무 커지만 네트워크 변숙 엉망이 된다. gradient clipping 으로 해결할 수 있다.
Gated Recurrnet Unit
Vanishing Gradient 문제 해결책
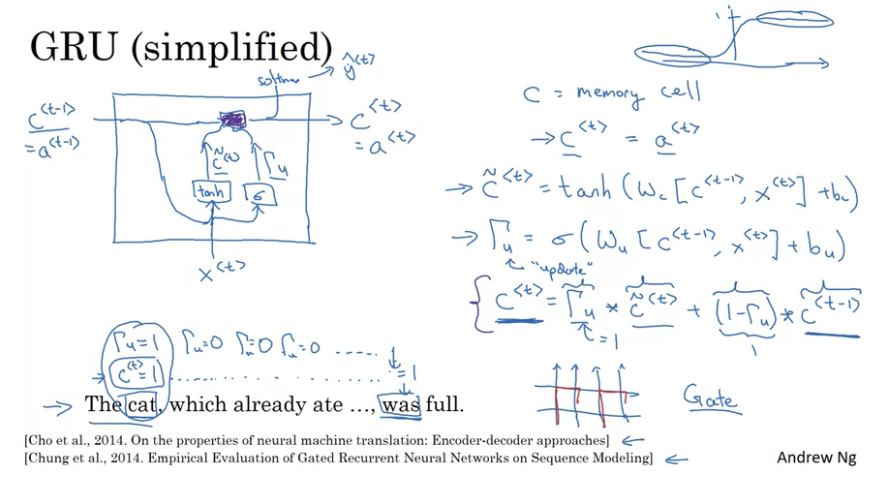
c는 memory cell을 의미하며 이전 정보들이 저장되는 공간이다.
문장 앞쪽의 단수/복수 정보가 뒤쪽까지 전달되어서 ‘was’를 예측하는데 영향을 끼친다.
현재 time step에서 다음 time step으로 전달할 정보들의 후보군을 업데이트 한다.
현재 time step에서 업데이트할 후보군과 이전 기억 정보들의 가중치합으로 계산된다. gate는 어떤 정보를 더 포함시킬지 결정한다.
Long Short Term Memery (LSTM)
GRU보다 많이 사용되는 장시간 단기 메모리 유닛이다.
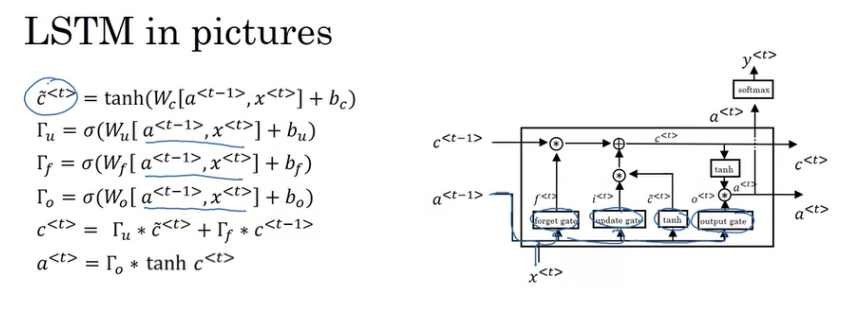
forget gate, update gate, output gate를 통해서 각각의 연산을 수행하고 tanh를 통해서 연산한다. 이는 현재 time step에서 다음 time step으로 업데이트할 정보들의 후보군을 의미한다.
GRU는 비교적 복잡한 LSTM 모델을 단순화한 것이다. GRU은 LSTM에 비해서 훨씬 단순하다. 훨씬 더 큰 네트워크를 만드는 것이 쉽다.
Bidirectional RNN(BRNN)
BRNN은 주어진 시쿼스에서 이전 시점과 이후 시점 둘 다 참조할 수 있다.
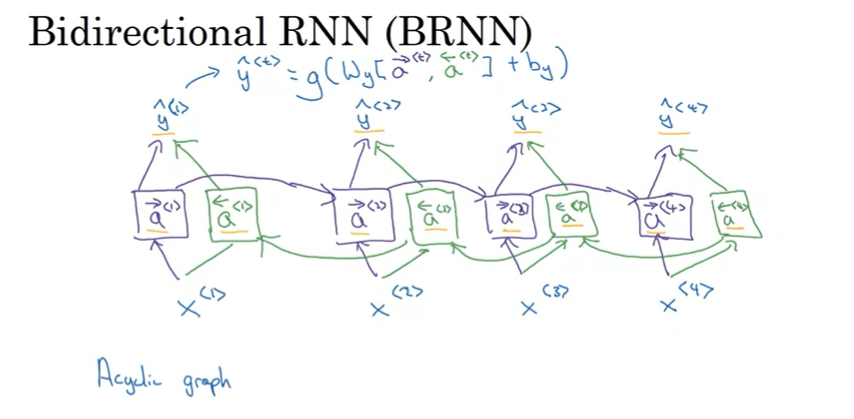
볼색을 통해 앞에서부터 정보를 읽는다. 초록색은 반대방향으로 입력 정보를 읽는다. 이 두 셀의 결과를 통해 예측값을 계산한다. 과거와 미래 정보 둘다 사용해서 예측하게 된다.
장점: 모든 정보를 참조할 수있다.
단점: 예측을 하기 전에 전체 데이터 시퀀스가 필요하다
실시간 연설 데이터 처리가 되지 않는다.
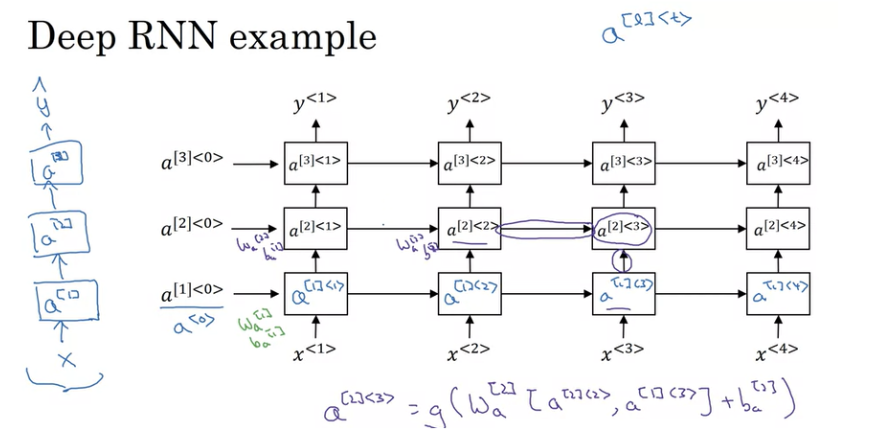
Deep RNNs
Word Representation
1만개의 단어에 대해서 one-hot encoding을 통해서 단어를 표시했다.
Man은 5391의 index를 갖고 있으며, 10000 dimension의 벡터에서 5391번째 요소만 1이고 나머지는 다 0으로 표시되는 벡터로 나타낸것이다. o 5391 로 o는 one-hot vector를 의미한다.
약점: 각 단어를 하나의 object로 여기기 때문에 단어 간의 관계를 추론할 수 없다.
I want a glass of orange ___ 를 통해서 빈칸에 juice가 들어가도록 학습했다고 하더라고, I want a glass of apple ___ 이라는 입력이 들어왔을 때, apple을 orange와 비교해서 비슷하다고 여겨서 juice를 추론할 수가 없다.
서로 다른 one hot vector 사이 곱셈 결과가 0으로 유사 단어 king과 queen, man과 woman 관계를 학습할 수 없다.
해결하기 위해 word embedding을 사용한다. 각 단어들에 대해 features 와 values를 학습해야 한다.

Man이라는 단어를 보면 Gender에 해당하는 값이 -1에 가깝고, Woman은 1에 가깝다. 서로 반대되는 개념이기 때문에 두 합이 0에 가깝다. Apple이나 Orange의 경우에는 성별과 거의 연관이 없기 때문에 Gender에 해당되는 값이 0에 가깝다.
단점: 각 row가 어떤 특징을 의미하는지 해석하기 어렵다.
장점: one-hot encoding 보다 단어간의 유사점과 차이점을 더 쉽게 알아낼 수 있다.
워드 임베딩 행렬을 쉽게 이해하기 위해 시각화 작업에 사용하는 알고리즘은 t-SNE 알고리즘이다. 더 낮은 차원으로 매핑하여 단어들을 시각화하며 유사한 단어들이 가까이 있는 것을 확인할 수 있다.
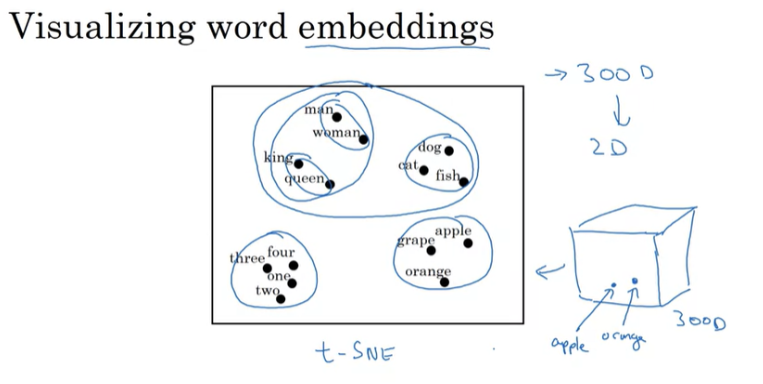
Using Word Embeddings
단어 임베딩이 이렇게 일반화할 수 있는 이유 중의 하나는 단어 임베딩을 학습하는 알고리즘이 매우 큰 단어 뭉치들을 통해서 학습하기 때문이다.
우리가 적은 수의 training set을 가지고 있어도 Transfer Learning을 통해서 미리 학습된 단어 임베딩을 가지고 학습할 수 있다.
워드 임베딩은 Transfer Learning처럼, A의 data는 많고 B의 data는 적을 때 더욱 효과적이다.
Properties of word embeddings
‘남자(man)와 여자(woman)는 왕(king)과 ____과 같다’라는 유추 문제가 있을 때, 어떻게 예측할 수 있을까?


man과 woman의 차이와 king과 queen의 차이 벡터는 매우 유사할 것이다. 위에서 나타난 벡터는 성별의 차이를 나타내는 벡터이다.
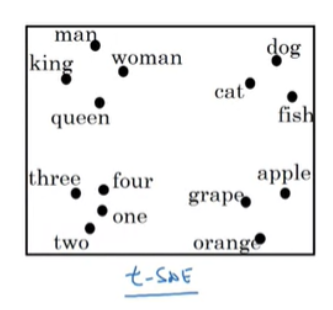
t-SNE알고리즘은 300D을 2D로 매핑한다. 임베딩을 통해서 단어간의 관계를 추론할 때, t-SNE를 통해 매핑된 임베딩 값으로 비교하면 안되고, 300D의 vector를 통해서 비교 연산을 수행해야한다.
similarity function으로는 cosine similarity나 유클리디안 거리를 가장 많이 사용한다.
Embedding matrix
단어 임베딩을 통해 학습되는 것이다. 만약 1만개의 단어를 사용하고 특징으로 300 차원을 사용한다면 위와 같은 (300, 10k)의 차원의 matrix E를 가지게 된다.
매트릭스 E는 초기에 무작위로 초기화된다.
Learning word embeddings
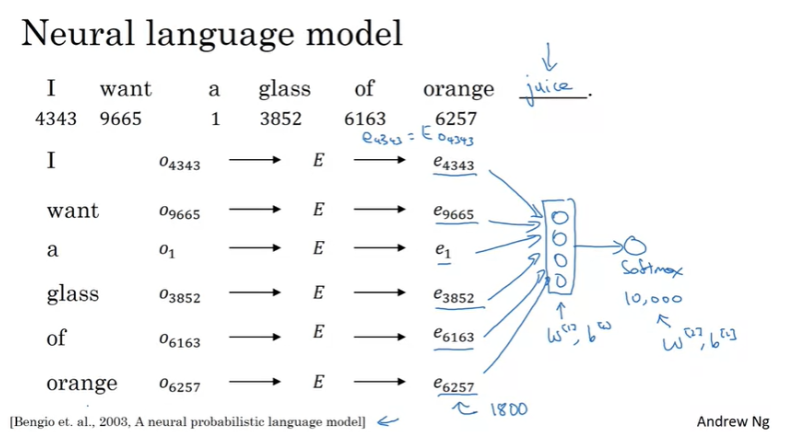
일반적으로 fixed historical window를 사용한다. 긴 문장이나 짧은 문장이나 항상 바로 앞의 4개의 단어만 살펴보는 것이다. 이것은 입력으로 1200차원의 vector를 사용해서 softmax output으로 예측하는 것을 의미한다. Matrix E를 학습한다
왼쪽과 오른쪽 4개의 단어를 선택할 수도 있고, 다른 Context를 선택할 수도 있다. 마지막 한 단어만 선택할 수도 있고, 가장 가까운 단어 하나를 사용할 수도 있다.
Word2Vec
단어를 벡터로 바꿔주는 알고리즘이다.

skip gram은 중심 단어를 무작위로 선택하고 주변 단어를 예측한다.
단어들의 one-hot vector와 Embedding Matrix E로 Embedding vector를 구할 수 있다. 이렇게 구한 Embedding vector를 입력으로 softmax layer를 통과해서 output y햇을 구할 수 있다.
단점: 계산 속도가 느리다.
-> hierarchical softmax 사용하기
tree 를 사용한다. 자주 사용되는 단어일수록 top에 위칳고 그렇지 않으면 bottom에 위치한다. 단어를 찾을 때 트리를 찾아 내려가 선형 크기가 아닌 voca 사이즈의 log 사이즈로 탐색하게 되어 소프트맥스보다 빠르다.
Negative Sampling
skip gram 보다 조금 더 효율적이다.
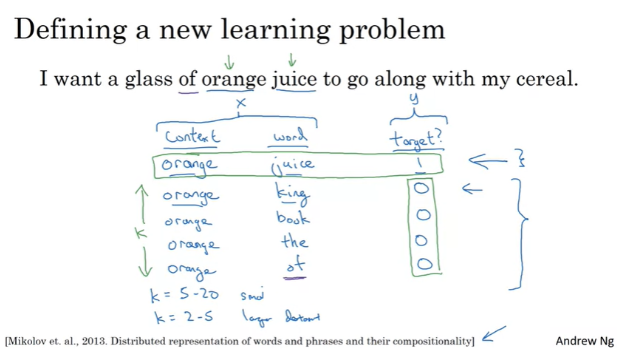
문제로 orange-juice와 같은 positive training set이 있다면 무작위로 negative training set을 K개를 샘플링한다. 이때, 무작위로 negative 단어를 선택할 때에는 voca에 존재하는 단어 중에서 무작위로 선택한다.
우연히 ‘of’라는 단어를 선택할 수도 있는데, 이는 context에 존재하는 단어이므로 실제로는 positive이지만, 일단 negative라고 취급한다.
이렇게 training set을 만든다. 작은 데이터 셋의 경우에는 K를 5~20의 값으로 추천하고, 큰 데이터 셋을 가지고 있다면 K를 더 작은 값인 2~5의 값으로 하는게 좋다
context와 target이 input x가 되고, positive와 negative는 output y가 된다. logistic regression model로 정의할 수 있게 된다.
1만 차원의 softmax가 아닌 1만 차원의 이진분류 문제가 되어서 계산량이 훨씬 줄어들게 된다.
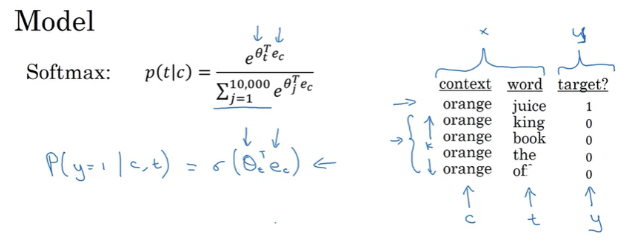
얼마나 자주 다른 단어들이 나타나는 지에 따라서 샘플링할 수 있다. 또 다른 방법으로는 1/voca size를 사용해서 무작위로 샘플링하는 것이다. 이 방법은 영어 단어의 분포를 생각하지 않는다.
GloVe word vectors
단순한 모델이다.

말뭉치에서 context와 target 단어들에 대해 i에서 j가 몇번 나타나는지 구하는 작업을 한다. 서로 가까운 단어를 캡처하며 범위를 어떻게 지정하냐에 따라 X ij ==X ji 가 될 수도 있고, 아닐 수도 있다.
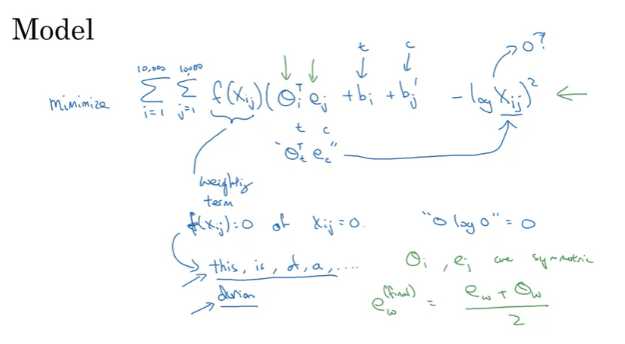
f(xij)는 weighting term이다. 이는 한번도 등장하지 않는 경우에 0으로 설정하여 더하지 않게 해준다. 지나치게 빈도가 높거나 낮은 단어로 특정값 이상으로 되는 것을 방지한다.
Sentiment classification

입력이 있을 때, 각 단어들을 임베딩 vector(300D)로 변환하고 각 단어의 벡터의 값들의 평균을 구해서 softmax output으로 결과를 예측하는 모델을 만들 수 있다.
임베딩을 사용했기 때문에, 작은 dataset이나 자주 사용되지 않는 단어가 입력으로 들어오더라도 해당 모델에 적용할 수 있다.
단어의 순서를 무시하고 단순 나열된 형태로 입력하기 때문에 좋은 모델은 아니다.
예를 들어 ‘Completely lacking in good taste, good service, and good ambience’라는 리뷰가 있다면, good이라는 단어가 많이 나왔기 때문에 positive로 예측할 수도 있다.
-> RNN 사용
시퀀스의 순서를 고려하기 때문에 해당 리뷰가 부정적이라는 것을 알 수 있게 된다.
Debiasing word embeddings
단어 임베딩에서 성별이나 나이, 인종 등의 편견을 반영하기 때문에 이것을 없애는 것은 매우 중요하다.

- 편향 방향을 구한다.
e he −e she ,e male −e female 등의 성별을 나타낼 수 있는 단어들의 차이를 구해서 구할 수 있는데, 남성성의 단어와 여성성의 단어의 차이를 구해서 평균으로 그 방향을 결정할 수 있다.

- neutralize 작업을 수행한다.
편향 요소를 제거해야 한다. 각 단어의 편향 방향 요소를 제거한다. doctor나 babysitter등의 단어의 성별 bias를 제거한다.

- equalize pairs 작업을 수행한다.
boy-girl / grandfather-grandmother과 같은 단어는 각 단어가 성별 요소가 있기 때문에, 이러한 단어들이 bias direction을 기준으로 같은 거리에 있도록 한다.