[CV] Week1. Basics of Convolutional Nerual Networks & Deep Convolutional Models: A Case Study
Convolutional Neural Networks (Course 4 of the Deep Learning Specialization)
Computer Vision
이미지 분류, 물체 감지, 신경망 스타일 변형
컴퓨터 비전 문제
인풋의 크기가 클 수 있다.->합성곱
Edge Learning Specializetion
이미지 세로선과 가로선 감지
필터=커널
*=합성곱을 의미
필터의 값과 곱하고 그 값들을 다 더한다.
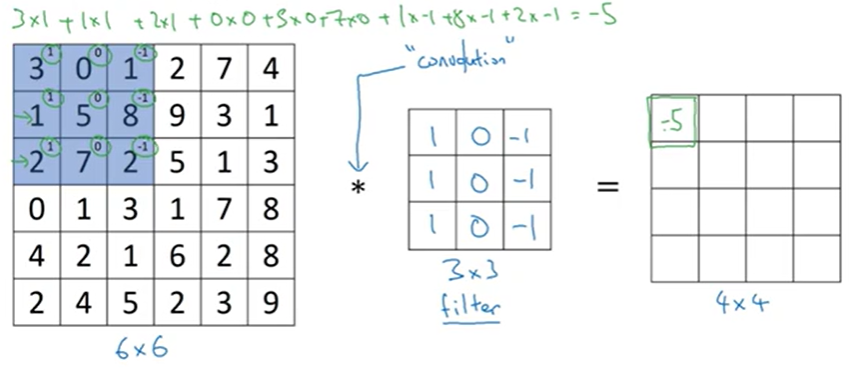
옆으로 계속 이동하며 해준다
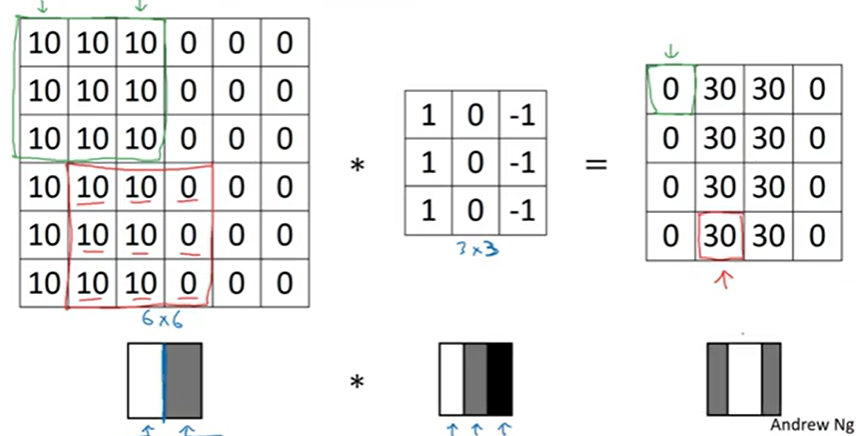
수직 경계선을 찾게 해준다. 경계선에 의해 결과에서 가운데가 밝게 나오게 되는 것이다
More Edge Detection
왼쪽이 상대적으로 밝고 오른쪽이 어둡다.
가로선 검출도 마찬가지이다. 위가 밝고 아래가 어둡다.
음의 윤곽선, 양의 윤곽선으로 해서 음수와 양수가 나오게 되는 것이다
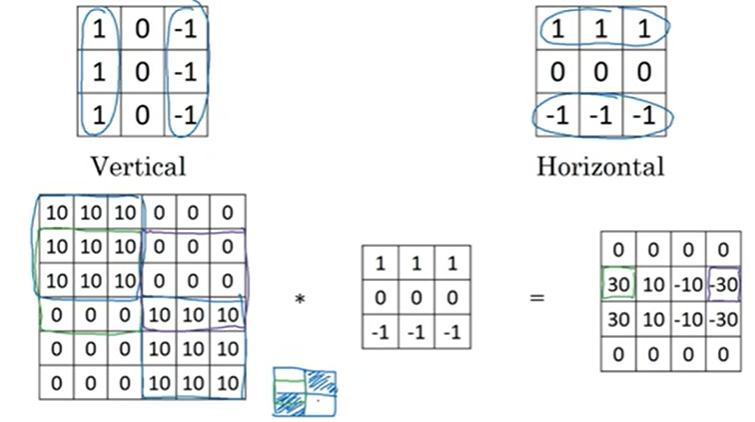
sobel filter
중간 부분의 픽셀에 더 중점을 둔다 더 선명해 보일 것이다.
Padding
합성곱 단점:
- 이미지가 축소된다. 계속 반복하면 이미지가 계속 작아질 것이다
- 가장자리 픽셀은 이미지에서 한번만 사용되게 된다. 가운데는 이와 다르게 많이 사용된다.
해결: 합성곱 전에 이미지 경계를 더해준다.
이렇게 하면 이미지의 기존 크기도 유지할 수 있게 될 것이다.
f는 홀수! 짝수면 패딩이 분균형이 된다.

Strided Convolutions
필터를 한 칸 옮기는 것이 아니라 두 칸을 옮기는 것이다
스트라이드 할때 넘어가지 않도록 패딩으로 맞추고 해준다.

| 수학적 합성곱 | 딥러닝 합성곱 |
|---|---|
| 가로와 세로축으로 미러링한다 | 미러링 과정을 생략한다 |
Convolutions Over Volumes
RGB: 6x6x3
3x3필터가 아닌 3x3x3 필터를 사용해주게 된다
순서대로 height, width, channels이다
마지막 숫자가 일치한다.
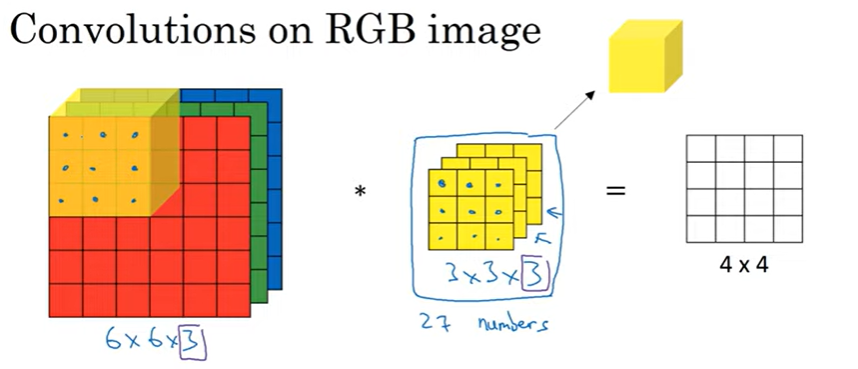
이렇게 첫번째 칸의 값을 알 수 있게 된다.
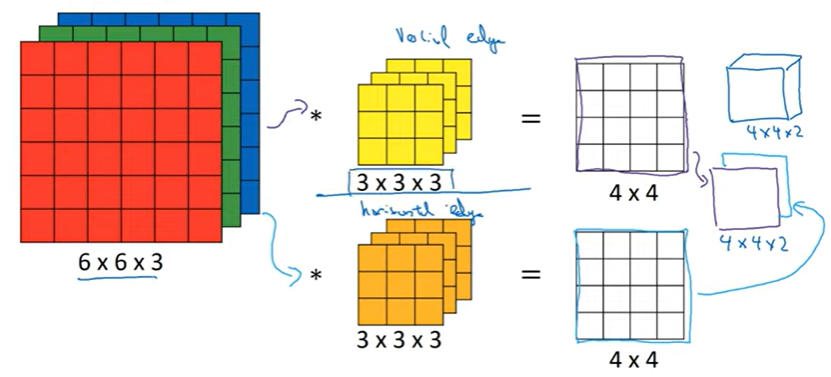
첫 번째: 세로 두 번째: 가로
두개를 쌓아서 4x4x2로 입체형 상자
One Layer of a Convolutional Net
편향을 더해주고 ReLU 적용한다.
ReLU는 비선형성 적용
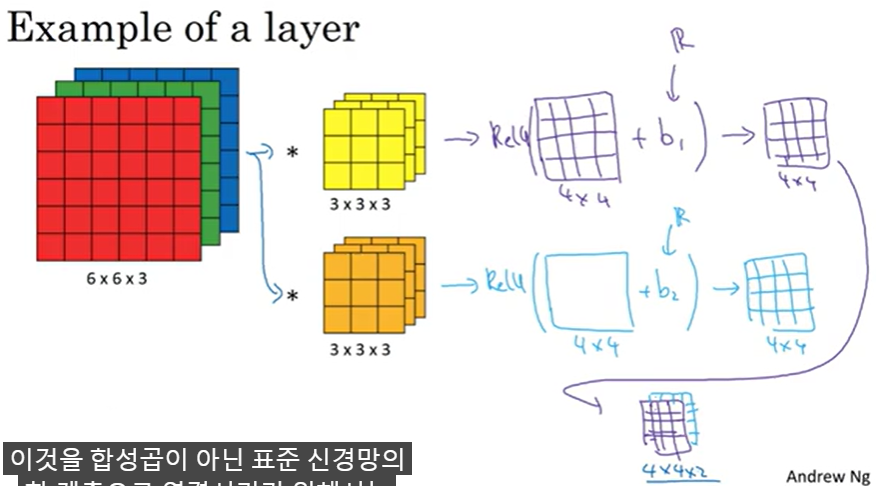
합성곱 신경망의 한 계층이 된다
필터는 27개의 변수를 가진다. 여기서 편향을 더해줘야 한다. 이렇게 해서 28개의 변수를 가지게 된다.
10개의 필터가 있다면 280개의 변수를 가지게 된다. 아주 큰 이미지라도 작은 변수를 이용할 수 있다. 과적합을 막는다.

Simple Convolution Network Example
Consolution
Pooling
Filly connnected
Pooling Layers
Max Pooling
구역을 나눠서 거기서 최대값을 뽑아간다.
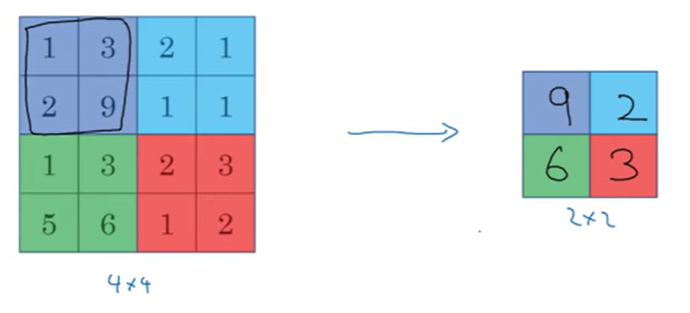 스트라이드 2 적용
스트라이드 2 적용
큰 수가 특성을 표현한다. 특성이 필터의 한 부분에서 검출되면 높은 값을 남기고 특성이 검출되지 않고 오른쪽 위 사분면에 존재하지 않으면 최대값은 작은 수로 남게 된다.
성능이 좋고 직관적이다.
여러 하이퍼 파라미터가 있지만 학습할 수는 없다.
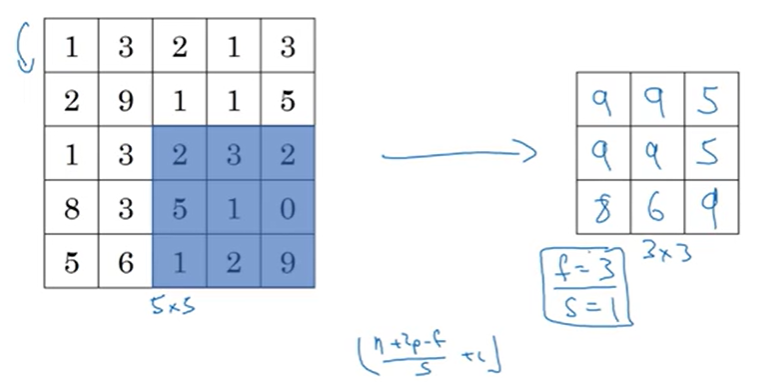
필터의 채널 수가 2개라면 결과도 2개 나오게 된다. 채널의 수가 같게 나온다.
average pooling
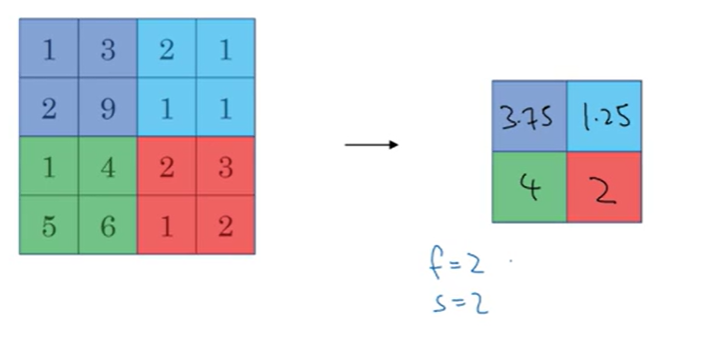
잘 사용하지는 않는다
Why Convolutions
변수 공유
세로 윤곽선 검출기 같은 속성 검출기 관찰로 탄생했다. 이미지 한 부분에 유용한 것이 다른 부분에도 유용할 것이다희소 연결
상대적으로 적은 변수를 가지는 이유이다.
Classic Network
LeNet-5
흑백 이미지 학습으로 32x32x1 이 당시는 평균 풀링을 사용하고 패딩을 사용하지 않아서 크기가 계속 줄어들었다.
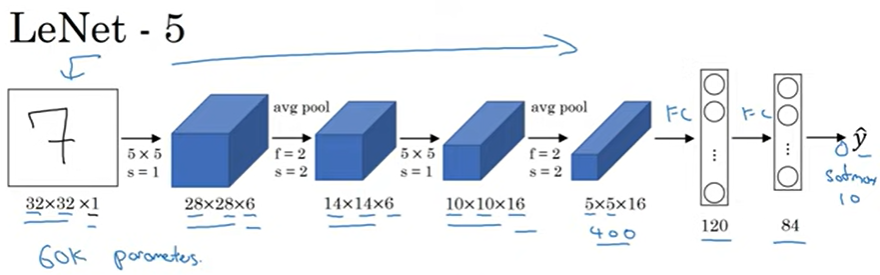
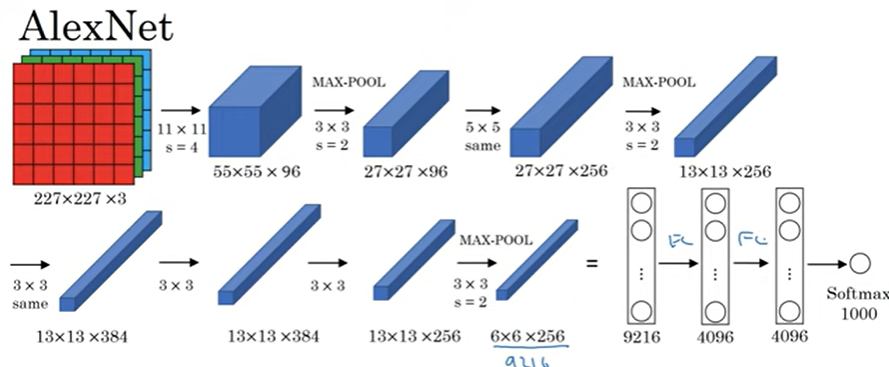
AlexNet
leNet과 유사하지만 훨씬 더 크다
6천만개 매개변수
뛰어난 성능
ReLU사용
VGG-16
많은 하이퍼 파라미터를 가지는 대신 합성곱에서 스트라이드가 1인 3x3필터만을 사용해 동일합성곱을 하고 최대 풀링층에서는 2의 스트라이드의 2x2를 사용한다.
간결한 구조
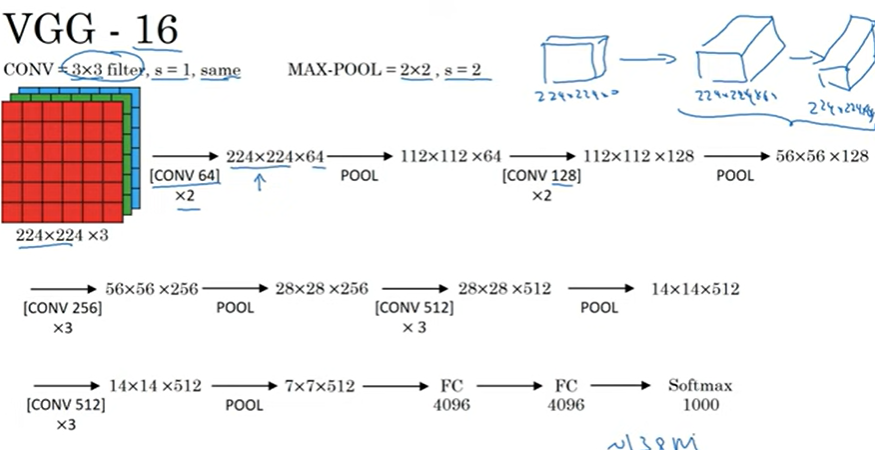
구조적인 장점: 꽤나 균일하다. 풀링층의 높이와 너비를 줄여준다. 필터의 개수를 보면 두배씩 늘어난다. 수치가 커지고 줄어드는 것이 체계적이다.
상대적인 획일성이 가지는 단점은 훈련시킬 변수의 개수가 많아 네트워크의 크기가 커진다.
Resnets
훨씬 깊은 신경망을 학습할 수 있다
plain에서 매우 깊다면 훈련 오류가 높아진다. 하지만 resnet 에서는 성능이 계속 좋아진다.
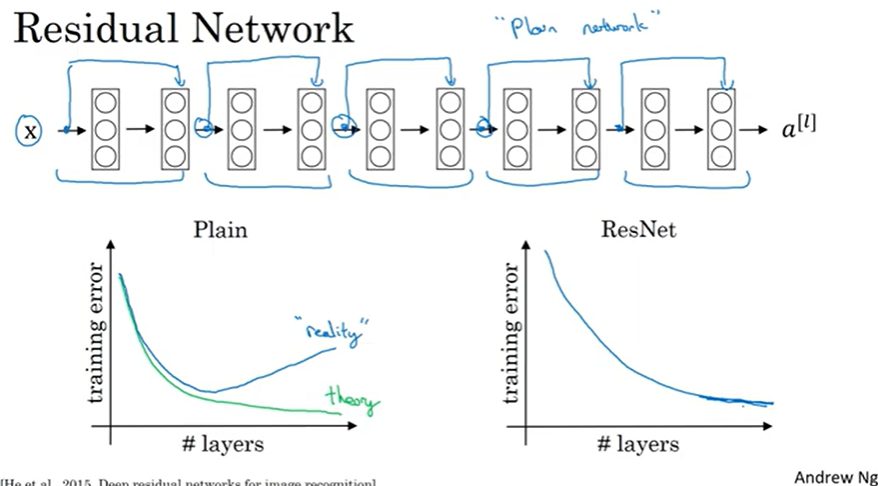
깊은 신경망에서 좋다
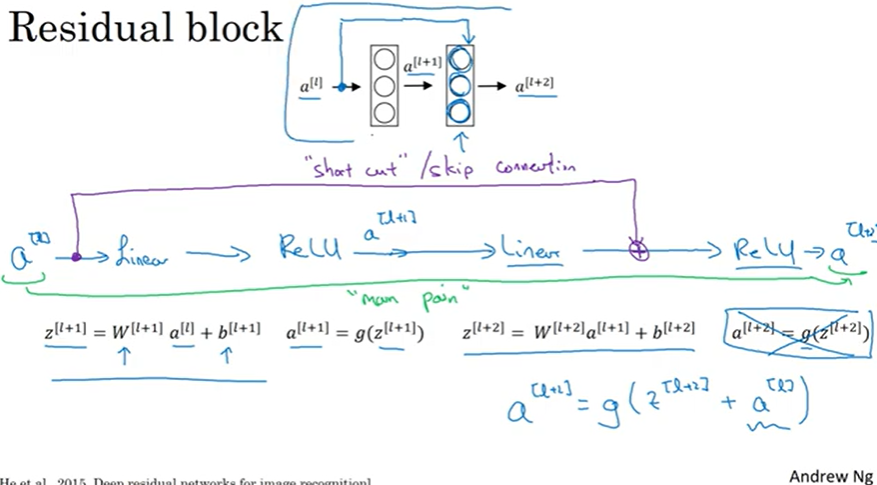
일반적인 신경망에서는 각 층이 새로운 특징을 모두 학습해야 한다. 이전 층에서 받은 정보를 모두 처리해서 새로운 결과를 만들어낸다.
resnet은 스킵 커넥션을 넣어 더 쉽게 학습할 수 있도록 돕는다. 여기서 스킵은 넘어가 학습을 포기하거나 제대로 하지 않는 것이 아니라 이전 층의 입력 값을 그대로 다음 층으로 전달하는 방식이다. 다음 층은 모든 것을 새로 학습할 필요 없이 이전 층의 결과를 바탕으로 필요한 것만 추가적으로 학습한다.
깊은 신경망에서도 효과적으로 학습해 복잡한 이미지 분류 작업에서 뛰어난 성능을 보인다.
Why ResNets Work
추가된 층이 항등 함수를 학습하기 용이하기 때문이다.
스킵 연결을 추가해 resnet으로 만들어준다.
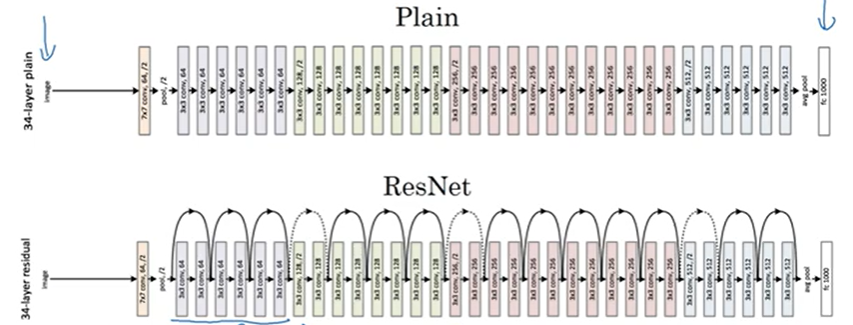
Network In Network
1x1 필터: 합성곱 연산을 하게 되면 이미지에 2만큼 곱해주는 것이다.
유용해보이지 않는다. 하짐나
6x6x32라면 의미있게 된다. 36개 위치를 살펴보고 32개 숫자를 필터 수와 곱해준다. 하나의 위치에 존재하게 되고 하나의 수만 남게 된다.
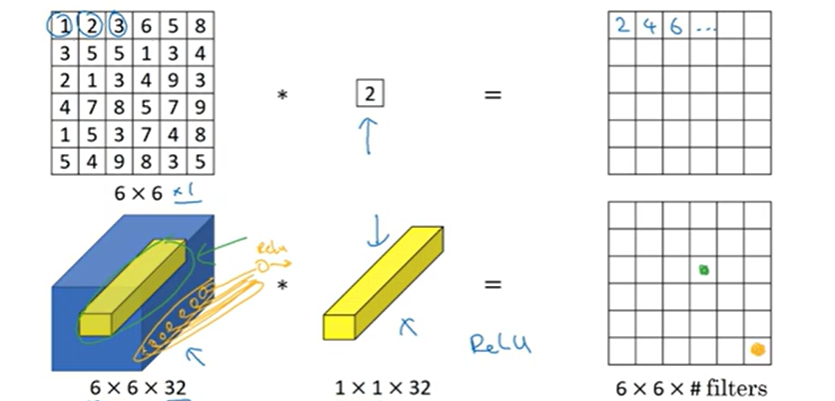
채널 수가 너무 많다면? 1x1필터를 사용하면 된다. 비선형성을 더해주고 채널의 수를 조절할 수 있게 된다. 인셉션 신경망 설계에 도움을 준다.
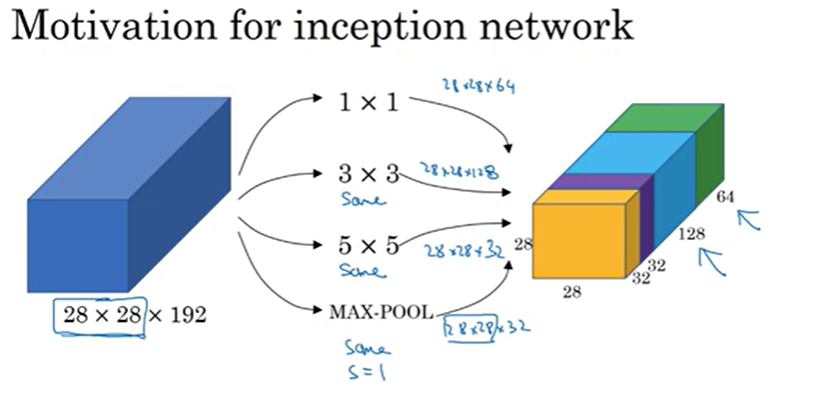
Inception Netork Motivation
필터의 크기를 정하지 않고 합성곱 또는 풀링층을 모두 사용하는 것
여러개를 동시에 계산해보고 결과물을 쌓는 방식
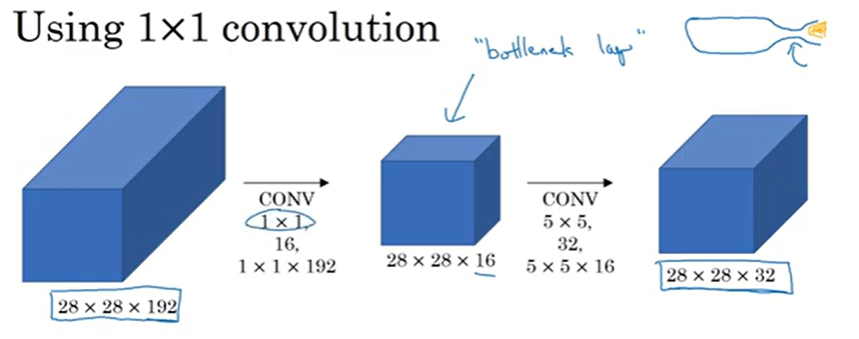
botleneck: 병목층, 가장 작은 부분을 가리킨다. 크기를 다시 늘리기 전에 줄이는 것이다. 계산 비용을 줄일 수 있다.
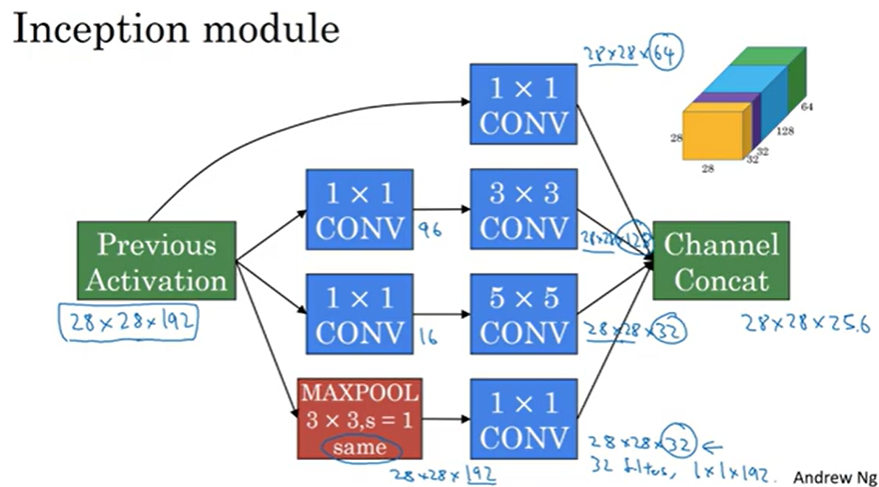
Inception Network
이전층의 출력값을 입력값으로 받는다.
Transfer Learning
어떤 목적을 이루기 위해 학습된 모델을 다른 작업에 이용하는 것
Data Augmentation
적은 양의 데이터를 다양한 알고리즘을 통해 데이터의 양을 늘리는 기술
mirroring, random cropping, rotation, shearing, local wrapping, color shifting