[CV] Week2. Object Detection & Special applications: facial recognition and neural style transfer
Convolutional Neural Networks (Course 4 of the Deep Learning Specialization)
Object Localization
Object Detection 객체 탐지를 위해 먼저 Object Localization을 알아보자.
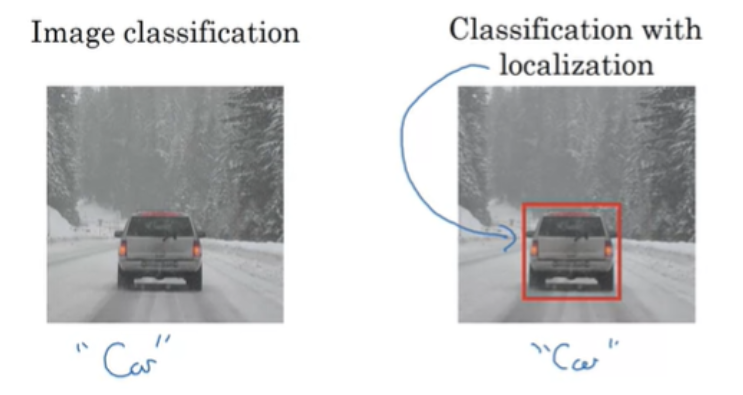
with localization은 자동차라는 것과 더불어 bounding box를 푯한다.
object가 여러개면 모든 object를 탐지하고 위치도 알아내야 한다. 자율주행에서 다른 자동차, 보행자, 오토바이, 다른 물건들도 탐지해야 한다.
classification with localization을 좀 더 자세하게 알아보자. 여러 layer로 이루어진 ConvNet에 이미지를 입력해서 softmax unit 이라는 output vactor로 class를 예측할 수 있다.
Convnet(CNN)
수십 수백개의 계층을 가질 수 있으며 각 계층은 영상의 서로 다른 특징을 뽑아낸다.
Softmax
입력받은 값을 출력으로 0~1사이의 값으로 모두 정규화하며 출력 값들의 총합은 항상 1이 되는 특성을 가진 함수이다.
다중 클래스 분류 문제에서 주로 사용되며, 각 클래스에 대한 확률을 계산한다.
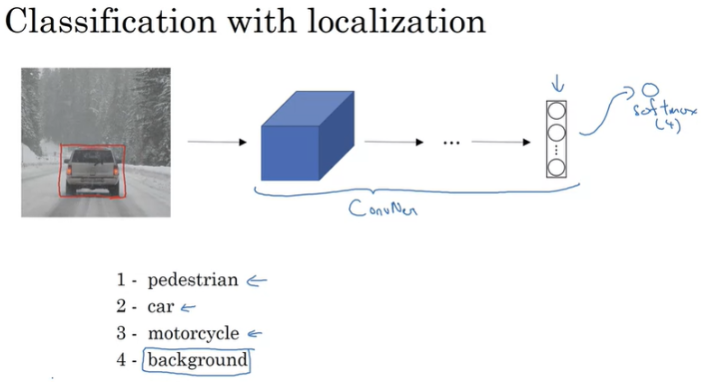
class 4개, softmax unit 4개
자동차의 위치를 알고싶다면?
bounding Box의 위치를 나타내는 output을 갖도록 neural network를 변경한다.
bounding box의 중앙 좌표( bx , by )와 폭( bw ) 그리고 높이( bh )에 의해서 위치를 탐지하게 된다.
pc는 이미지에 ibject가 존재하는지에 대한 확률이고 bx , by , bw, bh는 bounding box의 위치 정보, 나머지 c1, c2, c3는 각 클래스일 확률이다.
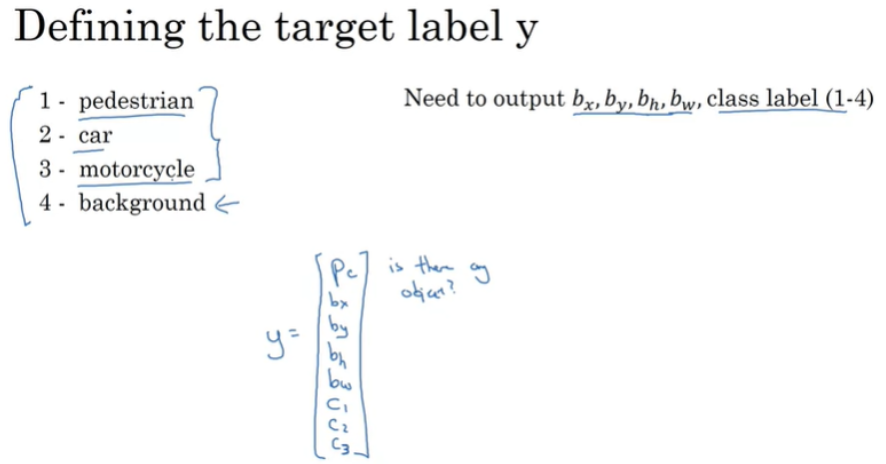
만약 이미지에 object가 없다면? pc 는 0이고 나머지 정보는 don’t care로 푯된다.
손실함수 (loss function)에 대해 알아보자. 기본 true label은 y, 신경망을 통해 나온 pred label은 y햇이다.
MSE를 사용한다면 다음과 같다. 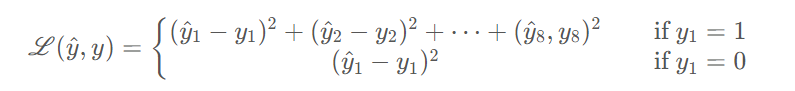
pc가 0이라면 두번째 줄로 계산한다.
c1, c2, c3는 log-likelihood loss와 softmax를 사용하고 bounding box 정보에는 MSE를 사용한다. pc는 logistic regression loss를 사용할 수도 있다.
Landmark Detection
신경망에서 이미지의 주요 포인트를 x와 y의 좌표로 나타낼 수 있다.

눈 코너 부분 인식을 위해 x,y 좌표를 가질 수 있을 것읻.
입을 따라 landmark를 푯하면 입 모양을 찾아내서 웃고 있는지 인상을 쓰고 있는지 파악할 수 있다.
얼굴에 64개의 랜드마크가 있다면 이 모든 것을 포함하는 training set의 label을 만들어 얼굴 주요 랜드마크가 어디에 있는지 학습시킬 수 있다.
output으로 얼굴인지 아닌지에 대한 정보와 랜드 마크의 위치 정보 128개. 총 129개의 output을 가질 수 있따. 이렇게 감정을 인식할 수 있게 한다.
포즈 감지 알고리즘에서는 어깨, 팔꿈치, 팔목 등 랜드마크를 정의할 수 있다.
랜드마크는 일관성 있어야 한다. landmark 1이 언제나 왼쪽 눈 코너 부분, landmark4는 항상 오른쪽 눈 코너 부분을 가리켜야 한다는 것이다.
Object Detection
Sliding Windows Detection 알고리즘을 사용해서 Object Detection을 위해 ConvNet을 사용할 수 있다.
자동차 감지 알고리즘에서 input x, output y로 label돈 training set을 만들 수 있다.

output y를 출력하게 된다.
특정 사이즈의 window를 골라 탐색을 시작한다.

직사각형에 이미지를 ConvNet입력으로 해서 안에 자동차가 있는지 없는지 확인한다. 박스를 옆쪽으로 옮기고 다시 자동차가 있는지 없는지 확인한다.
이렇게 sliding window 알고리즘은 빨간 사각형이 포함하는 이미지 영역을 가져와 convNet으로 수행하는 작업을 반복한다. 위치할 수 있는 모든 위치에서 확인할 수 있도록 계속 반복한다. 속도를 빠르게 하려면 strides를 더 크게 해서 수행할 수도 있다. 물론 정확도는 떨어질 것이다.
그리고 더 큰 box를 사용해서 작업을 반복한다.
이 알고리즘의 단점은 computation cost이다. 이미지에서 많은 box영역들을 추출해 convNet으로 각각 독립적으로 확인하기 때문이다. 만약 아주 큰 stride를 사용하면 영역이 줄어 빨라지겠지만 성능이 안좋아 질 것이다.
- sliding box는 느리다.
- 매우 작은 stride를 사용하지 않는 한 object의 정확한 위치를 감지하는 것이 불가능하다.
Convolutional Implementation of Sliding Windows
sliding window가 매우 느리다고 했다. 이 알고리즘을 어떻게 convolutional하고 실행할 수 있도록 FC(full connected) layer를 Convolutional Layer로 튜닝하는 것을 알아보자.
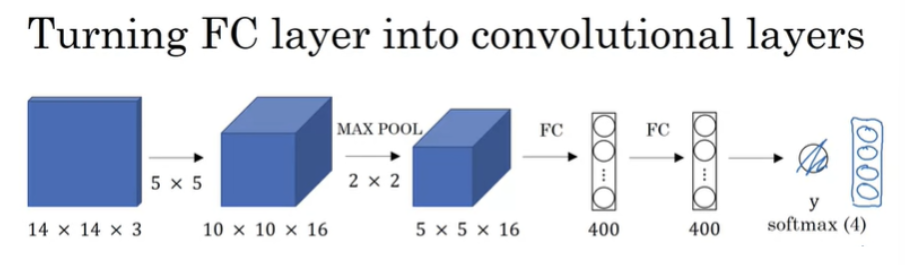
object를 분류하기 위한 모델이다. 위 모델에서 FC를 400개의 5x5 filter로 튜닝해서 convolve를 시킨다.
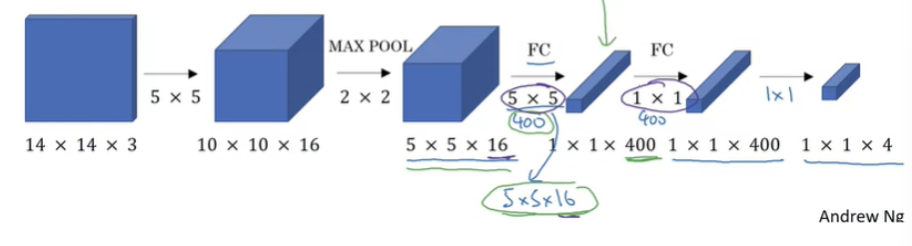
14x14x3 input을 convNet에 통과해 1x1x4결과를 얻었다. 만약 16x16x3으 input을 입력으로 사용한다면?
2x2x4 output이 나오게 된다. 1x1x4 output이 총 4개 나오는 것이다. 튜닝을 통해 독립적인 input으로 계산하는 것이 아닌 4개의 input을 하나의 계산으로 결합해서 공통되는 부분을 공유하게 된다.
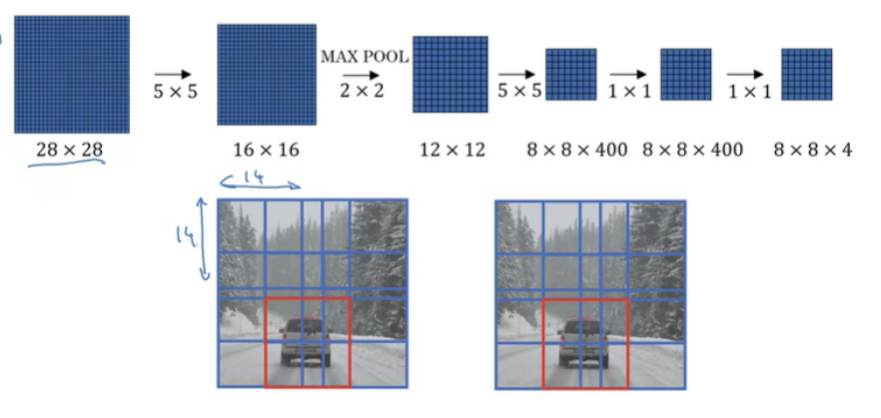
18x18x3 이미지를 보자. 기준 box 크기가 14x14이기 때문에 28x28x3 이미지에 sliding window를 적용해면 8x8개의 독립적인 input이 생긴다. 튜닝한 ConvNet을 사용하면 공통되는 연산 부분을 공유하게 되고 output으로 8x8x4 결과를 얻는다.
Bounding Box Predictions
box에 object 일부만 걸치는 문제가 있을 수도 있고 object가 정사각형의 bounding box를 가지지 않을 수도 있다.
정확하게 가져오려면 YOLO(You only look once)를 사용하자
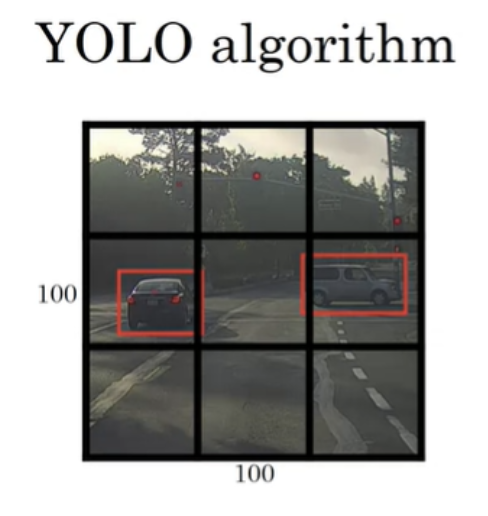
3x3 grid를 설정한다.
YOLO는 Image Classification과 Image Localization을 9개의 그리드에 각각 적용한다.
training set 처럼 label를 정의해준다. 9개의 그리드 셀에 대하여 label y 를 설정한다. object 중간점을 취해서 중간점을 포함하는 그리드 셀에 object를 할당한다.
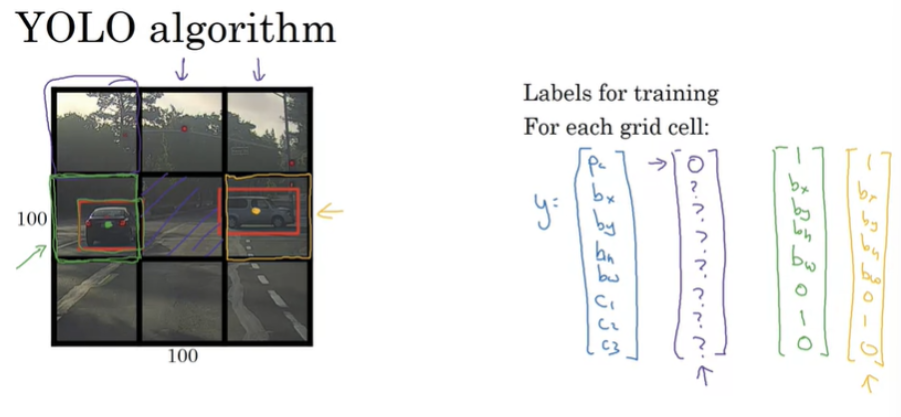
보라색으로 표시된 셀은 object가 없기에 pc가 0이 되고 나머지 요소들은 don’t care가 된다. 초록색은 차가 있다. 차 중간점이 포함되기 때문에 위에 초록색 행렬처럼 labeling 된다. 노란색도 마찬가지다. 3x3 그리드 구역이고 8차원의 벡터를 가지고 있기 때문에 output은 3x3x8형태를 지닌다.
input 100x100x3을 Conv와 MaxPool을 거쳐 3x3x8 output이 나온다. 보통 19x19그리드를 사용한다. 19x19로 하나의 셀에 mid point 가 두 개 될 확률을 줄여준다.
Object Classification/Localization과 Sliding Window Convoluional Implementation을 합친 것이다.
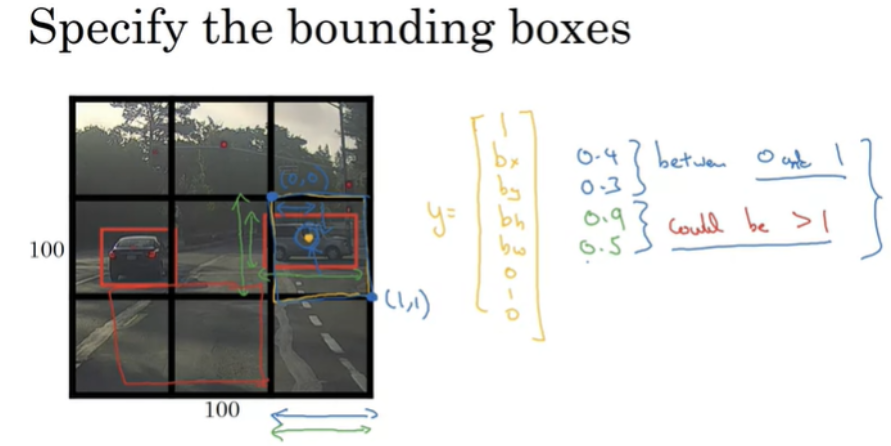
bounding box의 mid point는 (0, 0)과 (1, 1) 사이의 좌표값을 가지기 때문에 항상 0에서 1사이의 값을 가지게 되지만, bounding box의 너비와 높이는 각 cell의 크기를 벗어날 수 있기 때문에 1보다 커질 수 있음에 유의한다.
Intersection over union
object detection이 잘 동작하는지 판단하기 위한 함수이다. 알고리즘을 평가할 때나 더 잘 동작되도록 하기 위해 사용된다.
보라색 박스와 빨간색 박스의 intersection over union(IoU)를 계산한다.

0.5보다 값이 크면 결과가 옳고 합리적이라고 판단한다. 완벽하게 일치하면 1이 된다. 기준을 높일 수도 있다.
None-max Suppression

mid point가 다앙한 cell에서 포함된다고 판단될 수 있다. none-max suppression을 사용하면 하나의 cell에서 한번만 탐지할 수 있도록 해준다
각각 detection과 관련된 확률을 조사한다. pc를 체크한다. 실제 알고리즘에서는 c1, c2, c3를 곱한 확률을 의미하지만 여기서는 자동차 class만 판단한다고 가정한다. pc가 가장 큰 것만 취한다. 남은 박스를 가지고 남긴 박스와 IoU를 조사한다.
많이 겹쳐 있다면 그 박스는 제거(suppression)한다. 낮다면 다른 object를 감지했을 가능성이 높아 제거하지 않는다.
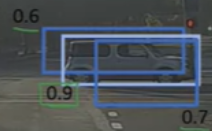
- 각 cell의 output에서 pc를 조사해서 0.6 이하면 제거
- 남은 박스 중에서 가장 높은 pc를 갖는 박스를 예측된 bounding box로 선택
- 남은 box들의 IoU를 예산해서 0.5보다 크다면 같은 object일 확률이 높으므로 제거
자동차, 보행자, 오토바이로 3개의 object를 탐지한다면 non-max suppress를 독립적으로 각각 3회 수행한다.
Anchor box
각 그리드 셀이 하나의 object만 감지할 수 있었다. 이를 해결해보자
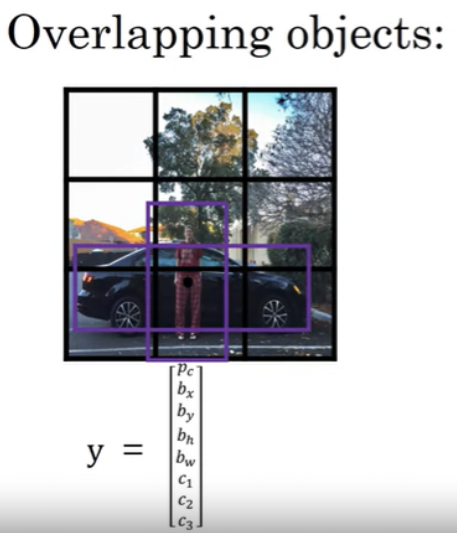
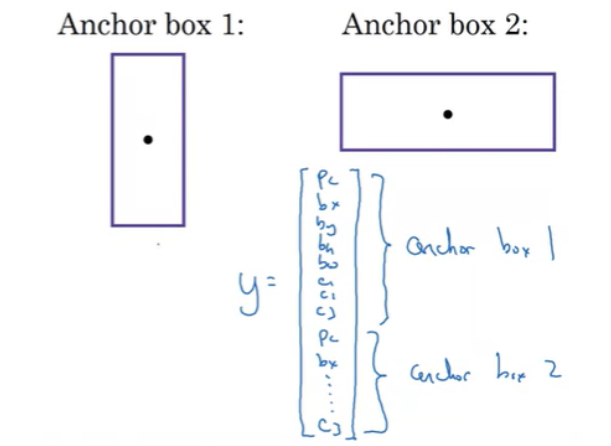
anchor box를 output과 연관시키자
두 개의 anchor box를 사용함을 각 object는 object를 포함하는 grid cell에 할당됨과 동시에 IoU가 가장 높은 Anchor Box에 할당된다.
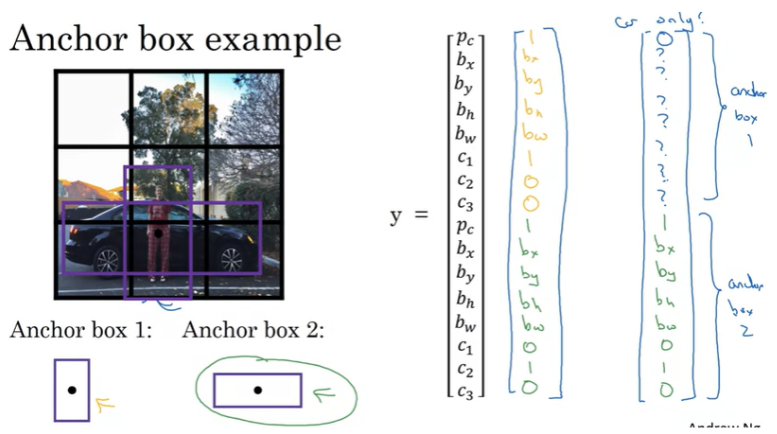
사람이 없다면, Anchor Box 1에 대한 정보에서 pc
는 0이되고, 나머지는 ‘don’t care’가 된다. 그리고 Anchor Box 2의 정보는 그대로 차량의 정보를 가진다.
2개를 사용했는데 3개라면? 제대로 처리하지 못한다. default tirebreaker를 설정해야 한다.
YOLO Algorithm
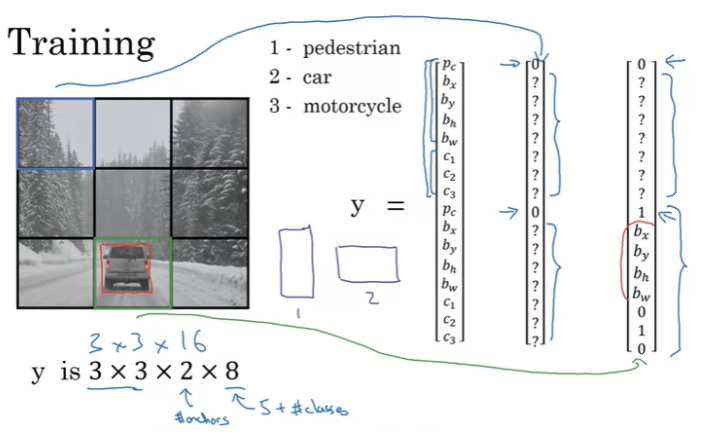
anchor box를 두 개 사용하고 class는 3개로 3x3x2x8 or 3x3x16이다.
여기서 대부분의 grid cell은 object가 존재하지 않기 때문에, 각 anchor box의 pc 는 0이고, 초록색으로 표시된 cell에만 object가 존재한다.
YOLO 알고리즘은 효과적인 Object Detection 알고리즘 중의 하나이다.
Region proposal: R-CNN
Sliding Window 알고리즘을 떠올려보면, window들을 슬라이딩하면서 object를 탐지하는 방법이지만, 많은 구역들을 살펴보는 단점이 있다.
R-CNN은 이렇게 탐지하는 것이 아닌, 이미지로부터 Region 후보군을 뽑아내서 object를 탐지하는 방법이다.
segmentation algorithm을 통해서 여러개로 나누어서 유사한 픽셀들을 뽑아내서 object를 탐지한다

Why is face recognition

face verification: 사람의 이름, id, 이미지가 주어졌을 때 이 사람이 맞는 가에 대한 여부를 확인한다. 1:1문제
face recognition: 1:K 문제로 K명의 데이터 베이스가 있으면 주어진 이미지를 통해서 K명의 뎅터 베이스에 속하는 사람인지를 판단
One Shot Learning
대부분의 얼굴인식 application에서 한 사람을 인식하는데 하나의 이미지만 주어진다.
4명의 직원이 있고 사무실 게이트를 누가 지나간다. 게이트는 각 직원의 사진 하나만 가지고 직원인지 아닌지 인식해야 한다.
다른 방법으로 직원 뎅터 베이스의 이미지를 ConvNet 입력으로 사용해 아웃풋을 출력하게 한다.
이 방법도 잘 되지 않는다. 왜일까? 작은 training set으로 deep neural net work를 훈련시키기에 충분하지 않기 때문이다.
one shot learning 을 잘 수행하는 방법! similarity function 학습하기
이미지의 차이 정도를 output으로 출력하는 similarity function을 학습하는데 이미지가 많이 다르면 값이 크고 유사하면 작다.
Siamese network
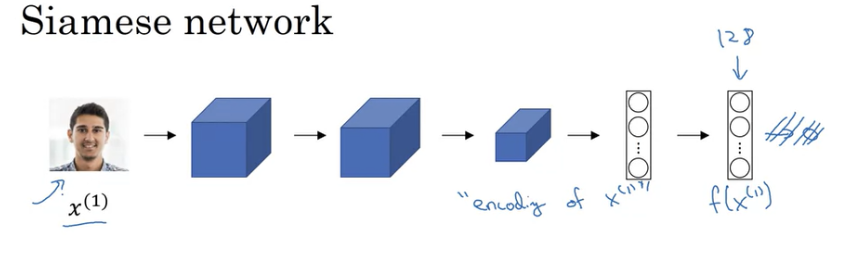
이미지를 입력하면 feature vector로 마무리되고 softmax unit으로 분류한다. feature vector은 fc에 의해 계산되었다.
두 장의 사진을 동일한 파라미터를 가진 신경망을 통해서 128개의 feature vactor을 각각 얻어서 비교한다. x(1), x(2)를 신경망을 통해서 인코딩된 f(1), f(2)를 얻을 수 있다. x(1), x(2) 사이의 거리 d는 두 이미지의 인코딩된 값 차이를 norm으로 정의할 수 있다.
인코딩된 값을 얻어서 비교하는 것을 simese neural network architecture 라고 한다.
Triplet loss
신경망의 파라미터를 학습해서 얼굴 인식을 위한 좋은 인코딩을 학습하는 방법은 triplet loss function을 적용한 GD를 정의하는 것이다.

triplet loss를 적용하려면 이미지쌍을 서로 비교해야 한다. 동시에 여러 이미지를 살펴봐야 한다. 왼쪽은 인코딩이 유사하고 오른쪽은 차이가 난다.
하나의 Anchor 이미지를 두고, Positive와 Negative와의 사이의 거리를 동시에 살펴본다.
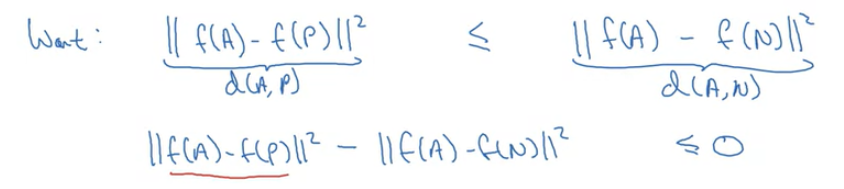
주의해야할 점이 있는데 모든 이미지의 인코딩이 같아지면 안된다. 모든 이미지의 인코딩이 같아진다면, d(A, P)와 d(A, N)이 모두 0이 되어서 위 공식을 항상 만족하게 된다.
위와 같은 상황을 방지하기 위해서 α라는 하이퍼 파라미터를 추가하는데, margin이라고 부르기도 한다.
loss function 이 0보다 작으면 같은 사람이라고 판단하고 0으로 설정한다.
L(A,P,N)=max(∥f(A)−f(P)∥2 −∥f(A)−f(N)∥2 +α,0)
A-P는 같은 사람이고 A-N은 다른 사람인 경우가 있다. 무작위로 고를 때, A-N의 데이터가 매우 많이 뽑힐 확률이 높다. 따라서 training set를 구성할 때는 훈련하기 어려운 A,P,N 중의 하나를 선택하는 것이 중요하다.
같은 사람이지만 d(A,P) 값은 낮고, 다른 사람이지만 d(A,N)의 값이 높은 set로 구성을 한다면 학습에 더욱 도움이 될 것이다.
- triplet loss를 가지고 학습하기 위해 training set에서 a-p와 a-n 쌍을 매핑해야 한다.
- training set을 가지고 cost j를 최소화학 위해 GD를 사용한다.
- 같은 사람일 경우 d가 최소 되고, 다른 사람일 경우 d가 최대가 되도록 최적화된다.
Face Verification and Binary Classification
이미지를 128개의 feature vector로 나타내기 위해서 ConvNet을 통과시켜 embeding(encoding)시키고, 128개의 feature vector를 Logistic Regression을 통해서 예측하도록 한다. 목표 output은 두 이미지가 같다면 1을 출력하고, 다른 사람이라면 0이 된다.
얼굴 인식을 Binary Classification하는 것이다.
database에서 이미지가 입력으로 사용되면 매번 embeding 다시 할 필요 없이 embeding 된 값을 저장해서 예측에 사용할 수 있다. 효율이 높아진다.
What is neura style transfer
![]()
이미지를 새로운 스타일로 변형한다. 원본 이미지와 변형할 스타일을 가지고 새로운 스타일 이미지를 합성한다.
What are deep ConvNets learning?

각 later에서 추출하는 feature들의 시각화를 통해 각 라벨의 unit을 최대로 활성화하는 특징이 무엇인지 파악한다.
shallow layer에서는 명암과 같은 단순한 feature를 출력하고 deep layer로 갈수록 더욱 복잡한 패턴을 감지하기 시작한다.

Cost Function
cost function을 최소화해 원하는 이미지를 생성한다.

J content(C,G)는 Content Cost라고 하며, Jstyle(S, G)는 Style Cost라고 하며, 두 이미지가 얼마나 비슷한지에 대한 Cost이다.

- 이미지 G를 무작위로 초기화해서 백색 노이지의 이미지로 만든다.
- cost function을 통해 gradient descent 를 수행해서 cost function을 최소화하고 G를 업데이트 한다.
이미지 G의 픽셀 값을 업데이트 한다. 학습이 진행된수록 style 로 렌더링된 content이미지를 얻을 수 있다.
Content cost function
layer l을 사용해서 content cost를 계산할때 hidden layer 1을 선택하면 생성된 이미지가 content image 와 매우 비슷한 픽셀값을 가지도록 할 것이다. layer가 깊다면 content와 동떨어진 이미지가 생성될 것이다. 너무 얕지도 깊지도 않은 레이어로 선택해야 한다.
pre-trained ConvNet을 사용해서, content image와 generated image가 주어지면 이 두 이미지가 얼마나 유사한지 측정할 수 있다.
두 activation이 유사하다면 두 이미지가 비슷하다라는 것을 의미한다.
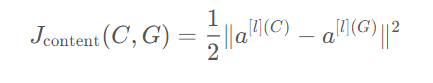
최소화하도록 학습
Style Cost Function
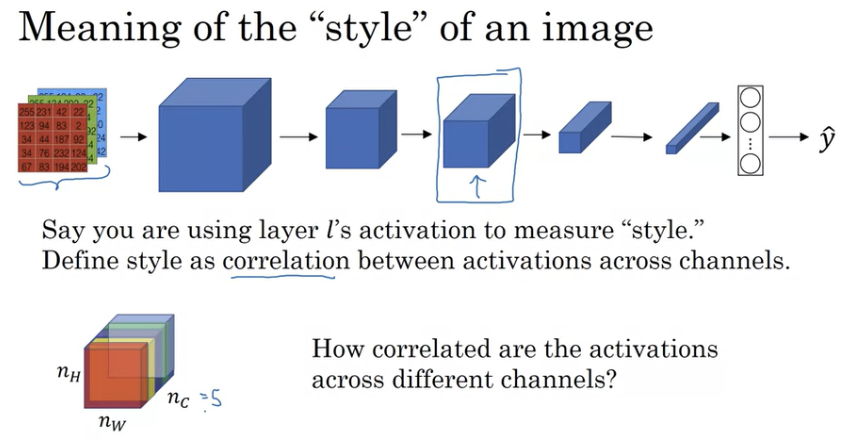
style의 의미! style image 의 측정 방법을 정의하기 위해 layer l을 선택해보자. channel들 사이에서 분포하는 activation 들의 상관관계로 style을 정의할 수 있다.
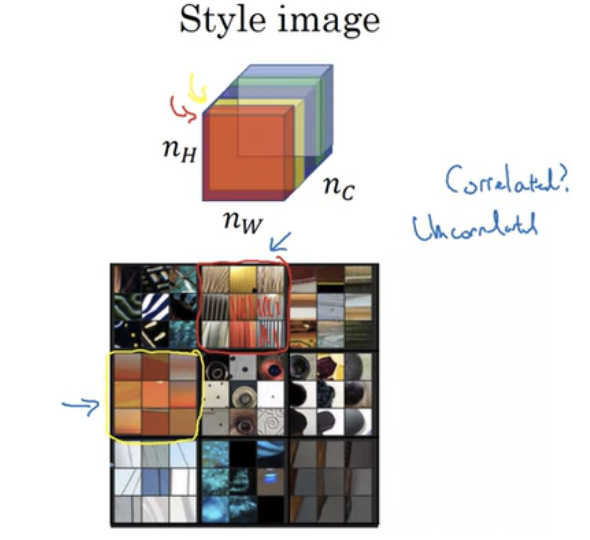
빨간색 채널과 노란색 채널이 있을 때 빨간색 채널은 수직 텍스쳐를 낱내고 노란색 채널은 주황빛 색을 나타낸다. 두 채널 상관관계가 높다면 수직 텍스쳐가 있을 때 주황빛 계열을 가지게 된다는 것이다. 상관관계가 없다면 수직 텍스쳐가 있어도 주황 계열이 아닐 수 있다.
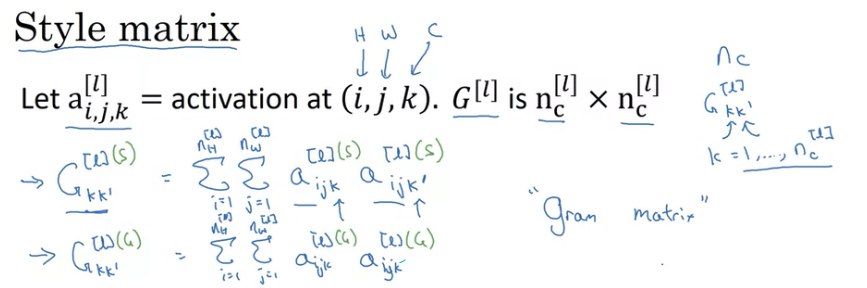
k와 k ′ 의 상관관계 정도를 의미하며 k는 1 ~ nc [ l ] 의 값이다.
